原文链接:https://mp.weixin.qq.com/s/Fd_G1M3y6N0DoEytUrRDzA
原创 kol AI科研技术派
重磅!小样本学习取得新突破,登上Nature!中科大提出了一种全新的计算框架:SBeA!克服了少样本学习中,数据集有限导致的问题,实现了无需标记的识别,准确率就超过90%的效果。
实际上,小样本学习一直是重要的研究方向,而且容易发论文!比如:通过预训练好的backbone提取特征,然后接个分类器,提升哪怕1%,就能发论文,这在其他方向,是很难想象的!此外,前面介绍的新计算框架,也是今年发论文的好机会,尤其是面临数据集局限的方向,以往做不了的问题,现在就有发展空间了!
为了让大家能够更好掌握领域前沿创新,我给大家准备了16种创新方法,都来自近一年高引用的顶会文章,并附有代码!
扫描下方二维码,回复「FL16」
免费获取全部论文合集及项目代码

精彩论文赏析
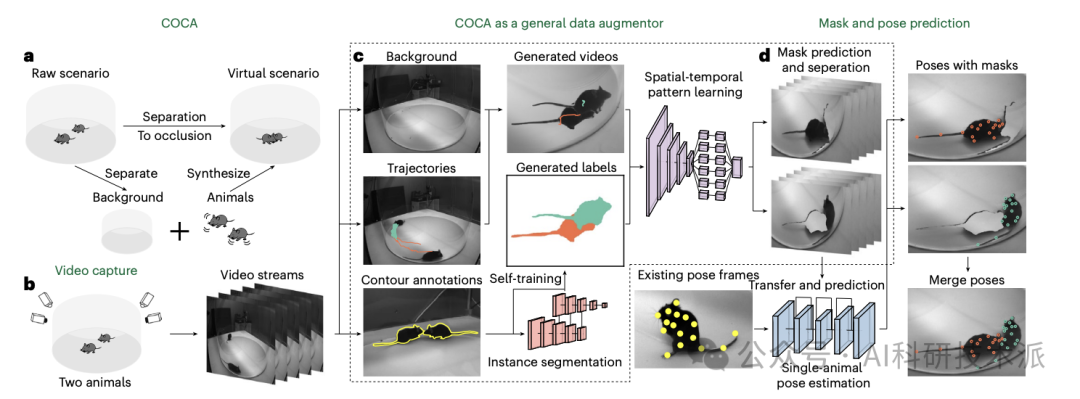
【Nature】Multi-animal 3D social pose estimation, identification and behaviour embedding with a few-shot learning framework
「简述」
动物社会行为的量化是揭示互动阶段大脑功能和精神障碍的重要步骤。虽然基于深度学习的方法已经实现了多动物的精确姿态估计、识别和行为分类,但由于缺乏良好的注释数据集,其应用受到挑战。本文展示了一个计算框架,即社会行为图谱(SBeA),用于克服数据集有限的问题。SBeA使用更少的标记帧进行多动物三维姿态估计,实现了无标签识别,并成功地将无监督动态学习应用于社会行为分类。SBeA被验证为揭示了之前被忽视的自闭症谱系障碍敲除小鼠的社会行为表型。结果还表明,SBeA可以使用现有的定制数据集在各种物种之间实现高性能。这些发现突出了SBeA在神经科学和生态学领域量化微妙社会行为的潜力。
