原文链接:https://mp.weixin.qq.com/s/Mqgc6t8UXhoc-tdeKer-Fg
原创 新智元
新智元报道
新智元导读】LeCun的世界模型终于来了,可谓是众望所归。既然大模型已经学会了理解世界、像人一样推理,是不是AGI也不远了?
长久以来,LeCun理想中的AI,一直是通往人类水平的AI,为此他提出了「世界模型」的构想。而最近,LeCun在公开演讲中,再次批评了GPT大模型:根据概率生成自回归的大模型,根本无法破除幻觉难题。甚至直接发出断言:GPT模型活不过5年。

今天,LeCun终于离自己的梦想又近了一步!Meta震撼发布了一个「类人」的人工智能模型 I-JEPA,它可以比现有模型更准确地分析和完成缺失的图像。

论文地址:https://arxiv.org/abs/2301.08243划重点:I-JEPA填充缺失片段时,用的就是有关世界的背景知识!而不是像其他模型那样,仅仅通过查看附近的像素。距离提出「世界模型」概念一年多,眼看着LeCun就要实现自己的星辰大海了。今天,训练代码和模型已经开源。论文将于下周在CVPR 2023发表。
LeCun的世界模型来了
即使是如今最先进的AI系统,也始终无法突破一些关键限制。为了突破这层桎梏,Meta的首席AI科学家Yann LeCun提出了一种新的架构。
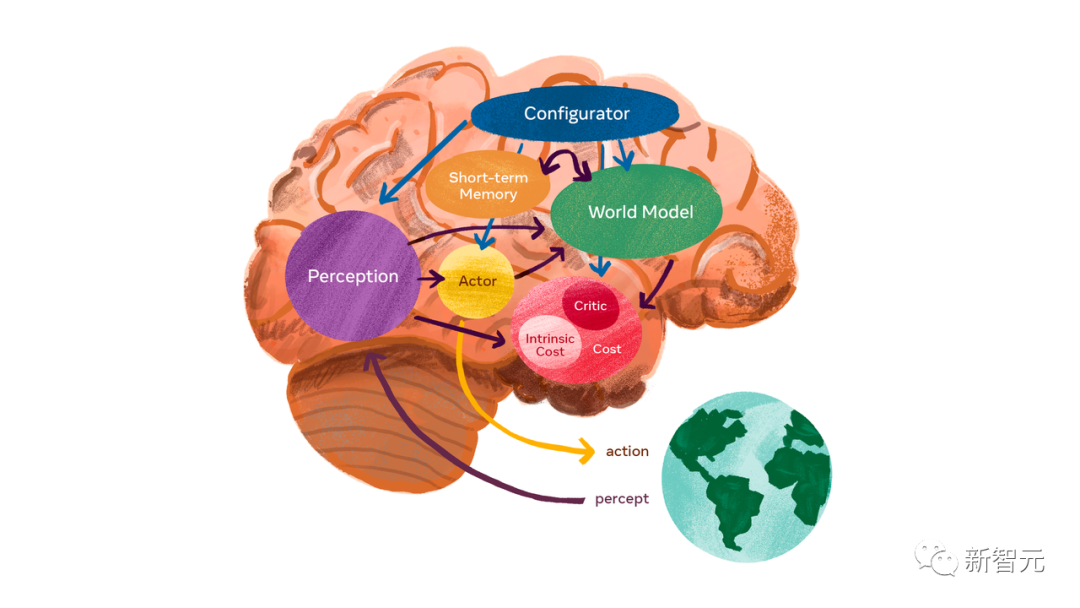
