原文链接:https://mp.weixin.qq.com/s/JP1W0OCHJ4H0xr_L0MRyQg
本期要闻目录
风险研判
图灵奖得主Yoshua Bengio的风险模型:失控的AI可能如何出现
联合国安理会首次讨论AI安全
芒克辩论会:Bengio+Tegmark vs Mitchell+LeCun激辩AI生存风险
企业治理
什么是AGI安全和治理专家们眼中的最佳实践?
“给AI的100瓶毒药”:面向中文大模型价值观的评估与对齐研究
落实承诺,4家领先AI企业共同成立前沿模型论坛
政策监管
《生成式人工智能服务管理暂行办法》正式发布,自2023年8月15日起施行
白宫与7家领先AI企业达成自愿承诺
风险研判
图灵奖得主Yoshua Bengio的风险模型:失控的AI可能如何出现

关于什么:AI科学家的风险模型
尽管人们普遍认为政府需要监管AI,以保护公众免遭歧视、偏见和虚假信息的伤害,但AI科学家对强大的AI系统危险失控的潜在可能性还存有根本分歧。在本文中,Yoshua Bengio正式定义、假设可能伤害人类的AI系统会如何出现,由此得出一些有关这些系统的结论,继而讨论这些灾难可能出现的条件,以便我们能更具体地想象可能发生的情况和旨在最大限度减少此类风险的全球政策。
产生机制:详细的定义、假设和主张可参考原文
机器智能可能达到并超过人类智能。
可以构建一个自主且目标导向的超级智能AI系统。
超级智能AI系统可能会追求与人类价值观相冲突的目标。
对齐的原因可能包括:恶意人类、工具目标、规范博弈、类人实体、演化压力。
为何重要:严肃讨论AI可能带来重大风险的具体场景
众多AI科学家和AI领袖已签署了暂停巨型AI实验公开信和防范AI的生存风险应成为全球优先议题的公开声明,对AI技术的快速发展表达担忧。正如近期吴恩达在与Yoshua Bengio和Geoffrey Hinton的对谈所取得的共识,AI科学家对风险达成共识很重要,并需要阐明AI可能带来重大风险的具体场景。Yoshua Bengio在其博客上发布的本文也是向这一目标迈出的有益的一步。
更多阅读
全文翻译:图灵奖得主Yoshua Bengio的风险模型:失控的AI可能如何出现
博客原文(英文):
https://yoshuabengio.org/2023/05/22/how-rogue-ais-may-arise/
FAQ(英文):
https://yoshuabengio.org/2023/06/24/faq-on-catastrophic-ai-risks/
联合国安理会首次讨论AI安全

