原文链接:https://mbd.baidu.com/newspage/data/landingsuper?urlext=%7B%22cuid%22%3A%22YuSqtYPoHa0Ya2aaguBjilanvu0giStLlu-z8_a7HaKw0qqSB%22%7D&rs=1900699088&ruk=8MVN0ObRzpLf_xb_Ge1TDQ&like_icon_type=2&isBdboxFrom=1&pageType=1&sid_for_share=&context=%7B%22nid%22%3A%22news_8837415284647567684%22,%22sourceFrom%22%3A%22bjh%22%7D
大语言模型的诞生,切实地推进了人工智能的发展。但随着模型越来越大、训练数据越来越多,人们对于模型的了解反而越来越少。
就拿大语言模型的典型代表 GPT-4 来说,即便时至今日,它依然会对一些在人类看来很简单的问题,给出错误的回答(如下图所示的两个案例)。
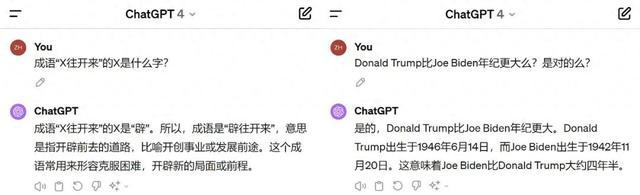
图丨案例截图(来源:朱泽园)
那么,这到底是 GPT-4 本身的问题,还是它的训练数据不足,亦或是它的数学能力太弱?其他模型会有这个问题吗?
对于追求严谨的科学家来说,有必要思考这一系列问题的原因,并尝试发现其背后存在的普适性定律。
6 个月前,来自 Meta 旗下的人工智能基础研究实验室(FAIR Labs)的朱泽园和合作者 MBZUAI 的李远志教授,在研究大语言模型是“如何学习知识”的过程中,发现了一些意想不到的复杂情况。
譬如:有些知识,模型可以记住,但说不出来;有些知识,模型可以说出来,但是无法推演。
有些具备顺序性的知识,比如成语“继往开来”这四个字,始终是按顺序出现的,所以不管大语言模型有多大以及训练了多久,它都只能记住正序,而无法记住逆序知识。这种涉及到“知识的顺序性”的现象,被学术界称为“逆转诅咒”。

(来源:arXiv [3])
为了克服这一难题,近日,FAIR Labs 实验室提出了一种替代训练方案名为“逆转训练”,大致思路是对所有的数据,都正向和“逆向”同时训练两次,然后通过寻找最可靠的“逆向”训练方法,来效地解决逆转诅咒问题。
近日,相关论文以《逆转训练攻克逆转诅咒》(Reverse Training to Nurse the Reversal Curse)为题在预印本平台 arXiv 上发表[1]。
作者包括 FAIR Labs 研究工程师奥尔加·戈洛夫涅娃(Olga Golovneva)、研究科学家朱泽园(Zeyuan Allen-Zhu)、研究科学家杰森·韦斯顿(Jason Weston)和研究科学家桑巴亚尔·苏赫巴托尔(Sainbayar Sukhbaatar)。

图丨相关论文(来源:arXiv)

提出逆转训练方案,攻克大语言模型的逆转诅咒难题
其实,在探究大模型针对简单的问题却给出错误回答背后的原因时,朱泽园认为,过度追求大语言模型在基准数据集上的表现,也可能让人类和通用人工智能渐行渐远。
例如,最近发表在 Nature 上的 AlphaGeometry[2],是 DeepMind 开发的一个 AI 系统,能够解决国际数学奥林匹克竞赛 30 道平面几何题中的 25 道。
但它的主算法却是一个没有 AI 参与的暴力搜索,搜索的步骤从数百条由人工挑选的引理中选择。
有没有一种可能是,DeepMind 人工挑选了上百条为 30 道国际数学奥林匹克竞赛题量身定做的引理呢?
“我们对此表示质疑(仅代表本团队,并非 Meta 官方立场)。但从科学的角度来看,我们应该尽量避免人工干预,以防‘有多少人工,就有多少智能’。” 朱泽园表示。

图丨朱泽园(来源:朱泽园)
基于类似以上的担忧,朱泽园提出了“语言模型物理学”这一新概念。
此概念主张,在物理学的启发下化繁为简,将“智能”分拆成多个维度,包括语法、知识、推理、解题等,并给每个维度创建全新的合成数据,搭建理想化的大语言模型训练和测试环境,以探索模型所具备的普适性定律。类似在真空中研究牛顿定律,或是理想环境下研究气体方程。
需要说明的是,研究人员并不应该局限于类似 GPT-4 这样的个别模型,而是应该总结出在理想的数据集下,任何模型所展现出的普适性质。
“对于人工智能领域来说,通过在理想环境中去伪存真,我们可以排除数据作弊、人工挑选等因素,真正找出大语言模型的普适定律,并提出增强性能的方案。”朱泽园表示。
据了解,《语言模型物理学》项目的第一部分专注于语法研究,第二部分侧重于推理研究,第三部分则聚焦于知识研究,其他更多部分的研究也在积极推进中,并在 Meta 内部立项,得到 FAIR 研究院的海量算力支持。
“不过因为发现过多,仅是其中第三部分‘知识研究’就拆成了至少三篇论文 Part 3.1、3.2、3.3,每篇都有几个甚至十几个结论,均已在 arXiv 上发表。”朱泽园说。