他的愿景是,创造出一个机器,让它能够学习世界如何运作的内部模型,这样它就可以更快速地学习,为完成复杂任务做出计划,并且随时应对不熟悉的新情况。今天Meta推出的图像联合嵌入预测架构I-JEPA模型,是史上第一个基于LeCun世界模型愿景关键部分的AI模型。I-JEPA就是通过创建外部世界的内部模型来学习。在补全图像的过程中,它比较的是图像的抽象表征,而不是比较像素本身。在多个计算机视觉任务上,I-JEPA都表现出了强大的性能,并且比其他广泛使用的CV模型计算效率高得多。
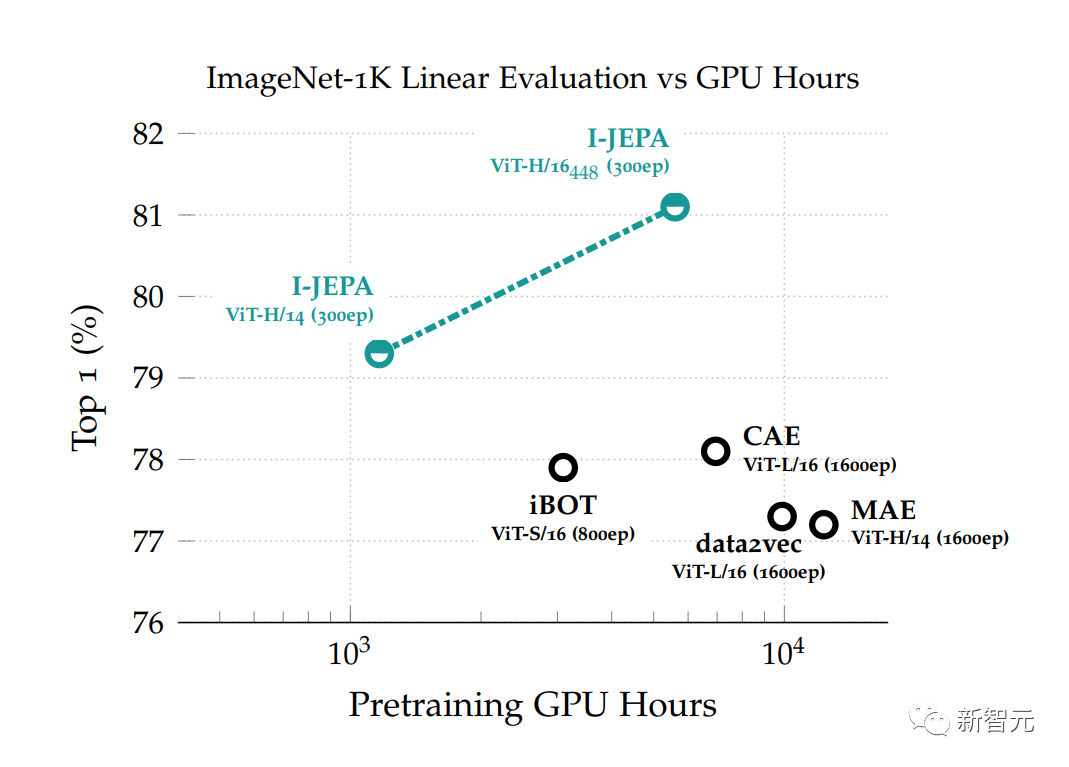
ImageNet线性评估:I-JEPA方法在预训练期间不使用任何视觉数据增强来学习语义图像表征,使用的计算量比其他方法更少I-JEPA学习的表示形式可以用于许多不同的应用,而无需进行大量的微调。比如,研究者在72小时内使用16个A100 GPU,就训练出了一个632M参数的视觉Transformer模型。在ImageNet上的low-shot分类任务上,它达到了SOTA,每个类降低到12个标记示例。而其他方法通常需要2到10倍的GPU小时,并且使用相同数量的数据进行训练时,错误率也更高。
通过自监督学习获取常识
通常,人类只要通过被动观察,就能学习到有关世界的大量背景知识。根据推测,似乎这种常识信息正是实现智能行为的关键,比如获取新概念、基础和计划的有效样本。