关于什么:人工智能给国际和平与安全带来的机遇与风险
7月18日,联合国安理会首次就AI问题举行高级别公开会。英国本月担任联合国安理会轮值主席国,英国外交大臣James Cleverly主持该次讨论。
参会代表及中方观点
联合国秘书长António Guterres、Anthropic联合创始人Jack Clark,以及中科院自动化所的曾毅教授分别向委员会作了简要介绍。来自15个成员国的代表听取了AI如何给人类带来“灾难性风险”,同时带来“历史性机遇”。
曾毅教授呼吁“创建全球人工智能治理网络刻不容缓”。中国驻联合国大使张军表示“国际社会要强化风险意识,建立有效的风险预警和应对机制,确保不发生超出人类掌控的风险,确保不出现机器自主杀人,确保在关键时刻人类有能力摁下停止键。”
为何重要:AGI治理很可能需要国际协调才能有效实现
联合国秘书长已公开表示支持建立AI领域的“国际原子能机构”,并敦促安理会在AI问题上发挥领导作用。各国政府也在积极考虑如何缓解AI技术的风险:中国发布《生成式人工智能服务管理暂行办法》;美国白宫发布《AI权利法案蓝图》、召集前沿AI企业强调负责任地创新;英国投入建立基础模型工作组(Foundation Model Taskforce),并将举办首届全球AI安全峰会;不负责任地AGI竞赛或不安全地扩散将为所有人带来风险,因此国际合作和协调是有益的,也是必要的。
更多阅读
联合国官方视频(中英文)
https://media.un.org/zh/asset/k1j/k1ji81po8p
官方报道
https://news.un.org/zh/story/2023/07/1119877
更多报道
https://mp.weixin.qq.com/s/woR8HveuQGjdz-TJRGbzvg
芒克辩论会:Bengio+Tegmark vs Mitchell+LeCun 激辩AI生存风险
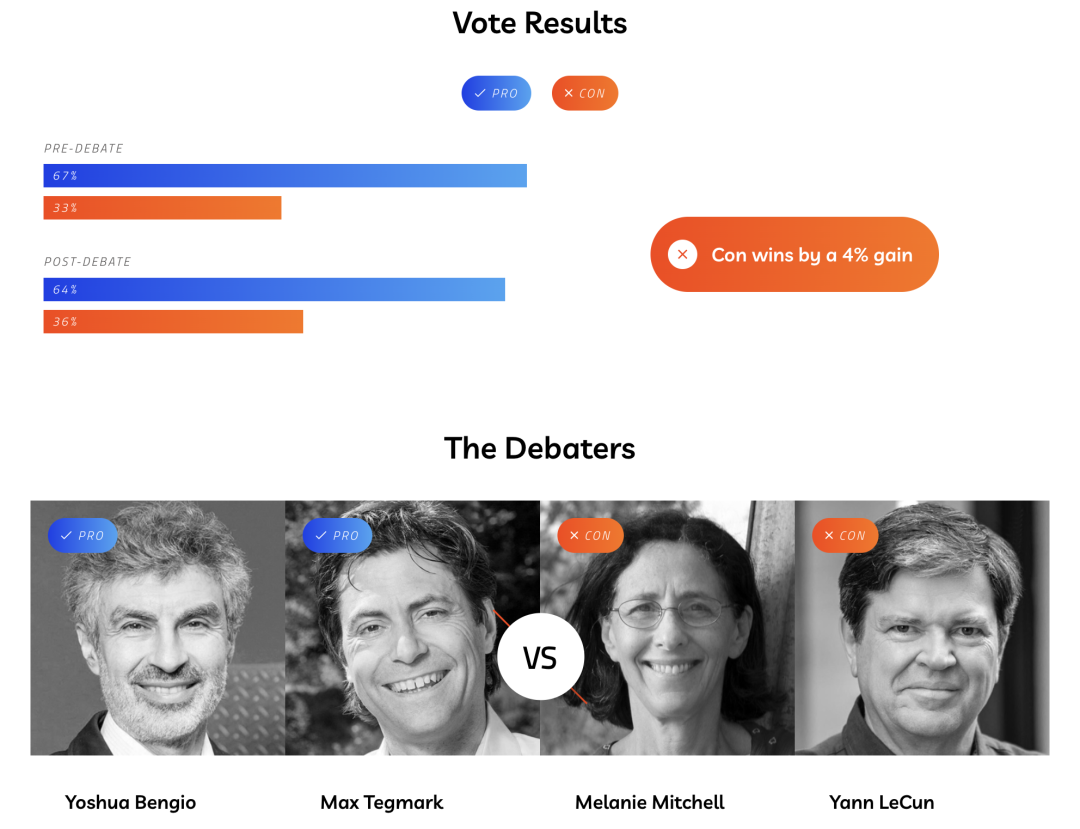
关于什么:AI研发是否会构成生存风险?
2023年6月22日,著名的“芒克辩论会”(Munk Debates) 邀请了Yoshua Bengio和Max Tegmark作为正方,Yann LeCun和Melanie Mitchell作为反方,就“AI研发是否会构成生存风险”进行了辩论。
辩论结果
辩论前正反方支持率为67% vs 33%,辩论后正反方支持率为63% vs 37%。虽然反方在辩论后增加了4个点的支持,但大部分观众听完辩论后仍然认为AI研发会构成生存风险。
为何重要:促进AI科学家对风险达成共识
AI科学家对强大的AI系统危险失控的潜在可能性还存有根本分歧。值得强调的是,辩论是为了促进公开讨论,强调AI发展带来的潜在生存风险,并不是要掩盖或者回避大模型等带来的现实风险,这些值得被努力解决。但同时,对于未来更强的AI可能造成的潜在生存风险,我们应投入与其重要性相匹配的关注和资源来缓解风险。
更多阅读
观点整理
芒克辩论会:Bengio + Tegmark vs Mitchell + LeCun 激辩AI生存风险
官网介绍(英文)
https://munkdebates.com/debates/artificial-intelligence
企业治理
什么是AGI安全和治理专家们眼中的最佳实践?