图 | 《语言模型物理学》第三部示意图(来源:作者 twitter)
对于发表在 Part 3.2 论文中的“知识的顺序性”这一现象来说,朱泽园和李远志最早是在理想环境中观察到它,而后又在市面上可见的预训练模型,如 GPT-4 和 LLaMA-2 中,验证了它的存在。
那么用“理想环境”而不是现实模型来做研究,有什么好处呢?
譬如这个课题里,在理想环境中我们可以固定知识的顺序,也不用担心测试数据的污染。
假如我们永远都说“某某人,在 XXXX 年 X 月 XX 日出生”,以保证数据集中的知识都是人名在生日之前;然后,再提取出该数据集中一半的人员信息,训练模型的逆向知识提取能力,比如“在 XXXX 年 X 月 XX 日出生的人,叫什么名字”。
我们就会发现,不管模型多大、训练多久,它都只能对这一半的人完成逆向知识提取(正确率 100%,因为这一半人在训练集里),而无法推演(generalize)到剩下一半的人(正确率 0%)。
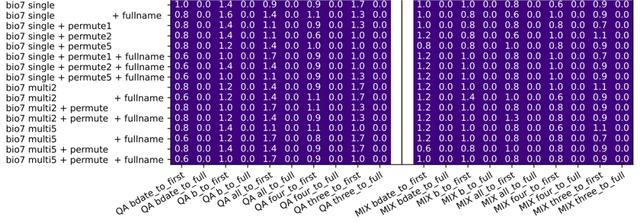
图 | 在理想环境下,所有逆向知识提取的正确率都几乎是 0(来源:arxiv[3])
换言之,理想环境下,不仅可以将测试集和训练集完全分开,也能让数据量无限增大,甚至还可以把模型打开,观察出“为什么”知识无法逆向提取,并得到提取知识的充分必要条件。
更重要的是,理想环境下的研究,可以推广到包括 GPT-4 在内的现实模型上,也能观察到“逆转诅咒”。
比如,除了如上所说的成语逆转,还可以向大语言模型询问“西出阳关无故人”的上一句话,或是给出百科上名人的出生年月日/工作单位/城市,来反问大语言模型这个人名是谁。
“大量的测试告诉我们,现实模型也无法很好地回答这样的逆序知识类问题。”朱泽园说。
不过,需要指出的是,在现实模型上很难确定造成这些错误回答的原因,究竟是模型训练得不够久,还是数据不够多。
即便现实模型答对了,会不会它的训练数据中看到了原题(也就是数据污染)。综上,在现实模型上直接研究,很难得到令人信服的、科学的结论。
“这就是为什么我们要做《语言模型物理学》的原因,即希望探索出一种全新的研究 AI 模型的思路。”朱泽园表示。
发现问题是一方面,要想解决“逆转诅咒”,就是一个新的延伸课题了。为此,朱泽园和 FAIR Labs 实验室的“推理记忆”课题组联手,基于理想环境中的发现,给出现实生活中的一个解决方案——随机拆词反转训练。
主要是把每 1-25 个连续 token(对应约 1-15 个英语单词)随机拆成一组,在保持每组顺序不变的前提下,将整个文章进行反转。
同时使用正向的原文,和反转后的文字对语言模型进行训练。如果同一数据会多次进行反转训练,则可以每次用不同的随机方法拆词,这在无形之中增加了数据的多样性,从而增强大模型对知识的存取效率。
从另一方面来看,随机拆词并翻转也模拟了人类速读。也就是说,当我们快速阅读一段文字的时候,眼睛也在进行随机拆解,甚至也会无序地阅读。包括在学习重要知识时,还会前后翻书和反复阅读。
研究人员将上述方法称为“逆转训练”,并且在 LLaMA-2 模型上做了真实数据的测试。
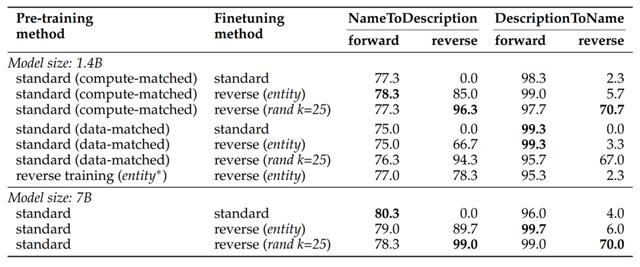
图 | 在真实 LLaMA-2 模型上测试,逆转训练可以攻克逆转诅咒(来源:arxiv[1])
同时,他们还得到了一个重要的发现:如果正反向都进行训练,既不会影响正向的训练结果,又不会让传统的基准数据集得分降低。
对于《语言模型物理学》系列作品给应用领域带来的影响,朱泽园认为会是非常全面的。作为该系列作品的一个衍生成果,《逆转训练攻克逆转诅咒》很可能在帮助解决大语言模型的诸多问题之一的同时,在所有公司的所有应用场景中得到应用。
“当然,一切的理论研究走到实际落地都有一个过程。我欢迎所有的研究人员参考我们论文给出的理论指导建议,在实际应用中找到增益。”朱泽园说。
另外,值得一提的是,2024 年 7 月,朱泽园将在 ICML 2024 上,受邀开展《语言模型物理学》系列讲坛(tutorial)课程。