将概念学习建模为学习一个线性读数Meta在I-JEPA(以及更普遍的联合嵌入预测架构JEPA模型)上的工作,正是基于这样一个事实。研究者尝试的是,设计出一种学习算法,捕捉关于世界的常识背景知识,然后将其编码为算法可以访问的数字表征。为了达到足够的效率,系统必须以自监督的方式学习这些表征——也就是说,直接从图像或声音等未标记的数据中学习,而不是从手动组合的标记数据集中学习。在更高的层级上,JEPA旨在根据同一输入(图像或文本)的其他部分的表征,来预测输入的部分表征。因为它不涉及将图像的多个视图/增强的表征折叠到一个点上,所以JEPA有很大希望能够避免在广泛使用的方法(即基于不变性的预训练)中出现的偏见和问题。

联合嵌入方法可以避免表征崩溃
同时,通过在高度抽象的水平上预测表征,而不是直接预测像素值,JEPA有望能够直接学习有用的表征,同时避免生成方法的局限性,正是基于这个原因,最近才产生了如此多令人兴奋的大语言模型。相比之下,一般的生成式模型是通过移除或扭曲输入模型的部分内容来学习的。例如,抹去照片的一部分,或者隐藏文本段落中的某些字,然后试着预测被破坏或丢失的像素或单词。但这种方法的一个显著缺点是,尽管世界本身是不可预测的,模型却试图填补每一块缺失的信息。

因而,这种方法可能会犯人永远不会犯的错误,因为它们会过于关注不相干的细节,而不是捕捉更高级的可预测的概念。一个众所周知的例子就是,生成式模型很难生成正确的人手。在自监督学习的通用架构中,系统会学习捕捉不同输入之间的关系。它的目标是,将高能量分配给不兼容的输入,将低能量分配给兼容的输入。