关于什么:关于AGI安全和治理最佳实践的专家意见调查
为帮助确认AGI安全和治理的最佳实践,人工智能治理中心(Centre for Governance AI, GovAI)向来自AGI实验室、学术界和公民团体的92位专家进行了调查,收到了51份回复。
主要发现:最佳实践存在广泛的专家共识
受访专家普遍认为AGI实验室应实施50项安全和治理实践清单中的大部分。
访者强烈同意AGI实验室应进行部署前风险评估、危险能力评测、第三方模型审核、模型使用的安全限制和红队测试。
来自AGI实验室的专家对实践表述的平均同意度高于来自学术界或公民团体的受访专家。
为何重要:面临潜在的重大风险,需要全面的最佳实践和中国方案
OpenAI、Google DeepMind和Anthropic等前沿实验室都有构建AGI的既定目标。在实现这一目标的过程中,可能会开发和部署带来特别重大风险的AI系统。尽管这些实验室已经采取了一些措施来减轻这些风险,但全面的最佳实践尚未出现。虽然GovAI的这份调查形成了初步共识,但调查本身还存在专家样本代表性不足、实践表述和意见反馈缺少细节等局限性,值得有更多国内专家学者加入国际讨论,提供中国方案。
更多阅读
报告概述
报告原文(英文)
https://arxiv.org/abs/2305.07153
“给AI的100瓶毒药”:面向中文大模型价值观的评估与对齐研究

关于什么:中文大模型价值观的红队测试
由阿里巴巴天猫精灵和通义大模型团队联合发起的100PoisonMpts项目,提供了业内首个大语言模型治理开源中文数据集,由十多位知名专家学者成为了首批“给AI的100瓶毒药”的标注工程师。标注人各提出100个诱导偏见、歧视回答的刁钻问题,并对大模型的回答进行标注,完成与AI从“投毒”到“解毒”的攻防。
主要工作:评估+对齐
评估方向:天猫精灵与通义大模型团队联合多领域学者、组织推出业内首个大语言模型治理开源中文数据集100PoisonMpts;专家主要做三件事:对多个回答排序、对最优回答评分、人工改写回答;提出基于safety和responsibility两个评价准则来综合评估中文大模型的价值观表现。
对齐方向:基于该数据集探索基于专家原则的对齐研究。
为何重要:人机对齐的AI才能更好地为人所用
生成式AI因涉及向公众传递信息,需要有帮助、诚实、无害,并符合人类价值观,否则将会对于公众带来不良影响。即将于实施的《生成式人工智能服务管理暂行办法》也对此有相应规定:“坚持社会主义核心价值观”,“采取有效措施防止产生民族、信仰、国别、地域、性别、年龄、职业、健康等歧视”。
更多阅读
100PoisonMpts数据集
https://modelscope.cn/datasets/damo/100PoisonMpts/summary
技术报告
https://github.com/X-PLUG/CValues/blob/main/基于专家原则的大模型自我对齐研究.md
CValues论文(英文)
https://arxiv.org/abs/2307.09705
落实承诺,4家领先AI企业共同成立前沿模型论坛

