原文链接:https://mp.weixin.qq.com/s/_dONQQuUXlR8wh11MY2FYg
原创 李容佳 清华大学智能法治研究院
偏见是人类固有的,人类社会的偏见在AI出现之前就已产生,这源于我们的文化和历史,而AI只是这种偏见或者歧视的反映。因此,不应过分批评AI系统决策所产生的偏见,更不能因噎废食,放弃AI的扩大应用。人类应通过充分的监督和审计,尽可能使用所有手段来减轻这种偏见,以期在将来的某个时刻,AI系统作出的决策将比人类决策更加公平。欧洲议会未来与科学和技术小组(STOA),于2022年7月发布了一份关于审计算法决策所使用的数据集质量的研究报告[1],其中阐述了AI决策偏见的形成,并讨论了几种政策选择,以减少AI的决策偏见。
1
AI决策偏见的形成
在AI开发过程的各个阶段都可能引入了偏见,Baeza-Yates根据偏见的起源定义了其类别:数据、算法和用户交互[2];Sures和 Guttag从数据生成、模型开发及部署两阶段出发,定义和分析了机器学习中可能存在的五种偏见[3],本文主要聚焦于算法决策所使用的数据集的审计。获得有偏见的结果与数据的特征以及数据的管理过程密切相关,包括数据收集、清洗、标注和处理。而数据应用的质量,与知识表示方法的准确性有关(例如,数据的属性,可能的稀疏性或异质性,社会群体的代表性不足等)。这些因素将影响AI系统决策的准确性,可靠性和可信度等方面。
计算机信息化系统中的数据分为结构化数据和非结构化数据(见下图)。结构化数据包括日期,联系信息,人口统计数据和财务信息等;非结构化数据例如,图像,视频等;半结构化数据包括HTML,XML,JSON文件等。在模型开发阶段,由于入模数据必须是结构化数据,所以需要进行数据的转化,在处理非结构化数据时,就可能会引入偏见。例如,在对敏感信息(例如性别或种族)进行分类时,如果AI没有形成客观的视觉特征和认识,就无法正确标记这些数据,从而将偏见引入决策模型。例如,美国惩教罪犯管理档案软件,在衡量一个人犯另一种犯罪的风险时,已被发现对非裔美国人有负面偏见;Google Cloud Vision在对温度计进行标识时,也存在可怕的偏见,它把一个黑人手拿温度计的图像标记为“持枪”,而将白人的类似图像标记为“手拿电子设备”。[4]
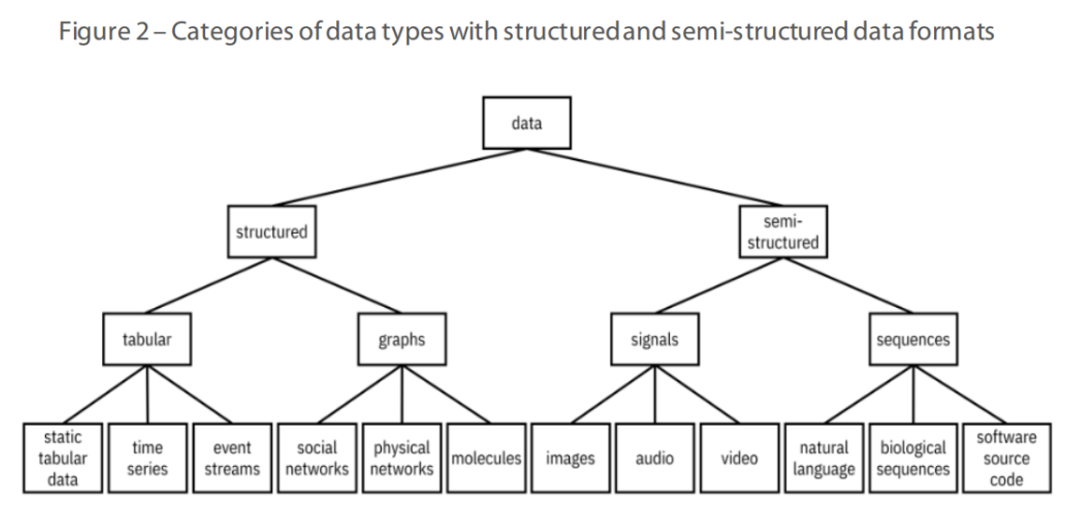
(数据的分类图)
在模型验证阶段,开发人员将测试和验证基于人工智能的解决方案,并微调模型,这时来自开发人员自己的认知和文化偏见可以进入这个模型。另一方面,当开发人员没有检测到有偏差的结果时,就会发生盲点偏差。IBM、微软和旷视开发的一些面部识别系统就在这一阶段出现了偏差。
在模型部署阶段,利益相关者和最终用户会审查基于AI的解决方案,并提供反馈,这时对于模型的修改,可能和降低成本或开发者的资本预算冲突,在经济利益的衡量下,可能算法中的偏见将不会被完全修改。
欧盟一直在尽可能地减少人工智能决策的偏见,这是一项具有挑战性的任务。因为偏见是一个复杂的概念,设计针对纠正偏见的监管框架并不容易,然而当前我们能够实现的是:提高科学界、技术行业、决策者和公众的认识;采用适当基准检验人工智能的决策的公平性;在人工智能实施中纳入关键的伦理考虑,确保系统最大限度地提高整个人类的健康和福祉。实现这些目标有不同方法:例如,可以通过完善当前的法规,来消除在宗教或信仰,疾病,年龄或性取向的不合理差别,根据理事会指令,实施平等待遇原则;也可以考虑能够应对歧视问题的法律替代工具。
目前已有一些纠正AI系统中偏见的技术,通过决策前处理,决策中进行处理或决策后处理,以实现更大的决策公平性,但是对于数据集的审计仍然缺乏公认的标准。以下是STOA提出的政策选择及其相应的优劣分析。
2
政策选择及其评估
1. 不需要针对歧视问题的专门立法