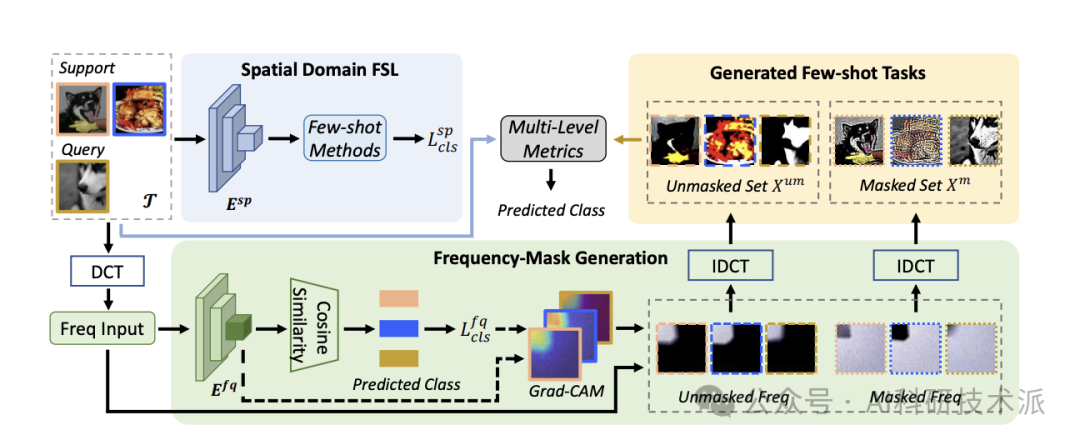
Frequency Guidance Matters in Few-Shot Learning
「简述」
小样本分类旨在学习一种判别性特征表示,以通过少量标记的支持样本识别未见过的类别。虽然大多数小样本学习方法都专注于利用图像样本的空间信息,但频率表示在分类任务中也已被证明是至关重要的。
在本文中,作者研究了不同频率成分对小样本学习任务的影响。为了提高小样本方法的性能和泛化能力,本文提出了一种新的频率引导小样本学习方法框架(称为FGFL),该方法利用特定任务的频率成分来自适应地掩盖相应的图像信息,并采用新颖的多级度量学习策略,包括原始、掩盖和未掩盖图像之间的三元组损失以及掩盖和支持集与查询集之间的对比损失,以利用更多鉴别性信息。
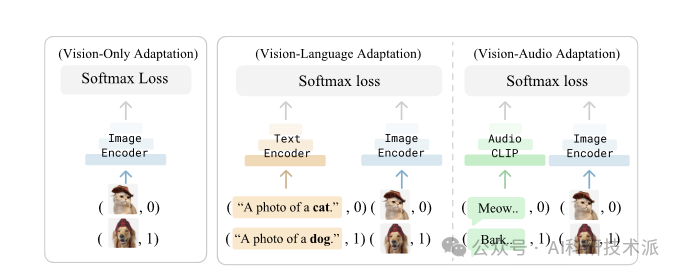
Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models
「简述」
在这项工作中,本文证明了通过阅读关于狗的资料并倾听它们的吠声,确实可以构建一个更好的视觉狗分类器。为此,本文利用了这样一个事实,即最近的多模态基础模型(如CLIP)本质上是跨模态的,将不同的模态映射到相同的表示空间。具体来说,本文提出了一种简单的跨模态适应方法,从跨越不同模态的少数示例中学习。
通过重新使用类名作为额外的一次性训练样本,作者用一个简单的线性视觉语言适应分类器实现了SOTA结果。此外,实验表明我们的方法可以受益于现有的方法,如前缀调优、适配器和分类器集成。最后,为了探索视觉和语言之外的其他模式,作者构建了第一个(据作者所知)视听少数镜头基准,并使用跨模式训练来提高图像和音频分类的性能。
