原文连接:https://mbd.baidu.com/newspage/data/landingsuper?
ChatGPT的出现在全球掀起了AI大模型的浪潮。
区块链是生产关系的重构,元宇宙是虚拟场景的重构,而互联网则解决了信息流通和生产效率的问题,但这些都是在生产关系范畴内,而ChatGPT的出现则大幅度提升了生产力,让人类可以将电能转换成脑力和通用智力。很多人已经把这次AI浪潮称为“第四次科技革命”。甚至《自然》杂志把非人类的Chat GPT列入“年度科学人物”

根据国际数据公司IDC预测,全球AI计算市场规模将从2022年的195.0亿美元增长到2026年的346.6亿美元。其中,生成式AI计算市场规模将从2022年的8.2亿美元增长到2026年的109.9亿美元。
据国外风投数据分析公司PitchBook的数据,2023上半年,全球人工智能领域共计发生融资1387件,筹集融资金额255亿美元,平均融资金额达2605万美元。
在这次AI浪潮之中,世界各个国家和地区有哪些知名的AI大模型发布,在发展大模型上又进展如何?这些问题就是本文要分析讨论的。
美国:牢牢占据主导地位
美国代表性AI大模型清单:
GPT-4
OpenAI的GPT-4模型是2023年最好的AI大模型,没有之一。GPT-4模型于2023年3月发布,展示了其强大的能力,包括复杂的推理能力、高级编码能力、多种学术学习能力、可媲美人类水平表现的能力等。
GPT-4模型已经在超过1万亿个参数上进行了训练,支持32768个令牌的最大上下文长度。最近的报道透露,GPT-4是一个混合模型,由8个不同的模型组成,每个模型都有2200亿个参数。
2.PaLM 2 (Bison-001)
谷歌的PaLM 2 AI模型,它也是2023年最好的大型语言模型之一。Google在PaLM 2模型上专注于常识推理、形式逻辑、数学和20多种语言的高级编码。据说,最大的PaLM 2模型已经在5400亿个参数上进行了训练,最大上下文长度为4096个令牌。
它也是一个多语言模型,可以理解不同语言的习语、谜语和细致入微的文本。这是其他大模型难以解决的问题。PaLM 2的另一个优点是它的响应速度非常快,可以同时提供三个响应。
3. Claude v1
Claude是一个强大的大模型,由谷歌支持的Anthropic开发。它是由前OpenAI员工共同创立的,其方法是构建有用、诚实和无害的人工智能助手。在多个基准测试中,Anthropic的Claude v1和Claude Instant模型显示出了巨大的前景。事实上,Claude v1在MMLU和MT-Bench测试中的表现要好于PaLM 2。
它接近于GPT-4,在MT-Bench测试中得分为7.94,而GPT-4得分为8.99。在MMLU基准测试中,Claude v1获得75.6分,GPT-4获得86.4分。Anthropic也成为第一家在其Claude-instant-100k模型中提供10万代币作为最大上下文窗口的公司。你基本上可以在一个窗口中加载近75000个单词。
4. Cohere
Cohere是一家人工智能初创公司,由曾在谷歌大脑团队工作的前谷歌员工创立。它的联合创始人之一Aidan Gomez参与了Transformer架构的“Attention is all you Need”论文的撰写。与其他AI公司不同,Cohere为企业服务,并为企业解决生成式AI用例。Coherence有很多模型,从小到大,从只有6B个参数到训练了52B个参数的大模型。
5.Gemini