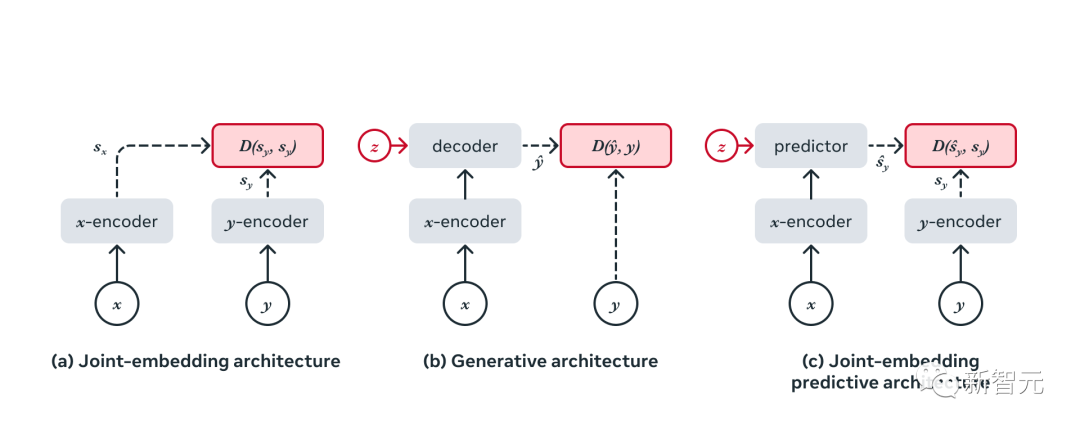
自监督学习的常见架构这三种架构的区别是——(a) 联合嵌入(不变)架构会学习为兼容的输入x、y输出相似的嵌入,为不兼容的输入输出
相似的嵌入。(b) 生成式架构会学习直接从兼容的信号x重建信号y,使用以附加变量z(可能是潜变量)为条件的解码器网络,以促进重建。(c) 联合嵌入预测架构学习从兼容信号x中预测信号y的嵌入,使用以附加变量z(可能是潜变量)为条件的预测网络,来促进预测。
联合嵌入预测架构
I-JEPA背后的原理是通过一种更类似于人类理解的抽象表征来预测缺失的信息。为了引导I-JEPA产生语义表征,其中一个核心设计便是多块掩码策略。具体而言,团队证明了预测包含语义信息的大块的重要性。这些大块具有足够大的规模,可以涵盖重要的语义特征。
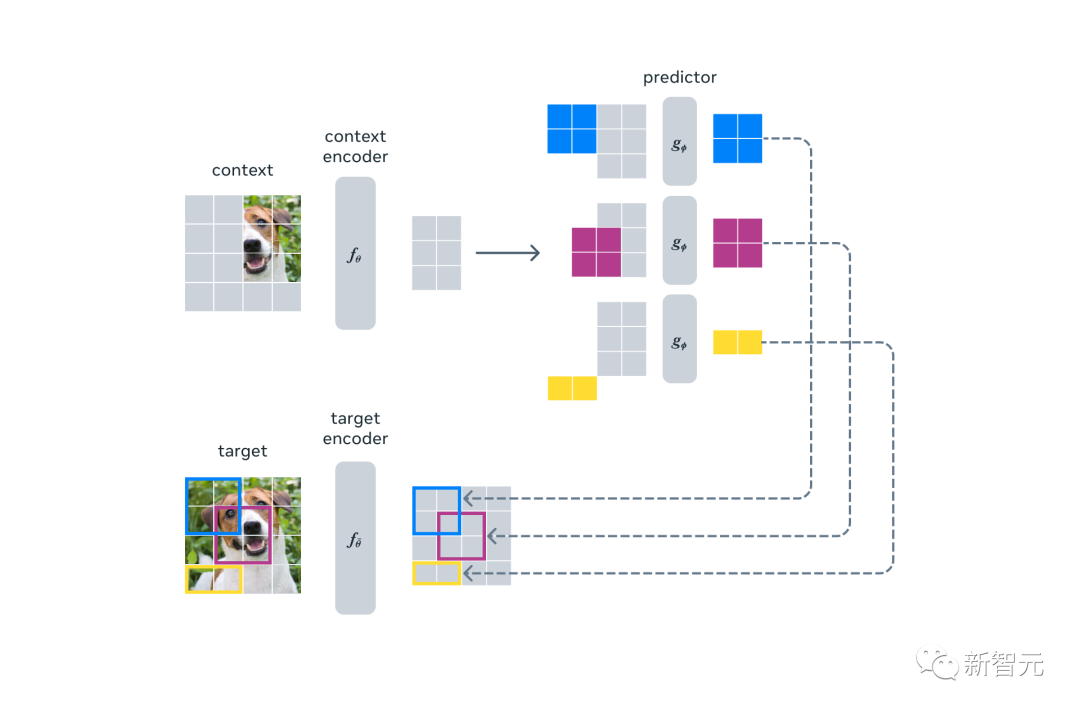
这种策略的优势在于,它能够减少不必要的细节,并提供更高层次的语义理解。通过关注大块的语义信息,模型可以更好地抓住图像或文本中的重要概念,从而实现更强大的预测能力。基于图像的联合嵌入预测架构(I-JEPA)使用单个上下文块来预测来自同一图像的表征其中,上下文编码器是一个视觉Transformer(ViT),它只处理可见的上下文patch。预测器是一个窄的ViT,它接收上下文编码器的输出,并根据目标的位置token,来预测目标块的表征。