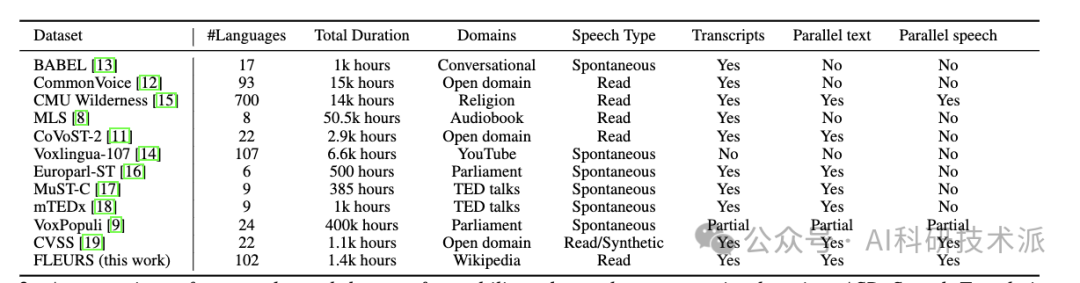
FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech
「简述」
本文介绍了FLEURS,言语普遍表征的少镜头学习评估基准。FLEURS是建立在机器翻译FLoRes-101基准之上的102种语言的n-way并行语音数据,每种语言约有12小时的语音监督。FLEURS可用于各种语音任务,包括自动语音识别(ASR),语音语言识别(语音LangID),翻译和检索。在本文中,本文提供了基于多语言预训练模型(如mSLAM)的任务基线。FLEURS的目标是将语音技术应用于更多的语言,并促进低资源语音理解的研究。
The Unreasonable Effectiveness of Few-shot Learning for Machine Translation
「简述」
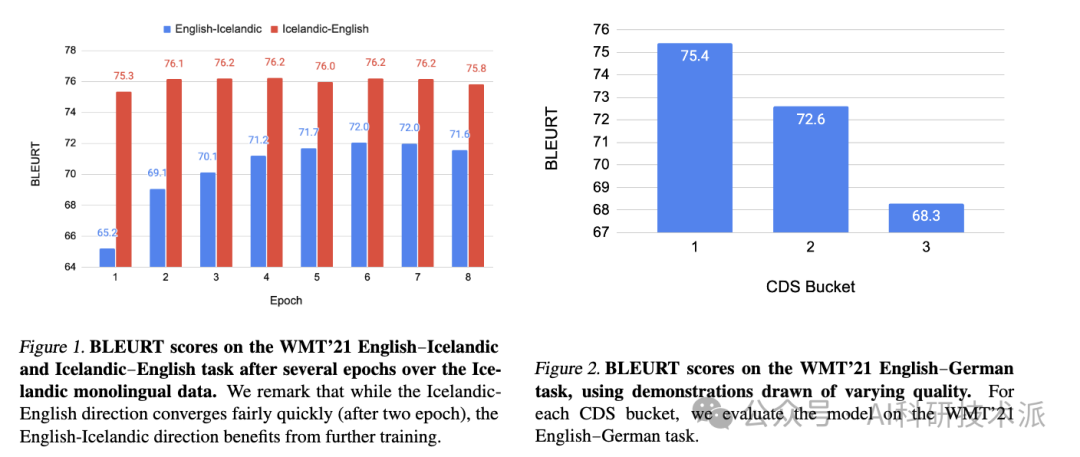
本文展示了用未配对语言数据训练的少镜头翻译系统的潜力,适用于高资源和低资源语言对。作者证明,在推理中仅显示了5个高质量翻译数据的示例,一个仅使用自监督学习训练的转换器解码器模型能够匹配专门的监督最先进的模型以及更通用的商业翻译系统。特别是在WMT’21英汉新闻翻译任务中,作者仅使用5个英汉平行数据进行推理,就超越了表现最好的系统。
此外,本文构建这些模型的方法不需要联合多语言训练或反向翻译,在概念上很简单,并显示出扩展到多语言环境的潜力。此外,生成的模型比最先进的语言模型要小两个数量级。然后,作者分析了影响少镜头翻译系统性能的因素,并强调了少镜头演示的质量在很大程度上决定了我们的模型生成的翻译的质量。