Gemini 是最新、功能最强大的大型语言模型 (LLM),由 Google 子公司 Google Deepmind 团队开发,Gemini 是一个“原生多模态 AI 模型”,它被从头开始设计为包含文本、图像、音频、视频的多模态模型,和代码,一起训练形成一个强大的人工智能系统。
6. LLaMA
LlaMA是Meta AI开发的一种新的开源大语言模型。它正式发布了各种类型的LLaMA模型,从70亿个参数到650亿个参数。LLaMA 65B模型在大多数用例中都显示出了惊人的能力。它在Open LLM排行榜上名列前十。Meta表示,它没有进行任何专有训练。相反,该公司使用了来自CommonCrawl、C4、GitHub、ArXiv、维基百科、StackExchange等网站的公开数据。
7. Guanaco-65B
LLaMA衍生的模型中,Guanaco-65B被证明是最好的开源大模型,Guanaco有四种类型:7B、13B、33B和65B型号。Tim Dettmers和其他研究人员在OASST1数据集上对所有模型进行了微调。
8. Vicuna 33B
Vicuna是LMSYS开发的另一个强大的开源大模型。它也是从LLaMA衍生而来的。它使用监督指导进行了微调,训练数据是从sharegpt.com网站上收集的。这是一个自回归的大模型,基于330亿个参数进行训练。
9. MPT-30B
MPT-30B是另一个与LLaMA衍生模型竞争的开源大模型。它是由Mosaic ML开发的,并对来自不同来源的大量数据进行了微调。它使用来自ShareGPT Vicuna、Camel AI、GPTeacher、Guanaco、Baize和其他的数据集。这个开源模型最棒的部分是它有8K令牌的上下文长度。
美国AI大模型发展状态:
从2012年AI萌芽时期,到2022年ChatGPT带来的AI浪潮,美国一直是AI领域的破局者,引领着全世界AI的进一步发展。无论是算力、算法,还是数据,美国都牢牢占据主导地位。
现在几乎所有AI大模型训练时采用的Transformer网络结构,是谷歌在2017年提出的,它具有优秀的长序列处理能力,更高的并行计算效率,无需手动设计以及更强的语义表达能力等特征。Transformer的提出让大模型训练成为可能。
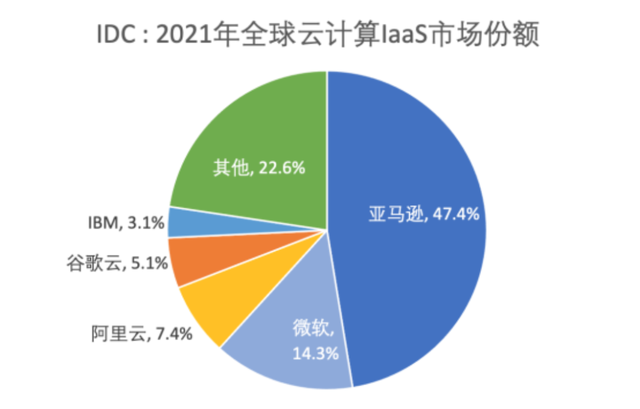
算力是保证AI大模型出现在美国的另一个关键。美国拥有世界上最大的云计算企业。IDC数据显示,2021年全球IaaS市场中,包括亚马逊、微软、谷歌、IBM在内的美国企业合计占比近70%。
算力的另一个维度是芯片,高性能的芯片可以提供更加高效的计算能力,从而加速训练过程。
2016年,黄仁勋亲手将世界第一台DGX-1(英伟达计算平台)捐献给了OpenAI,DGX-1是3000人花费3年时间才研发出来的首个轻量化的小型超算,计算和吞吐能力相当于 250台传统服务器。有了DGX-1,OpenAI之前一年的计算量只要一个月就能完成。
目前为止,英伟达的A100芯片仍然是唯一能够在云端实际执行任务的GPU芯片。最近的GTC2023上,黄仁勋又更新了新芯片H100的进度。H100配有Transformer引擎,可以专门用作处理类似ChatGPT的AI大模型,由其构建的服务器效率是A100的十倍。
从经济、文化、政策、人才,到资金、硬件、软件、环境,几乎在每个方面都领先其他人一大截,这也导致目前行业最具代表性的AI大模型都集中在美国。
中国:奋起直追,不服就干
中国代表性AI大模型清单:
1、智源人工智能研究院:悟道