解决偏见问题,最先想到的是针对这个问题制定具体的立法。然而,这种普遍性的法规是很难设计的,因为定性和定量的数据差异很大,而且由对话记录(自然语言)组成的数据库与由数字或包含图像组成的数据库是不同的,所以针对数据的偏差引入特定的调控并不是一个好主意,而不如利用已经存在的规定。目前,针对数据和人工智能的监管工具已经提出了多个建议,如《通用数据保护条例》(GDPR)、《关于在欧盟全境实现高度统一网络安全措施的指令》(NIS2指令)、《数据法》、《数据治理法》、《数字市场法》、《数字服务法案》和《人工智能法案》[5],对这些法律文件进行小幅度的修改,并解决不同规则之间的不协调问题(例如有公司可能会发现自己同时违反了《AI法案》、GDPR和一般产品安全法规),就可以作为制定新立法的替代方案。在未来,欧盟可能会更专注于解决不同监管工具之间的失调问题。
2. 在数据收集阶段减少歧视和偏差
应用减轻偏见的最佳做法是预防偏见的产生,例如在数据收集时尊重公平原则,以引入更好的数据治理标准和审计来整合它们的数据库。数据收集应该符合FAIR原则(可查找、可访问、可互操作和可重复使用)。当然,这要求充分收集数据特征的信息,即数据结构、数据格式、词汇表、分类方案、分类和代码列表,这些应该以公开和一致的方式进行描述。
减轻偏见的重要步骤是创建或使用高质量的特定领域数据集,向AI的系统准确地描述“公平”的概念。GDPR定义的“公平”概念,可以成为对抗偏见的极好工具。然而,GDPR对算法系统产生的多种形式的不公平待遇的应用有限,主要表现在它无法规制不包含个人数据的数据库。匿名化技术有利于保护隐私,但是个人使用这些数据时,并不能防止偏见的复制。GDPR原则上不适用于匿名数据,这进一步加剧了这种情况。因此,如果个人数据处理涉及人工智能法案的高风险,应该将个人数据处理的预防扩展到匿名、非个人数据处理。
同时,应实施监督和问责制的机制,以不断评估数据的质量和完整性。创建适用于数据集和人工智能机制的标准,是监管的一个基本要素。然而,无论是在数据集还是在人工智能领域,它们都处于早期阶段。与数据集相关的标准应包括关于数据集内容、使用限制、许可证、数据收集方法、数据质量和不确定性的信息。另一方面,与数据集和人工智能工具相关的标准化和认证必须具有灵活性,以便能够包括在人工智能应用程序中使用的各种可能的数据格式和集合。
但是应当认识到,在预处理阶段缓解偏差的技术效果有限;这些技术的应用并不意味着使用和部署使用这些数据的系统不会导致有偏见的结果。因此,在这个阶段进行的任何类型的认证都应该考虑到这些限制,并在开发、部署和使用这些认证数据库时,组织相关培训,并及时与利益相关者进行沟通。
3. 推进数据集的认证
这个政策选择旨在从算法系统生命周期的开端,对所使用的数据集进行认证,从而规制可能存在的偏见。为数据集引入相关证明,主要包括两个方面:首先,证明数据集开发人员已经应用了最佳的方法,以避免存在显著的偏差;第二,证明数据集开发人员提供了关于数据集的准确信息,这可能会阻止其他利益相关者以有偏见的方式,开发或使用数据集和算法系统,其他数据处理者也可以对这些证明予以补充。
认证有强制性和自愿性两种模式:第一种可能的选择是对于高风险人工智能系统的数据库,进行强制性的认证。在这种情况下,无论出于何种目的,用于开发高风险人工智能系统的数据库,都必须进行认证。这种认证可以由数据库提供商,或由人工智能系统提供商进行认证。这将实现《人工智能法案》所规定的,认证前和认证后的责任分离,以及第10条的数据治理责任,即“开发高风险AI系统,应满足培训、验证和测试数据集的相关标准”。强制性认证增加了数据集的可靠性,然而却伴随着更高的成本,特别是在第三方提供认证的情况下。
另一个可能的选择是高风险人工智能系统数据库的自愿认证,让人工智能系统提供商提供其遵守法规的证明。在市场上引入这种认证,可以为取得认证的人工智能系统提供商,创造更多的竞争优势。
