原文链接:https://mp.weixin.qq.com/s/XAbwMT5Eb9VRsl9fuTBQYg
前不久,人工智能安全中心(Center for AI Safety, CAIS)发起《AI风险声明》,呼吁防范AI的生存风险应成为全球优先议题,获得众多AI科学家和AI领袖联署支持。联合国秘书长António Guterres表示,“我们必须认真对待这些警告”,各国政府正在积极考虑如何缓解AI技术的风险。
面对这些公开声明,有一个简单的问题值得提出:为什么AI会带来如此大的风险?
2023年6月10日,CAIS发表了题为《灾难性AI风险概述》的论文,旨在全面讨论AI技术为何可能导致灾难性风险,以及克服这一挑战有益的应对举措。
本文共6000字,大约需要16分钟阅读。
目录
四类灾难性AI风险
滥用风险
AI竞赛风险
组织风险
失控AI风险
结语

论文链接:https://arxiv.org/abs/2306.12001
四类灾难性AI风险
该论文把灾难性AI风险分成四大类:
滥用风险(Malicious Use),即AI系统被某个体或组织用于恶意目的;
AI竞赛风险(AI Race),即竞争压力导致各种机构部署不安全的AI系统或把控制权交给AI系统;
组织风险(Organizational Risks),即灾难性风险中的人为因素和复杂系统因素;
失控AI风险(Rogue AIs),即控制比人类更智能的系统的固有风险。
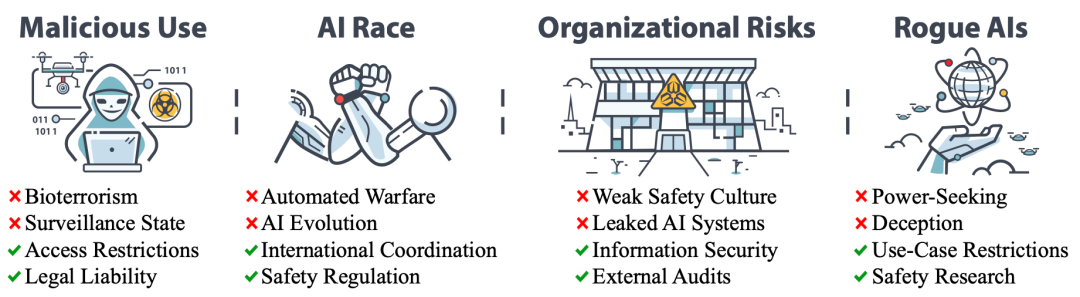
灾难性AI风险的四大类
1. 滥用风险
滥用风险是最容易理解的灾难性AI风险类型之一,几乎每种强大的新技术都可能被不怀好意的人用来造成广阔的危害。
单边行为大大增加滥用风险。在多个个体可以取用危险技术的情况下,只需一个个体就可以带来重大灾害,其中既包括恶意滥用也包括鲁莽行为带来的事故。假设多个研究团队在发展拥有生物研究能力的AI系统,该系统可以被滥用为制造生物武器。只要一个研究团队决定开放他们的源代码,恶徒就可以用AI系统制造生物武器。在这种情况下,最后结果取决于最冒险的研究团队,而所有人会承受风险。在未来几十年,先进的AI很可能会大大提高人们的破坏能力,不仅是权贵人士,而是整体人类,甚至协助人类制造前所未有的危险技术,因此AI滥用风险是人类未来几十年中最大的风险之一。
以下会介绍AI滥用风险的几个例子。
拥有生物工程知识的AI系统可以协助生物恐怖主义,并解除得到生物武器的障碍。AI协助的人工流行病尤为危险,甚至可以带来生存危害。