2021年3月,智源研究院发布了“悟道1.0”,这是中国的第一个AI大模型。智源研究院是科技部和北京市支持的,依托北京大学、清华大学、中国科学院、百度、小米、旷视科技等北京人工智能方面优势企业共同建立的研究机构。
悟道2.0参数达到1.75万亿个,可以同时处理中英文和图片数据。智源研究院还为中国构建了大规模预训练模型技术体系,并建设开放了全球最大中文语料数据库WuDaoCorpora。
2、百度:文心一言
2023年3月16日,基于文心大模型,百度发布文心一言,成为中国第一个类ChatGPT产品。
3、华为:盘古
华为在2021年基于昇腾 AI 与鹏城实验室联合发布了鹏程盘古大模型。盘古大模型包括CV和NLP两类大模型。其中,盘古NLP大模型是业界首个千亿级中文NLP大模型。
4、阿里巴巴:通义大模型
阿里在2022年9月发布了“通义”大模型系列,包含NLP大模型AlicMind、视觉大模型CV,多模态大模型M6。其中M6大模型是国内首个千亿参数多模态大模型。
5、科大讯飞:星火
2023年5月6日,科大讯飞正式发布星火认知大模型。拥有跨领域的知识和语言理解能力,能够基于自然对话方式理解与执行任务,包括语言理解、知识问答、逻辑推理、数学题解答等。
6、清华大学:ChatGLM-6B
ChatGLM-6B是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM)架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。

7、上海人工智能实验室:书生·浦语(InternLM)
InternLM是在过万亿 token数据上训练的多语千亿参数基座模型。通过多阶段的渐进式训练,InternLM 基座模型具有较高的知识水平,在中英文阅读理解、推理任务等需要较强思维能力的场景下性能优秀,在多种面向人类设计的综合性考试中表现突出。
8、百川智能:baichuan-7B
Baichuan-7B是由百川智能开发的一个开源可商用的大规模预训练语言模型。基于 Transformer 结构,在大约 1.2 万亿 tokens 上训练的 70 亿参数模型,支持中英双语,上下文窗口长度为 4096。
9、腾讯:混元
2023年2月初,腾讯混元AI大模型团队再推出万亿中文NLP预训练模型HunYuan-NLP-1。目前HunYuan-NLP-1T大模型已在腾讯广告、搜索、对话等内部产品落地,并通过腾讯云服务外部客户。
中国AI大模型发展状态:
截止2023年12月,中国已经发布了约238个大模型。10 亿级参数规模以上基础大模型至少已发布 79 个,而美国这一数字为 100 个,中美两国大模型的数量占全球大模型数量的近 90%。
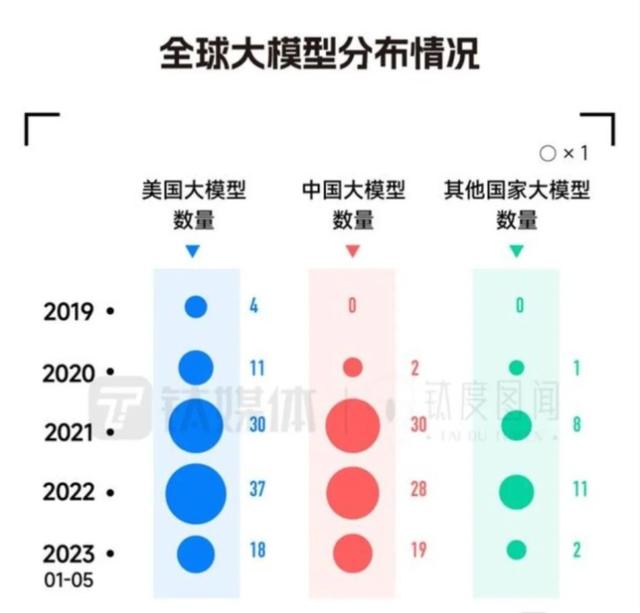
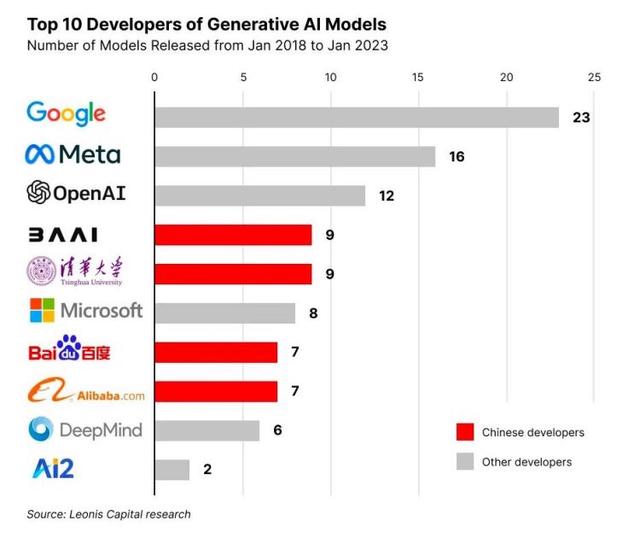
从数量来看,截至目前,国内大模型发布数量与美国差距不大,但从整体的影响力来看,国内大模型还没像 OpenAI、谷歌一样形成世界性的影响力,此外,由于大模型对人才、资本和技术的制约,国内一级市场对大模型项目的投资并不如美国那样火热,国内更倾向于利用龙头企业的开源模型来做应用落地的创业。
浓厚的工程师文化,使得美国在基础研究上保持领先地位,但许多工程师对于大模型的应用并没有什么经验,此外落地应用涉及的交付、维护等环节需要人力支持,而国内企业创业的初衷就为落地而去,这使得中国在落地应用上有可能领先一步。
欧洲:持续摆烂
欧洲代表性AI大模型清单:
1、Luminous