目前已有的认证有欧盟委员会层面(Cihonet al, 2021)的认证以及电气和电子工程师学会[6]的认证标准。但是目前还没有公认的数据质量评估标准,欧洲委员会可根据《欧洲标准化条例》第10条,要求欧洲标准化组织起草符合《数据法》第29条第1款规定的基本要求的协调标准[7],这些标准应包括数据集内容、使用限制、许可证、数据收集方法、分类方案、数据质量和不确定性的信息,所有这些信息应充分描述,以便接收者查找、访问和使用数据。这与欧盟基本权利机构(EU Agency for Fundamental Rights)定义的数据质量的最低标准非常类似:这些数据来自哪里?谁负责数据的收集、维护和传播?这些数据中包含了哪些信息?数据中所包含的信息是否适合于该算法的目的?这些数据中涵盖了谁?谁在数据中的代表不足?数据集中是否缺少信息,或者是否只有部分覆盖?用于构建应用程序的数据收集的时间框架和地理覆盖范围是什么?此外,数据集的标准化必须允许有灵活性,以便能够包括在人工智能应用程序中使用的各种可能的数据格式和集合。
4. 为受人工智能决策影响的主体提供数据访问权
在这个政策选项下,受人工智能决策影响的主体,对于模型训练的数据集的信息具有访问权。根据GDPR第15条的规定,数据主体有权访问已被数据控制者收集的个人数据,以便了解和验证有关数据处理行为的合法性。并且,数据控制者应当在合理的时间内满足数据主体的这种访问请求。GDPR规定的可以访问的信息包括“关于自动决策和配置分析中所涉及的有意义的信息”,并没有涉及到训练数据集的信息,而数据集才是自动化处理的关键。因此,数据主体根据GDPR检查其数据处理是否合法、公平或准确的能力是有限的。
为受人工智能决策影响的主体提供数据访问权,可以帮助寻找有偏差的结果来源,所以有必要确保这种信息访问权,扩展到混合决策或决策支持系统,而不是仅仅基于自动处理的决策(违反GDPR中第13(2)(f)、14(2)(g)和15(1)(h))。访问的信息至少应该包括关于使用生成决策的训练数据集的元数据(或数据表)。但这些信息的披露不应对他人的权利或自由产生不利影响,包括数据保护权、商业秘密或知识产权。此外,还需加强追究数据和人工智能系统提供者责任,以管理他们运营的算法系统及其数据流。
5. 促进人工智能法案的实施
在加强人工智能监管的同时,也必须考虑到遵守上述规则将为人工智能开发商带来的成本和风险。首先,认证过程涉及的费用不菲,根据调查研究,外部审计的费用大概是每小时300欧元,公告机构每年进行审计的费用可能高达9 000英镑,[4]这会让提供高风险AI系统的中小型企业或在国际市场上运营的公司,负担极大的成本。因此,应尽可能给予这些企业特定补贴或者援助,减少其进入市场的成本。在设定评估有关的费用时,考虑中小企业利益,可以帮助他们减少一定的费用。
《人工智能法案》第55.1条,让中小企业优先使用AI监管沙箱,是一个合理的尝试。监管沙箱是在开发和上市前阶段,建立一个受控的实验和测试环境,以确保人工智能系统符合欧盟和成员国的相关法律法规,为中小企业(SME)和初创企业消除障碍,加快市场准入,并进行有效风险管理。另一个可能的方案是,让公共机构为私人代理商提供高质量的数据库。这将大大减少有关数据集的审查和认证的支出。例如欧洲健康数据空间(European health data space)将推进对健康数据的非歧视性访问,并以隐私,安全,及时,透明和可信赖的方式,在这些数据集上培训人工智能算法,以确保提供高质量的数据,进行AI系统的验证和测试。
3
建立人工智能的动态监测框架
人工智能法案所引入的治理框架是复杂的,所以我们必须考虑动态监测,包括第三方的监督,并引入成员国之间的竞争机制,由欧盟委员会保障最后的救济手段。这种动态性意味着,对数据集或机制的控制基本上必须以两种方式来实现:
1. 人工智能供应商必须建立一个定期的监控系统。
2. 必须考虑到可能对数据产生重大影响的全部情况。
《人工智能法案》第9条规定了风险管理,规定人工智能提供者必须在整个开发过程中的所有时间点,对高风险的人工智能系统进行充分的测试;第42.4条规定,“当高风险人工智能系统进行重大修改时,都应接受新的合格性评估程序,无论修改后的系统是打算进一步扩大使用或仍为当前用户继续使用”;第61条规定,人工智能提供者应根据人工智能技术的性质及其系统的风险,成比例的建立和记录上市后监测系统(…)上市后也应积极、系统地收集、记录和分析用户提供或通过其他来源的高风险人工智能系统的相关数据,并持续的对运行情况进行评估。
