原文链接:https://mbd.baidu.com/newspage/data/landingsuper?urlext=%7B%22cuid%22%3A%22luHj8ja02t0j8StQYuvpugiqBagNi2f6_u28aliQ2aKm0qqSB%22%7D&rs=3295762669&ruk=8MVN0ObRzpLf_xb_Ge1TDQ&like_icon_type=2&isBdboxFrom=1&pageTyp
e=1&sid_for_share=&context=%7B%22nid%22%3A%22news_9873037388497569461%22,%22sourceFrom%22%3A%22bjh%22%7D

近日,著名的计算机科学家、Meta首席人工智能科学家、图灵奖得主Yann LeCun做客硅谷科技圈第一播客Lex Fridman Podcast,与Lex Fridman就大语言模型的局限、开源、人工智能未来发展等问题进行了将近三小时的深度探讨。
在这次对话中,Yann LeCun分享了他对开源模型的独到见解和深入思考,他强调开源模型不仅是解决AI偏见和潜在危险的必由之路,更是我们迈向自由且多样化人工智能系统的关键所在。此外,他也详细剖析了自回归大语言模型的局限性,阐述了构建真正世界模型的底层逻辑,并回应了一些人对AI末日论的担忧,他坚信AI将增强人类的整体智慧,而非带来灾难。通过这次访谈,我们得以一窥AI领域的前沿思考,以及Yann LeCun对于构建一个更加智能、更加公正的未来世界的愿景。
Lex Fridman是一名俄罗斯裔美国计算机科学家、AI研究员和播客主持人,致力于研究人工智能、自动驾驶技术等相关领域。他不仅在学术界有所建树,更通过其播客和YouTube频道广受欢迎,采访了众多领域的杰出人士,吸引了广泛关注。
本文编译自Lex Fridman与Yann LeCun的部分对谈,旨在帮助大家进一步了解AI巨头的最新思考与独到见解。
自回归大语言模型并非通向“超人智能”的途径,它们尚不具备理解物理世界、持久记忆、逻辑推理和行动规划等“人类水平智能”的关键要素。
构建世界模型意味着让AI像人类一样观察世界并理解世界以何种方式演变,然后预测世界将如何随着可能的行动而演变。
要想拥有人工智能产业、拥有不带偏见的人工智能系统,唯一的办法就是拥有开源平台,在此基础上,任何团体都可以建立专门的系统。
人工智能系统不会成为一个与人类竞争的物种,因为它们没有主宰的欲望。人工智能可以让人类变得更加聪明。
#01
自回归大语言模型是通向“超人智能”的途径吗?
Lex Fridman:谈到AI的未来,最近你曾在采访中表示,自回归LLM(大语言模型)并非通向“超人智能”的途径。比如说GPT-4、Llama 2 和即将发布的Llama 3 等大语言模型,它们是如何工作的,为什么它们不能带领我们一路前行?
Yann LeCun:原因有很多。首先,“智能行为”有许多特征。例如,理解物理世界的能力、记忆和检索事物的能力(持久记忆)、推理能力和计划能力,这些是智能系统或实体(比如人或动物)的四个基本特征。LLM无法做到这些,或者只能以非常原始的方式做到,它们并不真正理解物理世界、没有持久记忆、无法进行真正的推理,也无法制定计划。当然,自回归LLM是有用的,但并不有趣,我们无法围绕它们构建一个完整的应用生态系统。所以,作为迈向人类水平智能的 "通行证",自回归LLM缺少必要的组成部分。
有一个我认为非常有趣的事:LLM是在海量文本中训练出来的,几乎是互联网上所有公开可用文本的全部,通常是1013个Token(标记)的数量级。每个Token大约是两个字节,所以训练数据约是2×1013字节。这些数据如果人类每天阅读8小时,需要17万年的时间才能读完。看上去这些系统似乎积累了大量知识,但实际上这些数据并不多。如果你和发育心理学家交谈,他们会告诉你,一个4岁的孩子在他的生命中已经有16000小时醒着,并且通过估计视觉神经大约每秒传输20兆字节来计算,4年中到达这个孩子视觉皮层的信息量大约是1015字节,比17万年的文本要多50倍。这告诉我们,人类通过感知系统接收到的信息比通过文本要多得多。换言之,人类学到的大部分知识都是通过观察和与现实世界的互动得来的,而不是通过语言。我们在生命最初几年学到的东西,以及动物学到的,都与语言无关。

Lex Fridman:的确,人类大脑接收到的数据确实是数量级更高、速度更快,并且人类大脑能够从中快速学习,快速过滤数据。但有人可能会争辩说,与视觉数据相比,语言所包含的信息量已经远远超过了存储它们所需的字节。那么,语言本身是否已经包含了足够的智慧和知识,从而能够通过语言构建世界模型和对世界的理解,即你所说的LLM对物理世界的理解?
