https://mbd.baidu.com/newspage/data/landingsuper?urlext=%7B%22cuid%22%3A%22luBHi_PQvigAP2u2gi2M8juJ2agSi2imlOvi8_aKv8Ku0qqSB%22%7D&rs=4057071921&ruk=8MVN0ObRzpLf_xb_Ge1TDQ&like_icon_type=2&isBdboxFrom=1&pageType=1&sid_for_share=&context=%7B%22nid%22%3A%22news_9578116123318135726%22,%22sourceFrom%22%3A%22bjh%22%7D
机器之心AIxiv专栏发布了PEFT技术综述,该技术旨在提高大型AI模型的微调效率。PEFT通过固定大部分预训练参数并微调极少数参数,使大模型快速适配各种下游任务。综述涵盖了PEFT的背景、分类、高效设计、跨领域应用和系统设计挑战,并指出了未来的研究方向。
摘要由作者通过智能技术生成
用AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
近期,大语言模型、文生图模型等大规模 AI 模型迅猛发展。在这种形势下,如何适应瞬息万变的需求,快速适配大模型至各类下游任务,成为了一个重要的挑战。受限于计算资源,传统的全参
数微调方法可能会显得力不从心,因此需要探索更高效的微调策略。上述挑战催生了参数高效微调(PEFT)技术在近期的快速发展。
为了全面总结 PEFT 技术的发展历程并及时跟进最新的研究进展,最近,来自美国东北大学、加州大学 Riverside 分校、亚利桑那州立大学和纽约大学研究者们调研、整理并总结了参数高效微调(PEFT)技术在大模型上的应用及其发展前景,并总结为一篇全面且前沿的综述。

论文链接:https://arxiv.org/pdf/2403.14608.pdf
PEFT 提供了一个高效的针对预训练模型的下游任务适配手段,其通过固定大部分预训练参数并微调极少数参数,让大模型轻装上阵,迅速适配各种下游任务,让大模型变得不再「巨无霸」。
全文长达 24 页,涵盖了近 250 篇最新文献,刚发布就已经被斯坦福大学、北京大学等机构所引用,并在各平台都有着不小的热度。

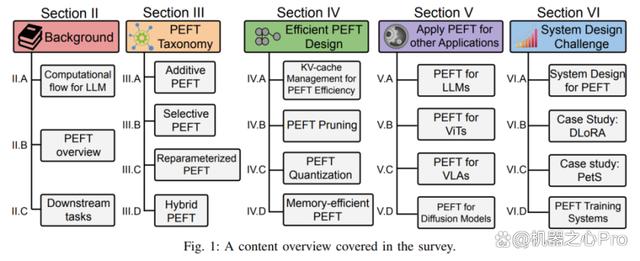
具体来说,该综述分别从 PEFT 算法分类,高效 PEFT 设计,PEFT 跨领域应用,以及 PEFT 系统设计部署四大层面,对 PEFT 的发展历程及其最新进展进行了全面且细致的阐述。无论是作为相关行业从业者,或是大模型微调领域的初学者,该综述均可以充当一个全面的学习指南。
1、PEFT 背景介绍
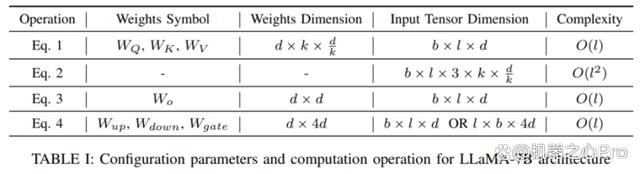
论文首先以最近大热的 LLaMA 模型作为代表,分析并阐述了大语言模型(LLM)和其他基于 Transformer 的模型的架构和计算流程,并定义了所需的符号表示,以便于在后文分析各类 PEFT 技术。
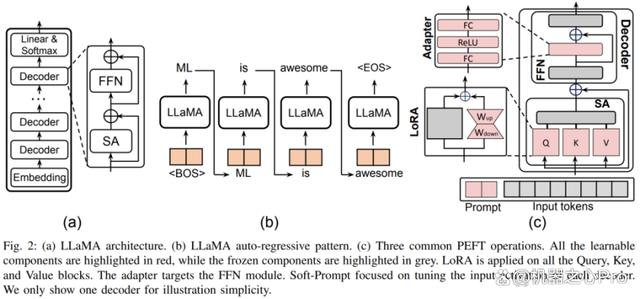
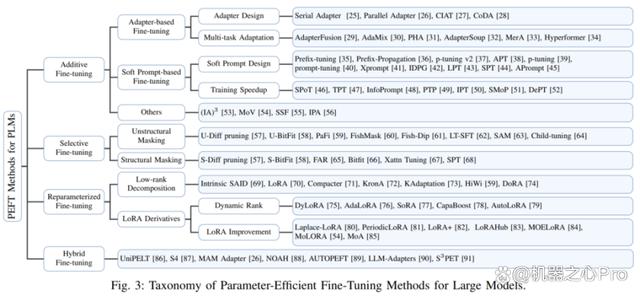