扫描下方二维码,回复「FL16」
免费获取全部论文合集及项目代码
Tuning Language Models as Training Data Generators for Augmentation-Enhanced Few-Shot Learning
「简述」
最近的研究揭示了预训练语言模型(PLMs)有趣的少数次学习能力:当对少量作为提示制定的标记数据进行微调时,它们可以快速适应新任务,而不需要大量的特定任务注释。尽管它们的表现很有希望,但大多数现有的只从小训练集中学习的少数镜头方法在完全监督训练方面仍然表现不佳。
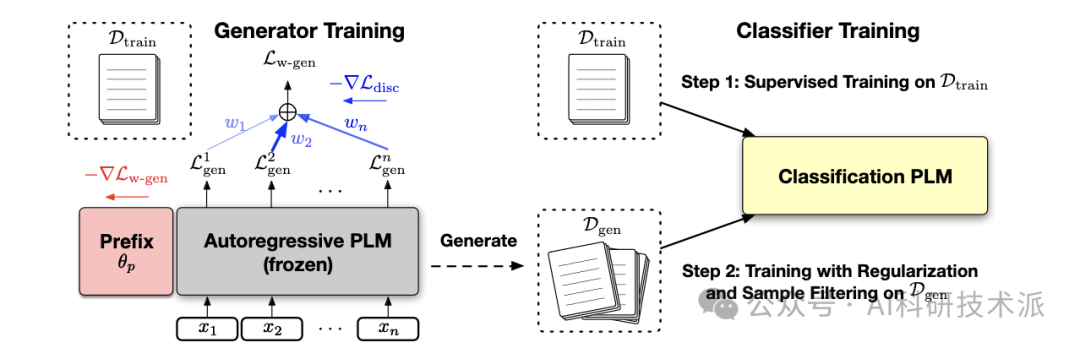
在这项工作中,本文从不同的角度研究了PLM的少镜头学习:首先在少镜头样本上调整一个自回归PLM,然后将其用作生成器来合成大量新的训练样本,以补充原始的训练集。为了鼓励生成器产生标签鉴别样本,作者通过加权最大似然来训练它,其中每个标记的权重根据鉴别元学习目标自动调整。然后,分类PLM可以对具有正则化的少量镜头和合成样本进行微调,以获得更好的泛化和稳定性。
GPr-Net: Geometric Prototypical Network for Point Cloud Few-Shot Learning
「简述」
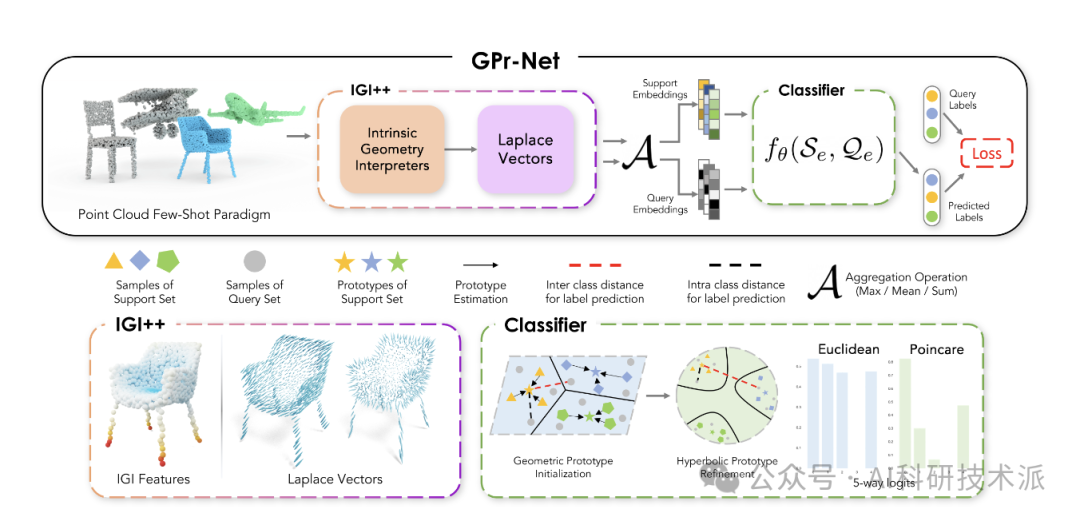
本文提出了gpr - net(几何原型网络),这是一种轻量级且计算效率高的几何原型网络,它可以捕获点云的内在拓扑并获得优越的性能。本文提出的方法IGI++(Intrinsic Geometry Interpreter++)采用基于矢量的手工本征几何解释器和拉普拉斯向量来提取和评估点云形态,从而改进了FSL(少射学习)的表示。此外,拉普拉斯向量能够从点云中提取有价值的特征。为了解决分布漂移挑战,本文利用双曲空间,并证明该方法比现有的点云少镜头学习方法更好地处理了类内和类间的方差。