2022年4月,位于海德堡的德国初创公司Aleph Alpha发布了一款拥有700亿参数的预训练模型Luminous,大约是GPT-3的一半左右。Aleph Alpha在此基础上训练了聊天机器人Lumi,并计划在今年晚些时候发布最新版Luminous-World,其参数规模将达到3000亿。
作为欧洲企业,Luminous最大的特点在于更保护安全和隐私,Aleph Alpha 表示他们“不记录任何用户数据”。
2、BLOOM
2020年8月,BLOOM大模型发布,这是一个由AI初创公司Hugging Face在法国政府的资助下发起的项目,全球1000多名志愿者研究人员耗时一年多创建的AI模型,旨在消除传统大语言模型的保密性和排他性,并从一开始就嵌入伦理考量。
BLOOM有1760亿参数,它被设计得尽可能透明,并且是第一次采用了西班牙语、阿拉伯语等语言训练。BLOOM最大的特点在于可访问性,任何人都可以从Hugging Face网站免费下载它进行研究。

3、Mistral 7B
法国的创业公司Mistral AI,推出了一款只有7.3亿参数的语言模型Mistral 7B,它在各种标准的英文和代码基准测试中,击败了Llama 2和其他所有目前可用的开源模型。
欧洲AI大模型发展状态:
生命未来研究所在一份报告中指出,欧洲普遍缺乏开发AI大模型所需的资金、数据和计算资源。欧洲可能会主要扮演一个使用者的角色,即通过接入其他国家开发的大模型API来开发应用。
另外,欧洲在AI大模型上的关注重点与世界其他国家是不一样的,开源普惠、绿色安全这一类关于SDG的词汇一直是欧洲关注的重点。
日本:互联网坑地
日本代表性AI大模型清单:
1、HyperCLOVA
HyperCLOVA最早是韩国搜索巨头NAVER在2021年推出的,其日本版是由NAVER和其子公司LINE(韩国软件在日本经营)一起研发。但HyperCLOVA确实是第一个专门针对日语的大语言模型,其通过爬取日本的博客服务来获取训练数据,并在2021年举行的对话系统现场比赛中获得了所有赛道的第一名。
基于HyperCLOVA,LINE也推出许多应用,比如聊天机器人CLOVA Chatbot、图像识别CLOVA OCR和科洛瓦演讲CLOVA Speech等等。HyperCLOVA拥有820亿参数,目前正计划通过超100亿页的日文数据作为学习数据将模型规模扩大到1750亿。
2、Rinna
Rinna最早是微软日本研发的一款聊天机器人,2021年8月,Rinna发布了一个名为GPT2-medium的模型,然后又在次年推出了日本版的GPT-2,参数达到13亿。日语版GPT-2与GPT-2的区别在于,GPT-2采用的是英文语料,而日语版GPT-2是基于日语语料训练。
3、ELYZA Pencil
2022年3月,由东京大学松尾研究所的AI初创公司 ELYZA Co., Ltd.推出大语言模型,它以产品“ELYZA Pencil”的方式推向市场。输入几个关键字,ELYZA Pencil可以在大约6秒内创建三种类型的日语新闻报道、电子邮件或简历。ELYZA Pencil才算真正意义上日本首次公开发布的生成式AI产品。
4、open-calm
open-calm 是 CyberAgent 在日语语料库上训练的 70 亿参数基础模型。
5、Stormy-7b-10ep
Stormy-7b-10ep 是由Izumi-Lab在open-calm上进行微调的版本。
日本AI大模型发展状态:
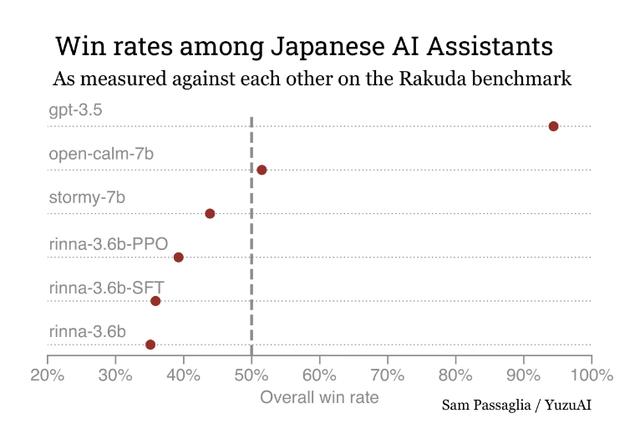
小岛秀夫表示:日本在生成人工智能领域的落后地位很大程度上源于其在深度学习和更广泛的软件开发方面的相对缺陷。深度学习需要一个“强大的软件工程师社区”来开发必要的基础设施和应用程序,然而,根据经济产业省的数据,到 2030 年,日本将面临 789,000 名软件工程师的短缺。