此外,作者还概述了 PEFT 算法的分类方法。作者根据不同的操作将 PEFT 算法划分为加性微调、选择性微调、重参数化微调和混合微调。图三展示了 PEFT 算法的分类及各分类下包含的具体算法名称。各分类的具体定义将在后文详细讲解。
在背景部分,作者还介绍了验证 PEFT 方法性能所使用的常见下游基准测试和数据集,便于读者熟悉常见的任务设置。
2、PEFT 方法分类
作者首先给出了加性微调、选择性微调、重参数化微调和混合微调的定义:
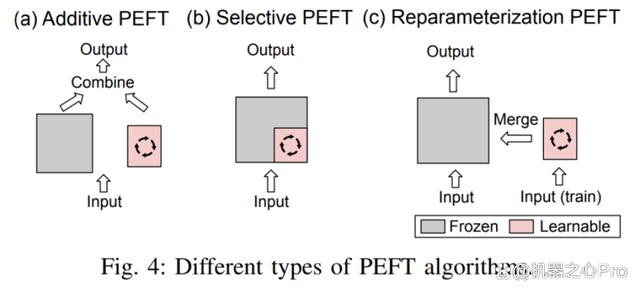
加性微调通过在预训练模型的特定位置添加可学习的模块或参数,以最小化适配下游任务时模型的可训练的参数量。
选择性微调在微调过程中只更新模型中的一部分参数,而保持其余参数固定。相较于加性微调,选择性微调无需更改预训练模型的架构。
重参数化微调通过构建预训练模型参数的(低秩的)表示形式用于训练。在推理时,参数将被等价的转化为预训练模型参数结构,以避免引入额外的推理延迟。
这三者的区分如图四所示:
混合微调结合了各类 PEFT 方法的优势,并通过分析不同方法的相似性以构建一个统一的 PEFT 架构,或寻找最优的 PEFT 超参数。
接下来,作者对每个 PEFT 种类进一步细分:
A. 加性微调:
1)Adapter
Adapter 通过在 Transformer 块内添加小型 Adapter 层,实现了参数高效微调。每个 Adapter 层包含一个下投影矩阵、一个激活函数,和一个上投影矩阵。下投影矩阵将输入特征映射到瓶颈维度 r,上投影矩阵将瓶颈特征映射回原始维度 d。
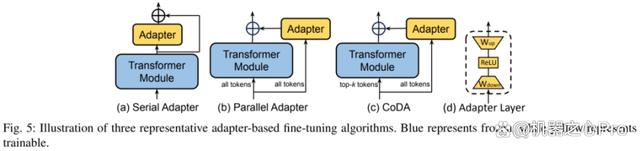
图五展示了三种典型的 Adapter 层在模型中的插入策略。Serial Adapter 顺序地插入到 Transformer 模块之后,Parallel Adapter 则并行地插入到 Transformer 模块旁。CoDA 是一种稀疏的 Adapter 方式,对于重要的 token,CoDA 同时利用预训练 Transformer 模块和 Adapter 分支进行推理;而对于不重要的 token,CoDA 则仅使用 Adapter 分支进行推理,以节省计算开销。
2)Soft Prompt
Soft Prompt 通过在输入序列的头部添加可学习的向量,以实现参数高效微调。代表性方法包括 Prefix-tuning 和 Prompt Tuning。Prefix-tuning 通过在每个 Transformer 层的键、值和查询矩阵前面添加可学习的向量,实现对模型表示的微调。Prompt Tuning 仅仅在首个词向量层插入可学习向量,以进一步减少训练参数。
3)Others
除了上述两种分类,还有一些 PEFT 方法同样也是在训练过程引入新的参数。
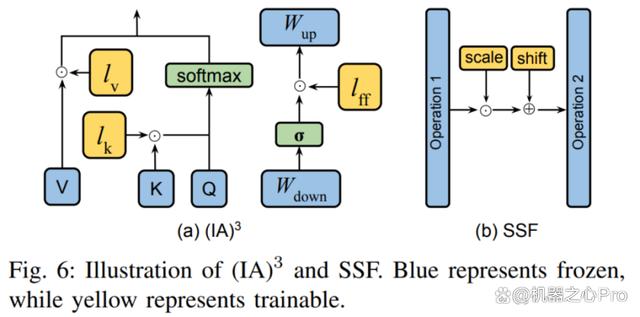
典型的两种方法如图六所示。(IA) 3 引入了三个缩放向量,用于调整键、值以及前馈网络的激活值。SSF 则通过线性变换来调整模型的激活值。在每一步操作之后,SSF 都会添加一个 SSF-ADA 层,以实现激活值的缩放和平移。
B. 选择性微调:
1)非结构化掩码