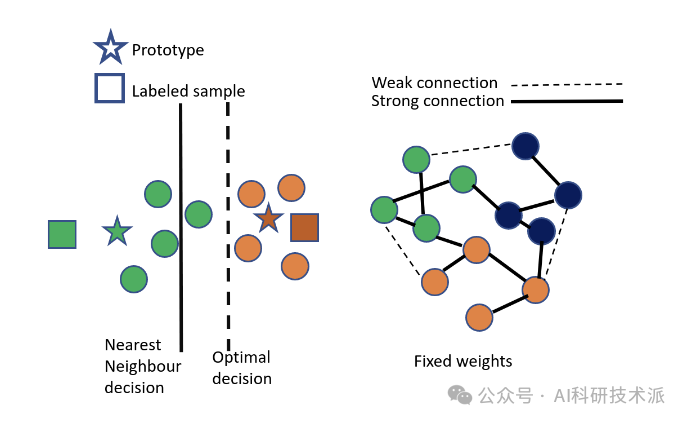
Transductive Few-shot Learning with Prototype-based Label Propagation by Iterative Graph Refinement
「简述」
与归纳的少量学习相比,转换模型通常表现更好,因为它们利用了查询集的所有样本。现有的基于原型和基于图的两类方法分别存在原型估计不准确和带核函数的次优图构建的缺点。
本文提出了一种新的基于原型的标签传播来解决这些问题。具体来说,本文中的图构建是基于原型和样本之间的关系,而不是样本之间的关系。随着原型的更新,图表也随之改变。作者还估计了每个原型的标签,而不是将原型视为类中心。
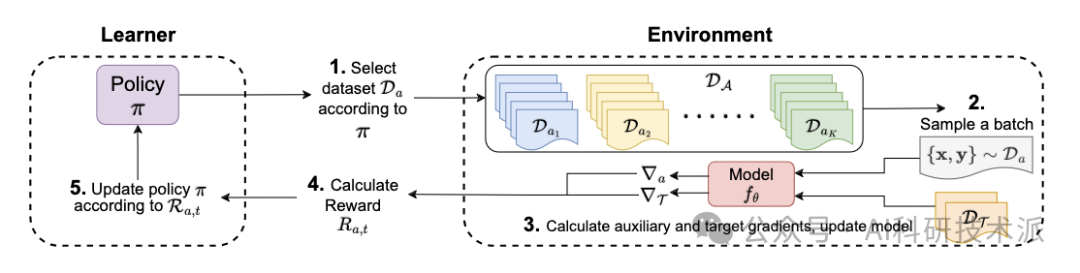
Improving Few-Shot Generalization by Exploring and Exploiting Auxiliary Data
「简述」
在这项工作中,本文专注于使用辅助数据的少量学习(FLAD),这是一种训练范式,假定在少量学习期间可以访问辅助数据,以期提高泛化。在少数镜头学习中引入辅助数据会导致必要的设计选择,而手工设计的启发式可能会导致次优性能。
在这项工作中,作者专注于FLAD的自动采样策略,并将其与多武装强盗设置中的核心探索-利用困境联系起来。基于这种联系,作者提出了两种算法——EXP3-FLAD和UCB1-FLAD,并将它们与探索或利用的方法进行比较,发现探索和利用的结合是至关重要的。