Yann LeCun:这是哲学家和认知科学家之间的一个重大争论,即智能是否需要建立在现实之上。我认为,智能需要以某种现实为基础来实现。人类完成的很多任务都是通过操纵当前情况下的心智模型来完成的,而这与语言无关。而来自NLP(自然语言处理)领域或其他动机的人不一定同意这一点。哲学家们也有分歧。世界的复杂性难以想象。在现实世界中,我们认为所有的复杂性都是理所当然的,我们甚至不会想象它们需要智能。这就是古老的莫拉维克悖论(Moravec's paradox),出自机器人技术的先驱Hans Moravec,他说,使用计算机可以轻松完成高级复杂任务(比如下棋、解积分等),而我们认为理所当然的事情(比如学开车或抓取物体等),计算机却无法完成。为什么会这样?
目前大语言模型并不能构建一个世界模型。许多人正在努力研究这方面的内容,但我认为这是无法实现的。我们可以使用各种技巧让LLM基本上消化图像、视频或音频的视觉呈现,来实现视觉扩展(比如Stable Diffusion等),但它们基本上都是通过技巧,并没有经过端到端的训练来真正理解世界。它们并不能真正理解直观物理学,至少目前还不能。

Lex Fridman:你认为直观物理学、物理空间的常识推理、物理现实有什么特别之处,这对你来说是LLM无法跨越的鸿沟?
Yann LeCun:我们今天正在使用的LLM还无法做到真正的理解世界,这其中有很多原因,但最主要的原因是:LLM的训练方式是用一段缺失了部分文字的文本去训练一个神经网络来预测缺失的文字。事实上,LLM并不预测词语,而是生成字典中所有可能词语的概率分布,然后从概率分布中选择一个词放入文本序列的尾部,再用新生成的文本去预测下一个词,这就是所谓的自回归预测。但这种自回归的方式与人类的思维方式有很大的不同。人类大部分的思考和规划都是在更抽象的表征层面上进行的,换句话来说,如果输出的是语言(说出的话)而不是肌肉动作,人类会在给出答案之前先思考好答案。但是LLM不这样做,它们只是本能地一个接一个地输出文字,就像人类的某些下意识动作一样。
#02
真正的世界模型如何运作?
Lex Fridman:我想问一个最根本的问题是,能建立一个真正完整或不完整但对世界有深刻理解的世界模型吗?
Yann LeCun:首先,我们确定可以通过预测来构建这个世界模型,但不能通过LLM预测单词来构建它,因为语言在信息传递上的“带宽”非常有限。构建世界模型意味着观察世界并理解世界以何种方式演变,然后预测世界将如何随着你可能采取的行动而演变。因此,真正的世界模型是:我对某时刻T时世界状态的想法,叠加此时我可能采取的行动,来预测在时间T+1时的世界状态。这里所指的世界状态并不需要代表世界的一切,不一定需要包含所有的细节,它只需要代表与这次行动规划相关的足够多的信息。
十年来,我们使用生成式模型和预测像素的模型,试图通过训练一个系统来预测视频中将发生什么来学习直观物理,但失败了,我们无法让它们学习良好的图像或视频表征,这表示,我们无法使用生成式模型来学习对物理世界的良好表征。
目前,看起来可以更好地构建世界模型的一种新方法是“联合嵌入”,称为JEPA(联合嵌入式预测架构),其基本思路是获取完整的图像及其损坏或转换的版本,然后将它们同时通过编码器运行(一般来说,编码器是相同的,但也不一定),然后在这些编码器之上训练一个预测器,以根据损坏输入的表征来预测完整输入的表征。JEPA与LLM有什么区别?LLM是通过重建方法生成输入,生成未损坏、未转换的原始输入,因此必须预测所有像素和细节。而JEPA并不尝试预测所有像素,只是尝试预测输入的抽象表征,从本质上学习世界的抽象表征(例如风吹树叶,JEPA在表征空间中预测,会告诉你树叶在动,但不会预测每个树叶的像素)。JEPA的真正含义是,以自我监督的方式学习抽象表征,这是智能系统的一个重要组成部分。人类有多个抽象层次来描述世界万象,从量子场论到原子理论、分子、化学、材料,一直延伸到现实世界中的具体物体等,因此,我们不应只局限于以最低层次进行建模。
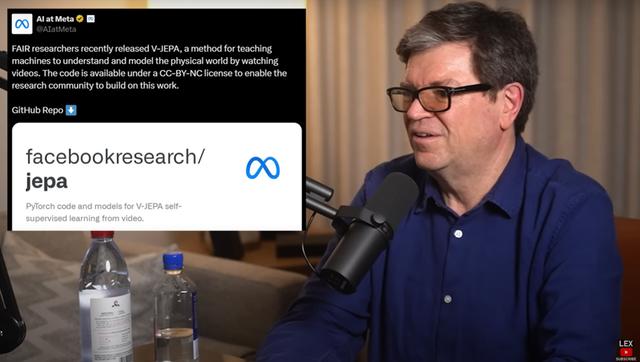
Lex Fridman:在你看来,联合嵌入式预测架构将能够学习一些常识,就像猫用来预测如何通过打翻东西来捉弄它的主人一样?