这类方法通过在模型参数上添加可学习的二值掩码来确定可以微调的参数。许多工作,如 Diff pruning、FishMask 和 LT-SFT 等,都专注于计算掩码的位置。
2)结构化掩码
非结构化掩码对于掩码的形状没有限制,但这就导致了其影响效率低下。因此,一些工作,如 FAR、S-Bitfit、Xattn Tuning 等均对掩码的形状进行了结构化的限制。两者的区别如下图所示:
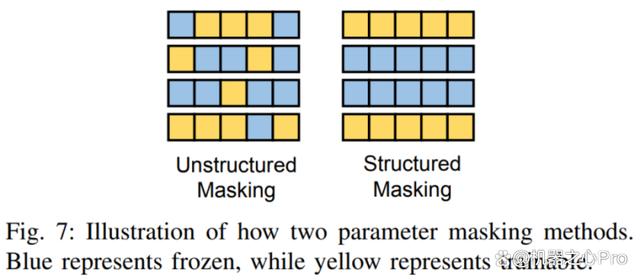
C. 重参数化微调:
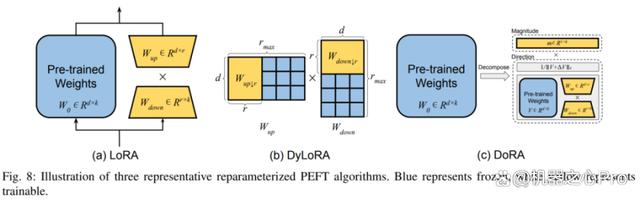
1)低秩分解
这类方法通过寻找预训练权重矩阵的各种低维度重参数化形式,以代表整个参数空间进行微调。其中最为典型的方法为 LoRA,它通过添加两个额外的上投影和下投影矩阵来构建原始模型参数的低秩表示用于训练。在训练后,额外引入的参数还可以被无缝的合并到预训练权重中,避免引入额外推理开销。DoRA 将权重矩阵解耦为模长和方向,并利用 LoRA 来微调方向矩阵。
2)LoRA 衍生方法
作者将 LoRA 的衍生方法分为了动态选择 LoRA 的秩以及 LoRA 在各方面的提升。
LoRA 动态秩中,典型方法为 DyLoRA,其构造了一系列秩,用于在训练过程中同时训练,从而减少了用于寻找最优秩所耗费的资源。
LoRA 提升中,作者罗列了传统 LoRA 在各个方面的缺陷以及对应的解决方案。
D. 混合微调:
这部分研究如何将不同 PEFT 技术融合进统一模型,并寻找一个最优的设计模式。此外,也介绍了一些采用神经架构搜索(NAS)用以得到最优 PEFT 训练超参数的方案。
3、高效 PEFT 设计

这部分,作者探讨了提升 PEFT 效率的研究,重点关注其训练和推理的延迟和峰值内存开销。作者主要通过三个角度来描述如何提升 PEFT 的效率。分别是:
PEFT 剪枝策略:即将神经网络剪枝技术和 PEFT 技术结合,以进一步提升效率。代表工作有 AdapterDrop、SparseAdapter 等。
PEFT 量化策略:即通过降低模型精度来减少模型大小,从而提高计算效率。在与 PEFT 结合时,其主要难点是如何更好的兼顾预训练权重以及新增的 PEFT 模块的量化处理。代表工作有 QLoRA、LoftQ 等。
内存高效的 PEFT 设计:尽管 PEFT 能够在训练过程中只更新少量参数,但是由于需要进行梯度计算和反向传播,其内存占用仍然较大。为了应对这一挑战,一些方法试图通过绕过预训练权重内部的梯度计算来减少内存开销,比如 Side-Tuning 和 LST 等。同时,另一些方法则尝试避免在 LLM 内部进行反向传播,以解决这一问题,例如 HyperTuning、MeZO 等。
4、PEFT 的跨领域应用
在这一章中,作者探讨了 PEFT 在不同领域的应用,并就如何设计更优的 PEFT 方法以提升特定模型或任务的性能进行了讨论。本节主要围绕着各种大型预训练模型展开,包括 LLM、视觉 Transformer(ViT)、视觉文本模型以及扩散模型,并详细描述了 PEFT 在这些预训练模型的下游任务适配中的作用。
在 LLM 方面,作者介绍了如何利用 PEFT 微调 LLM 以接受视觉指令输入,代表性工作如 LLaMA-Adapter。此外,作者还探讨了 PEFT 在 LLM 持续学习中的应用,并提及了如何通过 PEFT 微调 LLM 来扩展其上下文窗口。