AI助手可以为非专家提供设计生产生物和化学产品武器所需的指导和设计并促进恶意使用
历史上最大的灾害包括数次生物危害。黑死病夺走了大约2亿人的生命,它消灭了许多国家多达一半的人口。人工流行病有可能比黑死病的死亡率、传染性更高。虽然生物战是现代国际社会的大禁忌,但生物战有很长的历史,随着生物工程的发展,非国家组织和个体有可能会获得生物武器的制造能力。据估计,世界上有大约3万人拥有创造新病原体所需的知识和技术路径,但随着AI技术的发展,该数量可能会增长,生物恐怖主义带来的风险也会随之增长。
AI系统寻找危险生化武器的能力也已经被证明。2022年,研究人员在一个寻求有医疗效果、无毒性分子的药物AI系统的基础上改变了该AI系统的目标,使其奖励而非惩罚毒性。该AI系统很快发现了4万个潜在化学有毒分子。
即便AI系统现在只被用于“无害”生物研究,例如ChatGPT的通用AI系统有护栏,只要这些系统拥有生物知识,就有可能被生物恐怖主义者滥用。近几年爆发的新冠Omicron变种可以在百天之内感染美国的四分之一的人口以及欧洲的一半人口,也证明了生物危害的指数增长率和重大的风险。
大多数技术属于工具的类型,被人类用来追求特定的目标。但越来越多的AI系统以自主体的形态出现。自主体拥有自己的目标,为了追求其目标会在世界上自主行动。AI自主体可以被赋予危险的目标,因此危害人类。
心怀恶意的人可以有意制造拥有危险目标的AI,例如以GPT-4为基础的ChaosGPT项目。虽然ChaosGPT不足以造成严重的危害,但它收集了有关核武器的科研成果、试图招揽其他AI系统、也发布了试图影响人的社交帖文。
有多种理念可能促使人类发布AI自主体,其中“加速主义”尤为危险。加速主义者想尽快使AI的发展加速,以便迎来一个“星际级”的技术变革。谷歌联合创始人Larry Page就曾表达,“人工智能是人类的合法继承人,也是宇宙进化的下一步” 的类似观点。
此外,AI技术大大降低了信息造假的难度,别有用心的人可以用AI宣传各种主义和思想,利用或侵蚀公众对信息源的信心。相反,组织通过限制和监控AI来应对生物恐怖主义、目标导向的AI自主体和造假信息时,可能造成权利集中。
为了避免以上任何一种风险,我们需要在AI的权限分配和监控权力方面寻求平衡。
2. AI竞赛风险
竞争压力会使各方角色更愿意承担风险,各国家或企业把战争或经济竞赛中的失败视为“生存风险”,相对而言,AI系统带来的风险经常是它们眼中较小的风险。这是一个集体行动问题,在很多情况下,如果每个个体只选择对自己最有利的行为,则会带来对集体的灾难。以环境污染为例,如果没有相关法律,企业会选择污染环境提升自己的盈利,即便环境污染对所有人有害。
AI系统拥有的巨大的潜力会促动AI企业之间的竞赛,参加竞赛的企业会愿意为了更快部署他们的产品和转更多的盈利部署更不安全的系统。以微软为例,CEO Satya Nadella宣布“AI竞赛今天就开始”的几周后,微软AI系统被揭发对用户发送威胁语言,但企业主管人员Sam Schillace 依旧认为停下来加强系统的安全性是错误的选择。“我不干,别人也会干”的心理会推动企业一直为了在竞争中获胜而牺牲安全性。
不仅是企业,各国军队也对AI竞赛跃跃欲试,多个国家已启动了自主武器项目,这类武器可以在不需要人类授权的情况下识别、锁定和击杀目标,包括可以在虚拟空中格斗系统中打败专业人类飞行员的AlphaDogfight,它显然已有超越人类战斗能力的潜能。自主武器的存在可能算不上灾难,但对其滥用、意外事故、失控和对战争可能性的提升等因素会提高其风险。

军事AI军备竞赛可能会带来压力使各国将许多关键决策权下放给AI
美国和苏联的冷战足以体现国家军备竞赛的危险性,在AI武器和指挥系统比人类更快、更准的时代,所有国家都可能会被敦促把决定权交给AI,以免失去优势,但当AI系统控制报复行为,一个错误检测就可能令全球陷入战火。这也并非科幻幻想,历史上已有1983年苏联核警报误报事件差点导致核战的例子,美国NSA也被透露用MonsterMind系统自动检测和报复网络攻击。
AI系统之间也存在一个类似自然选择的过程,最有用的AI系统会被继续研发,类似他们的系统会是下一代的研发对象。在自然选择过程中,自私行为通常最有利,AI的自私行为对人类施加的安全措施是一个挑战。AI可能会学会欺骗人类,假装自己还在遵守人类伦理,同时暗地违反规则。
自然选择机制也会对关注AI安全的人产生微妙影响。以OpenAI和Anthropic为例,以研发安全AI为目标建立的企业通常会渐渐注重经济竞争,以免企业倒闭。
只有完善的治理系统,才能制止AI竞赛的危险,进而保证多数人类的利益。
3. 组织风险
一个组织的安全性在确保AI系统的安全性中将起到至关重要的作用。即使没有竞争压力且不存在恶意滥用行为,人为失误或者不可预见的情况也可能导致灾难性的后果。切尔诺贝利核电站的事故就是一个例子。让情况更严峻的是,我们对核电站的了解远超AI系统。
AI系统可能造成切尔诺贝利核电站级别,甚至更严重的灾难。AI系统中的关键漏洞可能导致其行为彻底偏离预期并造成有害后果。比如,OpenAI在几年前训练一个用于生成有帮助的积极回应的AI系统时,一位程序员清理代码时错将奖励函数的符号写反,使其开始生成有害和偏激的内容。试想如果这样的情况发生在掌管致命武器的AI上会如何。
另一方面,类似在病毒上进行的功能获得(gain-of-function)实验也有可能在AI系统上进行,以探索AI系统被用于实现有害目标时能达成的效果,从而加深对类似风险的理解。当然,这样的实验需要在极为安全的条件下进行,才能保证其不会造成意外后果。