然而,上述监管框架的最大弊端在于,它没有为公民个人和保护人权的非政府组织(NGO)提供足够的救济,例如向市场监督当局投诉或起诉未遵守要求的提供者或用户,这是之后需要重点关注的问题。实践表明,对于人工智能审计的最佳实践,是在AI开发过程中的人类的充分参与,以及在每个决策周期进行适当的人为干预。所以,欧盟需要建立伦理审查的跨学科团队,探索主体多元化、共识协商化的协同治理模式。
[1] STOA study 'Auditing the quality of datasets used in algorithmic decision-making systems'.
[2] Bias on the web[J]. Ricardo Baeza-Yates. Communications of the ACM,2018(6).
[3] Learning Fair Naive Bayes Classifiers by Discovering and Eliminating Discrimination Patterns[J]. YooJung Choi; Golnoosh Farnadi; Behrouz Babaki; Guy Van den Broeck. Proceedings of the AAAI Conference on Artificial Intelligence, 2020(06).
[4] Iva Gumnishka:Gender and racial bias in computer vision. accessed March21, 2023.https://thegoodai.co/2021/04/14/gender-and-racial-bias-in-computer-vision/.
[5] 例如,《数字服务法》规定,大型在线平台有义务采取措施,确保它们所使用的算法系统的设计不会在平台用户之间造成歧视。这些措施包括需要进行风险评估和设计其适当的风险缓解措施。该法案还规定,非常大的在线平台应通过独立审计,对其遵守该法规规定的义务负责,并在相关情况下,对根据行为守则和危机协议作出的任何补充承诺负责。不用说,这些规定将是有效的,以对抗偏见。《数字市场法》没有明确提到需要纳入的对抗偏见的措施,但它规定,看门人应为商业用户进入其软件应用商店应用公平和非歧视性的一般条件。它还引入了一些条款,旨在禁止在协议或其他书面条款中加入保密条款,以妨碍商业用户行使对任何相关行政当局或其他公共当局的看门人的不公平行为提出担忧的权利。
[6] IEEE, “The ethics certification program for autonomous and intelligent systems (ECPAIS).” [Online]. Available:
https://standards.ieee.org/industry-connections/ecpais.html, Accessed on: Aug. 3, 2020.
[7] 第二十九条:数据处理服务的互操作性
1. 开放互操作性规范和数据处理服务互操性的欧洲p标准应:
(a) 以实现涵盖相同服务类型的不同数据处理服务之间的互操作性为目标;
(b) 增强数字资产在涵盖相同服务类型的不同数据处理服务之间的可移植性;
(c) 在技术上可行的情况下,保证涵盖相同服务类型的不同数据处理服务之间的功能等效。
[8] Renda, A. et al., Study to Support an Impact Assessment of Regulatory Requirements for Artificial Intelligence
in Europe. FINAL REPORT (D5), April 2021, page 151.
李容佳 | 清华大学智能法治研究院实习生
选题、指导 | 刘云
编辑 | 朱正熙