针对 ViT,作者分别描述了如何利用 PEFT 技术使其适配下游图像识别任务,以及如何利用 PEFT 赋予 ViT 视频识别能力。
在视觉文本模型方面,作者针对开放集图像分类任务,介绍了许多应用 PEFT 微调视觉文本模型的工作。
对于扩散模型,作者识别了两个常见场景:如何添加除文本外的额外输入,以及如何实现个性化生成,并分别描述了 PEFT 在这两类任务中的应用。
5、PEFT 的系统设计挑战
在这一章中,作者首先描述了基于云服务的 PEFT 系统所面临的挑战。主要包括以下几点:
集中式 PEFT 查询服务:在这种模式下,云服务器存储着单个 LLM 模型副本和多个 PEFT 模块。根据不同 PEFT 查询的任务需求,云服务器会选择相应的 PEFT 模块并将其与 LLM 模型集成。
分布式 PEFT 查询服务:在这种模式下,LLM 模型存储在云服务器上,而 PEFT 权重和数据集存储在用户设备上。用户设备使用 PEFT 方法对 LLM 模型进行微调,然后将微调后的 PEFT 权重和数据集上传到云服务器。
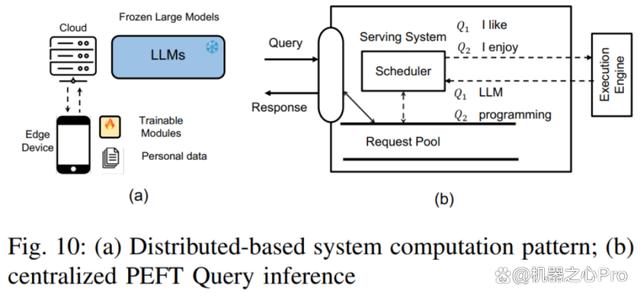
多 PEFT 训练:挑战包括如何管理内存梯度和模型权重存储,以及如何设计一个有效的内核来批量训练 PEFT 等。
针对上述系统设计挑战,作者又列举了三个详细的系统设计案例,以更深入的分析这些挑战与其可行的解决策略。
Offsite-Tuning:主要解决微调 LLM 时出现的数据隐私困境以及大量资源消耗的问题。
PetS:提供了一个统一的服务框架,针对 PEFT 模块提供统一的管理和调度机制。
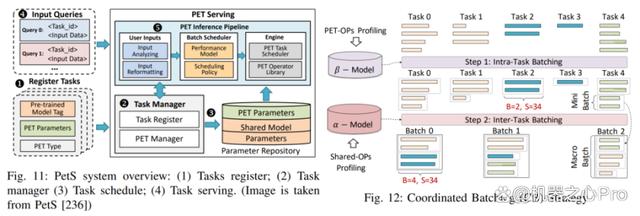
PEFT 并行训练框架:介绍了两种并行 PEFT 训练框架,包括 S-LoRA 和 Punica,以及他们如何提升 PEFT 的训练效率。
6、未来研究方向
作者认为,尽管 PEFT 技术已经在很多下游任务取得了成功,但仍有一些不足需要在未来的工作中加以解决。
建立统一的评测基准:尽管已存在一些 PEFT 库,但缺乏一个全面的基准来公平比较不同 PEFT 方法的效果和效率。建立一个公认的基准将促进社区内的创新和合作。
增强训练效率:PEFT 在训练过程中,其可训练参数量并不总是与训练过程中的计算和内存节省一致。如高效 PEFT 设计章节所述,未来的研究可以进一步探索优化内存和计算效率的方法。
探索扩展定律:许多 PEFT 技术都是在较小的 Transformer 模型上实现的,而其有效性不一定适用于如今的各种大参数量模型。未来的研究可以探索如何适应大型模型的 PEFT 方法。
服务更多模型和任务:随着更多大型模型的出现,如 Sora、Mamba 等,PEFT 技术可以解锁新的应用场景。未来的研究可以关注为特定模型和任务设计 PEFT 方法。
增强数据隐私:在服务或微调个性化 PEFT 模块时,中心化系统可能面临数据隐私问题。未来的研究可以探索加密协议来保护个人数据和中间训练 / 推理结果。
PEFT 与模型压缩:模型压缩技术如剪枝和量化对 PEFT 方法的影响尚未得到充分研究。未来的研究可以关注压缩后的模型如何适应 PEFT 方法的性能。