Yann LeCun:希望如此。事实上,JEPA使用的是“非对比”技术,其架构和学习程序都是非对比性的,技术涵盖基于蒸馏的BYOL、vcREG、I-JEPA(Image-JEPA)和DINO等方法(BYOL来自DeepMind,vcREG、I-JEPA和DINO来自FAIR)。这些方法的原理是:获取完整的输入,比如一张图片,通过编码器运行产生一个表征,然后对输入进行破坏或转换,再通过编码器运行,来训练预测器从损坏的输入中预测原始输入的表征。经过初步结果验证,似乎我们的系统现在可以通过表征来判断视频在物理约束上是否合理。
#03
开源是打破AI偏见的钥匙?
Lex Fridman:最近,很多人对Google发布的Gemini 1.5持强烈批评的态度,因为它做的一些滑稽的事情,比如篡改历史、生成虚假图像等。针对这些,你曾在社交媒体上表示“开源就是答案”,你能解释一下吗?
Yann LeCun:我的观点是:制造一个没有偏见的人工智能系统是绝对不可能的,因为人工智能的偏见根源于人类,不同的人可能对很多事情有不同的看法,这与技术无关。那么这个问题应该如何解决?答案就是自由和多元化。未来,人工智能系统可能构成人类所有知识的存储库,人类与数字世界的许多互动都将以人工智能系统为媒介,我们不能接受它被少数公司所控制。但由于训练基础大模型非常昂贵且困难,因此要想拥有人工智能产业、拥有不带偏见的人工智能系统,唯一的办法就是拥有开源平台,在此基础上,任何团体都可以建立专门的系统。历史发展的必然方向是,绝大多数人工智能系统都将建立在开源平台之上。
Lex Fridman:你描绘的开源模式确实很强大,但怎么赚钱呢?
Yann LeCun:Meta所围绕的商业模式是提供一项服务,并且这项服务可以通过广告或企业客户来变现。比如通过LLM帮助披萨店的顾客点餐,当顾客下单披萨后,系统会问他们:“想要什么配料,什么尺寸,等等”。商家会为此付费,这是一种模式,它还可以由广告或其他模式支持。但关键是,如果你有足够大的潜在客户群,并且无论如何你都需要为他们构建该系统,那么将模型开源也并不会有实质性的影响。Meta提供开源的基础模型,供其他人在此基础上构建应用程序,如果这些应用对我们的客户有用,我们可以直接向他们购买,并且他们可能会改进平台。事实上,Llama 2已经实现了这一点,数百万次的下载量,成千上万的人提出了如何改进平台的想法,并且有成千上万的企业正在使用该系统构建应用程序。因此,Meta从这项技术中获取收益的能力并不会因为基础模型的开源而受到影响。

Lex Fridman:与搜索引擎(比如Google搜索)相比,LLM是否会让制造生化武器这类事情变得更容易?
Yann LeCun:越来越多的相关研究似乎表明,这并没有什么帮助。第一,LLM并不能帮助你设计或制造生物或化学武器,因此,你获得的信息的数量和获取信息的难易程度,并不能对制造生化武器有所帮助。第二,有一份如何制造化学武器的说明清单是一回事,但真正制造出来又是另一回事,而且比你想象的要难得多,它需要现实世界中的专业知识,而LLM帮不了你。
Lex Fridman:Llama 3即将发布,您最期待的是什么?Llama 2已经存在,也许未来还会有Llama 3、4、5、6,只是Meta下开源的未来?