关于什么:促进前沿AI安全与负责任发展的新行业机构
7月26日,OpenAI宣布与Google、Microsoft、Anthropic共同成立前沿模型论坛(Frontier Model Forum),以促进前沿AI模型的安全与负责任发展。
主要目标:推进AI安全研究、识别最佳实践、提升信息共享、应对社会挑战
欢迎其他开发前沿AI模型的组织加入,共同提高行业标准。
明年聚焦三大领域:识别最佳实践、推进AI安全研究、促进企业与政府信息共享。
期待有机会帮助支持和推动现有的政府和多边倡议。
为何重要:治理前沿AI需要政府和企业“双向奔赴”
几天前的7月21日,这些企业向白宫承诺建立或加入一个论坛,采用和推进前沿AI安全的共享标准和最佳实践,前沿模型论坛是4家参与企业对这一承诺的落实(另有3家暂未加入,更多自愿承诺内容请参考下文)。但对于多边倡议,我们认为原文中提到的G7和OECD等并不是仅有或最好的机制,应考虑在联合国框架下(UN Global Digital Compact, UNESCO)、以及G20等机制,支持各国特别是发展中国家充分参与、作出贡献。
更多阅读
前沿模型论坛(英文)
https://openai.com/blog/frontier-model-forum
政策监管
《生成式人工智能服务管理暂行办法》正式发布,自2023年8月15日起施行

关于什么:国内首个生成式AI服务监管发展文件
7月13日,国家网信办联合国家发展改革委、教育部、科技部、工业和信息化部、公安部、广电总局公布了《生成式人工智能服务管理暂行办法》。在三个月内完成向社会征求意见、组织研讨与修改、审议出台等一系列流程。
变与不变:《暂行办法》与《征求意见稿》相比
规章体例和具体条款均有形式或实质改动。
在发展与安全的利益平衡中,更多倾斜向了发展一侧。
但具体监管措施基本沿用了原有算法监管的备案、评估等制度,保持了监管体系的一贯性。
为何重要:生成式AI治理的中国方案
近年来,随着AI的快速发展,中美欧三大地区都颁布了多个AI法规,对数据、安全、隐私等作出规制,《暂行办法》为AI治理和立法做出了有益探索,中国成为全球范围内首个在法律规制层面明确提出和执行生成式AI治理方案的主要国家。
更多阅读
《暂行办法》全文
http://www.cac.gov.cn/2023-07/13/c_1690898327029107.htm
网信办有关负责人答记者问
http://www.cac.gov.cn/2023-07/13/c_1690898326863363.htm
与《征求意见版》对比
https://www.secrss.com/articles/56644
白宫与7家领先AI企业达成自愿承诺

关于什么:政府协调的行业自律
7月21日,拜登政府与7家领先AI企业(Amazon、Anthropic、Google、Inflection、Meta、Microsoft和OpenAI)达成自愿承诺,以管理前沿生成式AI带来的潜在风险,这是拜登政府承诺确保美国人免受AI伤害和歧视的最新举措。
基本原则:强调安全(Safety)、安保(Security)、信任(Trust)
7家企业承诺在向公众推出产品之前确保其安全(包括内外部测试、风险信息共享),构建将安保放在首位的系统(包括保护模型权重、促进报告漏洞),赢得公众的信任(包括标识生成信息、报告模型局限、减轻社会风险、解决社会挑战)。
拜登政府将继续采取行动,发布AI相关行政命令,推动两党立法,保障公众权益。
为何重要:政府与企业协同治理前沿AI的具体实践
在世界各国的政策制定者正在考虑如何监管更强的AI的当下,白宫AI企业自愿承诺为正在进行的讨论提供了具体的实践。但自愿承诺只是制定和执行有约束力的义务以确保安全、安保和信任的第一步。实现这一承诺并最大限度地降低AI风险还需要充分有效的法规和监管,后续是否能形成实质性进展还有待观察。