致力于挑战人工智能的每个维度,希望探索出大语言模型的普适性物理定律
据了解,朱泽园本科就读于清华大学物理系,博士毕业于美国麻省理工计算机系,是图灵奖得主希尔维奥·米卡利(Silvio Micali)教授的弟子,后在美国普林斯顿大学和从事博士后研究,师从刚刚获得图灵奖的艾维·维格森(Avi Wigderson)教授。
他曾是国际信息学奥林匹克竞赛两届金牌、国际大学生程序设计竞赛全球总决赛金牌的获得者,也在谷歌全球编程挑战赛(Google Code Jam)中获得世界第二的成绩。
在 2022 年加入 FAIR Labs 之前,朱泽园曾在微软研究院总部任职。
“加入 FAIR Labs 以后,我被给予了 100% 的科研自由,可以独立发起项目,选择我认为最重要的人工智能课题进行长期研究。《语言模型物理学》项目,就是我所负责的长期项目。”朱泽园介绍说。
如上所说,《逆转训练攻克逆转诅咒》,是该项目的一个衍生课题。
不过,在最早参与该课题时,朱泽园并不十分“积极”。这主要是因为他考虑到精力有限,所以对参与科研课题一贯持谨慎态度。
“当这一课题负责人苏赫巴托尔联系我时,我从理论的角度出发,告诉他已经在理想环境下证明了数据反向训练有效。所以,我认为逆转训练这个方法太过简单,只需要多做点大规模的实验而已。”他说。
但苏赫巴托尔反问道:“那你当初为什么要发表 LoRA 呢?”
这个问题促使朱泽园进行了长时间的思考和反省,并最终做出了改变想法的决定。
其中,LoRA 是朱泽园在微软研究院供职时参与开发的一个简单有效的微调工具。当时他也曾认为该工具过于简单,但如今后者已经成为行业内最常用的微调算法,业内几乎无人不晓。
《逆转训练攻克逆转诅咒》课题开始进行之后,朱泽园和合作者发现不同的逆转训练策略在效果上存在差异,与他们最初的预期不同。对此,他们也在论文中进行了详细的比较。
“总的来说,如果一个算法简易且有用,还不需要复杂的数学公式,这不正是我们人类最希望获得的吗?”朱泽园表示。
另外,在目前研究的基础上,他告诉我们,《语言模型物理学》项目也制定了后续计划,包括 2 个月内可以发布的项目第二部分“语言模型推理研究”的两篇论文,会在理想环境下研究并提高 AI 模型在小学数学题上的推理能力等。
朱泽园说:“我们有一个很远大的目标,那就是在理想的环境里去伪存真,挑战人工智能的每一个维度,总结出大语言模型的普适物理定律。”
与此同时,他也认为,致力于研究理想环境下的大语言模型的《语言模型物理学》项目,与大部分科研都不相同。
“在我眼中,这仿佛是一个新的学科和一个新的研究问题的方式,非常刺激。因此,我几乎停下了手上一切科研方向,全身心地扑向其中。”他表示。
即便在研究过程中受到诸多批评和质疑,包括测得的数据是否过于理想化、可能太过局限,以及和实际有差异等,但他对此却依然毫不担心。
他始终奉行坚持日心说的意大利科学家乔尔丹诺·布鲁诺(Giordano Bruno)曾经说过的这句话,“真理不会因为大多数人相信或不相信而改变”。
参考资料:
1. O.,Golovneva, Z., Allen-Zhu, J., Weston. et al. Reverse Training to Nurse the Reversal Curse. arXiv:2403.13799v1(2024).https://doi.org/10.48550/arXiv.2403.13799
2. Trinh, T.H., Wu, Y., Le, Q.V. et al. Solving olympiad geometry without human demonstrations. Nature 625, 476–482 (2024). https://doi.org/10.1038/s41586-023-06747-5
3. Z. Allen-Zhu, Y. Li. Physics of Language Models: Part 3.2, Knowledge Manipulation.arXiv:2309.14402(2023). https://arxiv.org/abs/2309.144027
排版:刘雅坤