Yann LeCun:首先,会有各种版本的Llama,它们是对之前Llama的改进,更大、更好、多模态,可能是能够真正理解世界运作方式的规划系统。在实现这一目标之前,我们还必须经历一些突破。最近,我们发布了V-JEPA(Video-JEPA),迈向视频训练系统的第一步,下一步将是基于这种视频训练方法的世界模型,这是令人非常兴奋的,因为我看到了一条通往人类水平智能的道路,系统可以理解世界、记忆,并且能规划并进行推理。当然,在硬件方面也需要一些创新。
#04
AI的未来展望:毁灭or希望?
Lex Fridman:你经常反击所谓的人工智能末日论者。你能解释一下他们的观点以及为什么你认为他们错了吗?
Yann LeCun:人工智能末日论者想象了各种灾难场景,如人工智能如何逃脱或控制所有人类,这依赖于一大堆假设,而这些假设大多是错误的。一个假设是超级智能的出现将是一个事件,在某个时刻,我们打开一台超级智能机器,它就会占领世界并控制人类,这是错误的。人工智能系统一定是渐进式发展的,我们将拥有像猫一样聪明的系统,它们具有人类智能的所有特征,但它们的智能水平可能是像猫或鹦鹉之类的;然后,我们再逐步提高它们的智能水平,并在让它们变得更聪明的同时,设置一些“护栏”,并学习如何设置“护栏”,让它们表现得更加正常。这不会是一次努力,会有很多不同的人在做这件事,其中一些人将会成功地制造出可控、安全、有正确防护措施的智能系统。如果有其他系统出了问题,我们就可以利用好的系统来对抗坏的系统。还有另一个假设是,因为系统是智能的,它就一定想接管世界,因为在自然界中,似乎更聪明的物种最终会统治其他物种,这是完全错误的。人工智能系统不会成为一个物种,更不会成为与人类竞争的物种,因为它们没有主宰的欲望,主宰的欲望必须是智能系统中固有的东西。

Lex Fridman:我真的很担心人工智能霸主会用企业语言对我们说话,而你却用你的存在方式来抵制它。你能谈谈如何避免过度恐惧,通过小心谨慎来避免伤害吗?
Yann LeCun:同样,我认为这个问题的答案是开源平台,然后让各种不同的人能够构建代表全球文化、观点、语言和价值体系的多样性的人工智能助理,这样就不会因为单个人工智能实体而被特定的思维方式洗脑。因此,我认为这对社会来说是一个非常重要的问题。在我看来,通过专有人工智能系统集中权力的危险比其他一切都要大得多。与此相反的是,有人认为出于安全考虑,我们应该把人工智能系统锁起来,因为把它交到每个人手里太危险了。这将导致一个非常糟糕的未来,即我们所有的信息都被少数拥有专有人工智能系统的公司所控制。
Lex Fridman:你对人类的未来抱有什么希望?我们正在讨论这么多令人兴奋的技术,这么多令人兴奋的可能性。展望未来,是什么给了你希望?如果你看看社交媒体,就会发现战争、分裂、仇恨正在发生,所有这些都是人性的一部分。但在这一切之中,是什么给了你希望?
Yann LeCun:我喜欢这个问题。我们可以通过人工智能让人类变得更加聪明。人工智能会放大人类的智慧,就好像每个人都将拥有一些智能人工智能助理,它们可能比我们更聪明,会听从我们的命令,还能以更高效、优质的方式执行任务,因此,每个人都会成为一群超级聪明的虚拟人的老板。因此,我们不应该对此感到威胁,就像我们不应该对成为一群人的管理者感到威胁一样,其中有些人比我们更聪明。本质上,人工智能助理的普及与印刷术的发明具有同等价值,它们都有利于信息和知识的交流及传播,从而使人类变得更加聪明。
Lex Fridman:我相信人性本善,因此如果人工智能,尤其是开源的人工智能可以使人类更聪明,那它只会增强人类的善良。
Yann LeCun:我也有同感。我认为人的本性是善良的,而事实上,很多末日论者之所以是末日论者,是因为他们不认为人的本性是善良的。
Lex Fridman:我想你和我都相信人性,我想代表很多人感谢你推动推动人工智能研究和开源,也感谢你在互联网上以如此丰富多彩、生动形象的方式表达你的想法。我希望你永远不要停止。你是我认识的最有趣的人之一,我是你的粉丝。所以,Yann,谢谢你再次和我对话,谢谢你做你自己。
Yann LeCun:谢谢你,Lex。
相关参考:
https://lexfridman.com/yann-lecun-3-transcript
《AI巨头杨立昆的最新3小时访谈聊了些什么》,Web3天空之城
《170分钟、四万字,LeCun最新专访:大语言模型的败因和人工智能的未来》,氢AI
*素材来源于网络