日本还面临硬件挑战,因为大模型需要使用 AI 超级计算机,日本没有一家私营公司拥有具备这些能力的“世界级机器”。
韩国:跟随美国,优势很明显
韩国代表性AI大模型清单:
1、HyperCLOVA
韩国最大的搜索公司Naver在2021年推出了HyperCLOVA,韩国版的 HyperCLOVA 拥有2040亿参数,它学到的韩语数据比GPT-3多 6,500
。这使得该模型和 CLOVA X 对于本地化体验特别有用,它不仅可以理解自然的韩语表达,还可以理解与韩国社会相关的法律、制度和文化背景,从而提供答案。
2、KoGPT
2021年,韩国另一家互联网巨头Kakao 旗下的AI研究部门Kakao Brain发布了一个基于GPT-3的KoGPT,之后Kakao Brain又将KoGPT更新至GPT-3.5,实现与 ChatGPT使用相同版本的预训练大模型。
3、Exaone
2022年12月,LG集团的人工智能智库LG AI Research推出了Exaone。这是一个拥有3000亿参数,使用图像和文本数据的多模态模型,也是目前韩国参数规模最大的模型
4、A.
2023年9月,SKT推出全球首个韩语大语言模型(LLM)“A.”,或A Dot,据称将演变成个人人工智能助理服务。
韩国AI大模型发展状态:
事实上,韩国是最早加入AI大模型研发的国家之一,在硬件上也有不错的资源,三星电子是全球最大的动态随机存取存储器芯片制造商,SK 海力士是全球第二大 DRAM 芯片制造商。韩国在AI工业与AI医疗方面的探索非常积极,这些优势都让韩国能在AI大模型的发展浪潮中走在世界前列。
其他地区:有几个亮点
1、以色列:AI21 Labs
AI21 Labs总部位于以色列特拉维夫,由Ori Goshen、Amnon Shashua教授和斯坦福大学教授Yoav Shoham于2017年共同创立。AI21 Labs是家全栈的AI公司,它有自己的基础大模型Jurassic-2,然后用大模型的力量支持ToB的开发者平台AI21 Studio以及ToC的产品Wordtune和Wordtune Read。
2、俄罗斯:YaLM
YaLM 100B 是一个类似 GPT 的神经网络,用于生成和处理文本。它可供世界各地的开发者和研究人员免费使用。
该模型利用 1000 亿个参数。我们花了 65 天的时间在由 800 个 A100 显卡和 1.7 TB 的在线文本、书籍以及无数其他英语和俄语资源组成的集群上训练该模型。
3、阿联酋:Falcon
Falcon是一个开源大模型,它是由阿联酋技术创新研究所开发的。它已经使用Apache 2.0许可证开源,这意味着您可以将该模型用于商业目的,也没有版税或限制。
Falcon模型主要训练英语、德语、西班牙语和法语,但它也可以用意大利语、葡萄牙语、波兰语、荷兰语、罗马尼亚语、捷克语和瑞典语工作。

4、阿联酋:NOOR
NOOR,拥有 100 亿个参数,这是迄今为止世界上最大的阿拉伯语自然语言处理(NLP)模型。
其他地区AI大模型发展状态:
在一些AI发展的边缘地区,他们缺乏技术、硬件与市场等资源,但凭借互联网开源的技术,结合对本地区语言数据的天然优势,也取得了一些可喜的成果。
最后的话
ChatGPT的出现代表了一种前所未有的生产力革命,它将改变我们的生活方式和工作方式,也将推动社会的发展和进步。我们需要保持开放、包容和积极的姿态,不断探索和发展人工智能的潜力和应用,为我们的未来创造更多的机遇和可能性。