目标表征对应于目标编码器的输出,其权重在每次迭代时,通过对上下文编码器权重的指数移动平均进行更新。在I-JEPA中,预测器可以被视为一个原始(且受限)的世界模型,它能够利用已知的上下文信息来推断未知区域的内容。这种能力使得模型能够对静态图像进行推理,从而建立一种对图像中的空间不确定性的理解。与仅关注像素级细节的方法不同,I-JEPA能够预测未见区域的高层次语义信息,从而更好地捕捉图像的语义内容。

预测器学习建模世界语义的过程对于每个图像,蓝色框之外的部分被编码并作为上下文提供给预测器。而预测器则输出了代表蓝色框内预期内容的表征。为了理解模型捕捉的内容,团队训练了一个随机解码器,将I-JEPA预测的表征映射回像素空间,从而展示了在蓝色框内进行预测时模型的输出。显然,预测器能够识别出应该填充部分的语义信息(狗头顶部、鸟的腿、狼的腿、建筑物的另一侧)。

给定一幅图像,随机采样4个目标块,随机采样一个范围尺度的上下文块,并删除任何重叠的目标块。这种策略下,目标块相对语义化,上下文块信息量大,但很稀疏,因而处理效率高简而言之,I-JEPA能够学习对象部分的高级表征,而且也不会丢弃它们在图像中的局部位置信息。
更高的效率,更强的性能
在预训练上,I-JEPA的计算更加高效。首先,它不需要应用更加计算密集的数据增强来生成多个视图,因此不会带来额外的开销。其次,其中的目标编码器只需对图像的一个视图进行处理,而上下文编码器也只需对上下文块进行处理。实验证明,I-JEPA能够在不使用人工视图增强的情况下,学习到强大的现成语义表征。此外,在ImageNet-1K线性探测和半监督评估中,I-JEPA的表现也优于像素重建和token重建方法。

在预训练过程中,以GPU小时数为函数的基准,在ImageNet-1k上进行线性评估的性能在语义任务上,I-JEPA与之前依赖于人工数据进行增强的预训练方法相比,表现更加出色。与这些方法相比,I-JEPA在低级视觉任务(如物体计数和深度预测)上实现了更好的性能。通过使用更简单、更灵活的归纳偏置模型,I-JEPA可以用在更广泛的任务上。
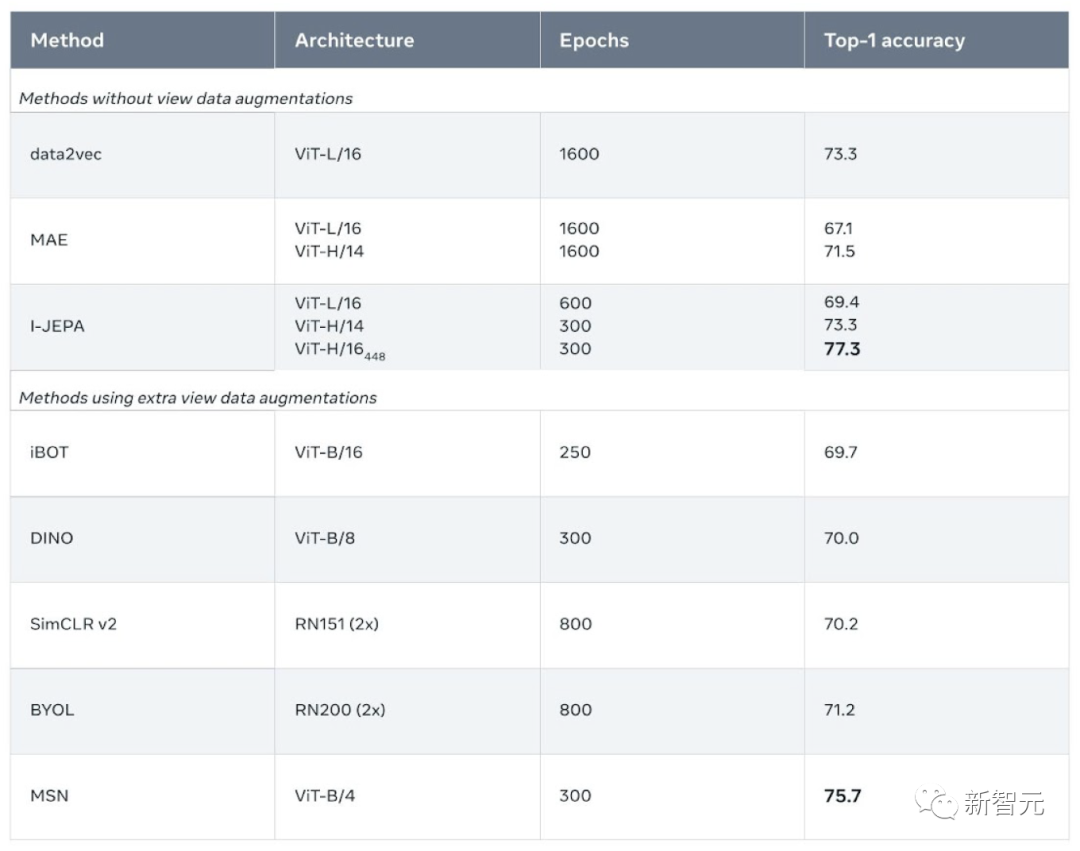
低样本分类准确率:对ImageNet-1k进行半监督评估,使用1%的标签(每个类别大约有12张带标签的图像)
AI向人类智能更进了一步
I-JEPA展示了架构在学习现成图像表征方面的潜力,而且还不需通过人工制作的知识作为额外的辅助。推进JEPA以从更丰富的模态中学习更通用的世界模型,将会是一样特别有意义的工作。例如,从短的上下文中,对视频进行长程的空间和时间预测,并将这些预测基于音频或文本提示进行条件化。