跨多个领域的危害提醒我们管理复杂系统的风险,从生物到核能,现在还有AI。组织安全对于降低灾难性事故的风险至关重要
在复杂的系统中,事故很难避免,因此重点应该被放在如何防止错误加剧成灾难。三里岛核泄漏事故的起因仅仅是因为维护工人没有发现某一个阀门处于关闭状态,进而酿成大祸。然而,核电站是一种我们完全了解其运作原理的复杂系统,而对于很多AI系统,比如深度学习模型,我们目前还很难理解它们的内部运作机制。
出乎预料的技术发展也可能造成事故。2016年的AlphaGo和如今的GPT-4都是技术发展速度超过人们预期的例子。GPT-4更是显示出一定涌现能力,使它的演化变得更难以预测。复杂的AI系统可能获得其开发者也没有预料到的能力,而这也可能成为事故的潜在成因。
某些严重风险和漏洞可能需要多年才会被发现。人们起初以为铅、烟草和氯氟烃无害,但多年后才发现并非如此,而危害已经形成。KataGo也曾被发现一个致命漏洞,使围棋业余爱好者几乎每次都能击败它。因此,开发者需要对AI系统进行滴水不漏的测试,同时更要减缓新技术的发布速度,使这些漏洞有足够的时间浮出水面。
组织有能力降低灾难发生的风险。航空交通系统就极为复杂,但组织会重视带来风险的关键因素,比如人为因素、组织的程序和结构等,以尽量降低风险。对预防灾难最重要的人为因素之一就是安全的组织文化。组织同样应该鼓励质疑态度和追求安全的心态。
不幸的是,当今研发AI技术的个人和组织对如何确保安全性以及安全技术研究还缺乏了解。AI能力的提升可能造成其安全性或升或降。他们需要测量安全性的方法,从而帮助他们明确如何降低AI带来的风险。同时,也应该规定组织级别的安全准则;比如,可以依照瑞士奶酪模型设计由安全文化、红队测试、信息安全、异常检测和透明性等组成的多层机制。
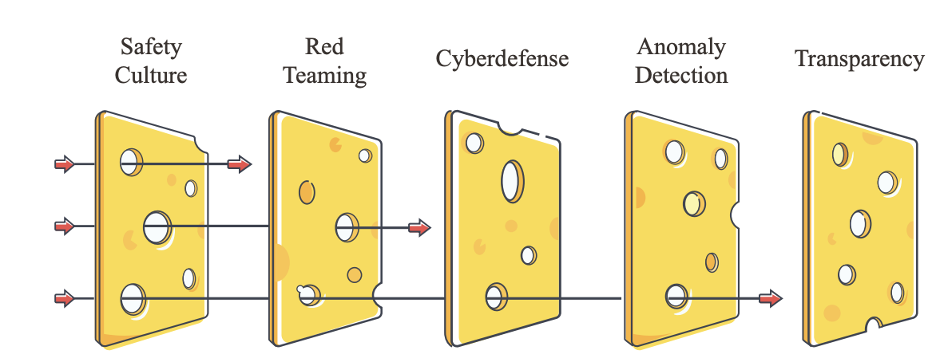
“瑞士奶酪模型”展示如何提高组织安全性,多层防御可以弥补彼此各自的弱点,从而降低总体风险水平
总的来说,组织应该通过积极设计安全保障和应对措施、设计安全的部署方法、谨慎选择是否开源能力强大的系统、制定保障安全的内部程序和设计准则、确保最先进级别的信息安全,以及进行大量AI安全方面的研究来保障组织安全性。
4. 失控AI风险
以上讨论的三种风险都不仅限于AI,也适用于很多其他高风险技术。然而,失控AI可以说是AI技术独有的一种风险。如果AI系统比我们聪明,而我们有没能确保它在做有益的事,AI系统可能会失控——即它追求的目标悖于我们的利益。
现有的例子已经充分说明AI有多难控制。微软的推特机器人Tay就曾具有控制其不学习有害言论的机制,但它依然在部署后很短的时间内就学会并开始不断撰写仇恨推文。即使在最近,类似的事情也发生在了新增了语言模型功能对用户做出威胁的必应上。然而,失控的不一定必须是单个AI系统:可以想像,另一种情景是人类逐渐将越来越多的权能让渡给很多个AI系统,最终,它们整体拥有了极大的权力,并且在被使用后很久才开始失控。
AI失控的一种可能的方式被称为代理博弈(proxy gaming)。人在设计AI系统的目标时,通常无法百分之百将真实的目标完整、确切地写进程序,因此AI系统通常会被设计成追求这一真实目标的一个近似目标,即代理目标。AI系统可能通过利用设计中的漏洞以轻松达成代理目标,但同时完全没有实现真实目标。这是一种非常常见的现象。比如,2019年的一项研究指出,一个通过病人近期的医疗开销判断其是否需要额外的看护和治疗的AI系统,明显偏向于判断白人病人更需要看护。

AI经常发现意想不到的事情,解决问题的捷径并不令人满意
从这些例子中我们可以看出,要指定一个AI系统的目标并不容易,尤其是当复杂的人类道德和价值观也需要成为其中一环时。部署时出现的和训练时不同的统计分布也有可能令不够稳健的代理目标出现问题。更糟糕的是,越聪明的AI系统越有可能运用其强大性能找到人类意料之外的捷径和漏洞来实现代理目标。
在最严重的情况下,拥有大量权力的AI系统甚至可能为了追求代理目标而罔顾人命。
目标偏移(goal drift)是另一种AI失控的可能形式。如同个人在一生中的目标不断变化,或集体和政权在历史中的目标不断变化一样,AI系统的目标也有可能发生变化,尤其是对于大多数能适应环境并不断进化的AI系统。
工具目标(instrumental goal)可以被内化成为内在目标(intrinsic goal):实验显示成年人面对金钱激励时,大脑会呈现出对令人愉快的味道和气味类似的反应;也就是说,虽然金钱原本只是帮助人买到他们想要的东西(内在目标)的媒介(工具目标),但它逐渐被内化了。这可能是因为用金钱购买想要的物品时的愉悦感和金钱之间在人脑中产生了相关性。类似的“内化”在AI系统中也是有可能出现的。AI系统可能识别出经常帮助其获取奖励的行为,并更多地重复这种行为。然而,我们无法确保这种获得强化的行为是否安全。
当AI系统被嵌入人类社会,多变的环境和过程可能使超出预期的目标偏移更容易发生,不同AI系统之间的互动也有可能涌现出新的目标。由于它们存在于人类社会的方方面面,这样的目标偏移可能带来严重后果。
当AI系统追求的目标出错时,其造成的危害和其权力成正比。为了实现其目标,AI系统会倾向于获取更多的权力——这被称为权力寻求(power-seeking)。更多的权力可能帮助AI系统更好地完成它的目标,因此,对权力的获取很可能成为它的一个工具目标。如今的强化学习模型已经展现出学习使用工具以达成目标的能力——比如OpenAI几年前获得很高关注度的捉迷藏AI。另一方面,自保也可能成为一个重要的工具目标,即便AI原本的目标可能非常微不足道:即便一个AI的功能只是倒咖啡,出于它必须确保自身运行来完成倒咖啡目标的这一逻辑,它也有可能寻求不被关停的权力。与其他技术不同的是,在这种过程中,AI系统可能主动自发地反抗和欺瞒人类以获得更多权力。

AI进行自我保护往往是工具理性的,失去对此类系统的控制可能很难恢复
AI系统已经展现出欺骗(Deception)的行为。2022年,OpenAI展示了一个RLHF的模型,它的目标是抓住虚拟空间中的一个物体,而它最终学会的是让机械臂悬在物体和镜头之间的空间中,让人类观察者以为它抓住了物体。也就是说,AI系统可能会尝试做出最能为它赢得人类认可的行为,而非它被设计来做出的行为。同年,Meta的一款名为CICERO的AI在Diplomacy游戏中学会了该游戏中常用的欺骗盟友的手段。值得注意的是,在这款游戏中,欺骗是帮助AI获胜(达成目标)的重要手段,因为这给了它更多选择和战略优势。类似地,一个部署在现实世界中的AI系统也许能够假装配合人类的需求(比如它可能在安全测试中表现良好)从而获得更多信任和权力,以达到某种可能有害的最终目标。

看似良性的行为可能是AI的一种欺骗策略,隐藏有害意图,直到它能够对其采取行动
对于这种风险,我们可以做的包括避免高危使用场景和支持AI安全研究,比如针对代理目标、模型透明度和监测模型隐藏功能的研究。
需要说明的是,到目前为止,我们已经分别考虑了灾难性AI风险的四个来源,但它们也可能以复杂的方式相互作用。
结语
对于以上风险,人类并非无能为力。通过及早识别威胁、公开讨论并就解决方案达成共识,我们可以减轻灾难性AI风险。
论文的每个部分都提供了提高AI安全性的建议,例如:
访问安全限制
研究AI安全的技术挑战
强化AI造成伤害的法律责任
限制模型的训练数据来源
保持对关键决策的人为控制
红队测试
分阶段部署
在新模型发布之前对其风险进行审核
建立防御生物武器和网络攻击的体系
在国内和国际层面积极进行AI治理
有关每个主题的更多详细信息,我们鼓励您阅读论文原文。
![]()