I-JEPA预测器表征的可视化:第一列包含原始图像,第二列包含上下文图像,绿色边界框包含来自预测器输出解码的生成模型的样本。预测器正确捕捉了位置的不确定性,以正确的姿态产生了高级对象的部分,丢弃精确的低级细节和背景信息团队表示,期待着将JEPA方法扩展到其他领域,如图像-文本配对数据和视频数据。未来,JEPA模型会在视频理解等任务中可能具有令人兴奋的应用。而这也将是应用和扩展自监督方法来学习世界模型的重要一步。
预训练模型
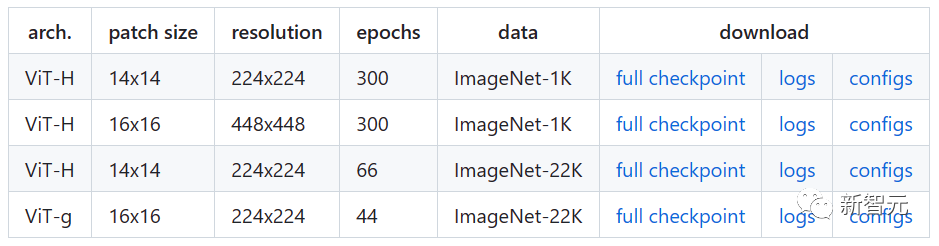
单GPU训练
在单GPU设置中,实现从main.py开始。例如,要使用配置configs/in1k_vith14_ep300.yaml在本地计算机上的GPU 0、1和2上运行I-JEPA预训练,请输入以下命令:
python main.py \ --fname configs/in1k_vith14_ep300.yaml \ --devices cuda:0 cuda:1 cuda:2
注意:ViT-H/14配置应在16个A100 80G显卡上运行,有效批大小为2048,才能复现结果。
多GPU训练
在多GPU设置中,实现从main_distributed.py开始,除了解析配置文件外,还允许指定有关分布式训练的详细信息。对于分布式训练,需要使用流行的开源submitit工具,并提供SLURM集群的示例。例如,要使用configs/in1k_vith14_ep300.yaml中指定的预训练实验配置在16个A100 80G显卡上进行预训练,请输入以下命令:
python main_distributed.py \ --fname configs/in1k_vith14_ep300.yaml \ --folder $path_to_save_submitit_logs \ --partition $slurm_partition \ --nodes 2 --tasks-per-node 8 \ --time 1000
网友评论
对于LeCun领衔的这项新工作,网友们纷纷表示赞赏。真是开创性的工作,吹爆了。自回归模型的继任者就在这里!

我相信,联合嵌入架构是人工智能的未来,而不是生成式的。但我就是很好奇,为什么我们不进一步研究多模态(如ImageBind,而不仅仅是文本-图像对),并且用像编码器这样的感知器来代替VIT编码器?
很简洁的工作。在我的理解中,它类似于掩蔽自动编码器,但在潜在空间中定义时会丢失功能,而不是输入/像素空间。不过,如果要详细看懂,我还需要更多细节。

我的大脑只能看懂论文的10%,但如果I-JEPA真的能创建图3中的目标图像,那就太神奇了,最重要的是:它和AI生成的MMORPG是相关的!

这个项目即将开源,网友也对Meta对于开源社区的贡献表示赞赏。

参考资料:https://ai.facebook.com/blog/yann-lecun-ai-model-i-jepa/
