原文链接:https://mp.weixin.qq.com/s/LYmsMJ5c8EIgHo0GtBN9sw
原创 稻穹思
没有好问题,就没有好答案:为什么OpenAI的成立初衷就要与谷歌竞争?微软看重了OpenAI技术的哪些价值?OpenAI 人数少、资源少,为什么能胜出?

让计算机像人一样说人话,是在计算机发明之前的梦想。
虽然早在1966年,MIT的教授约瑟夫·维森班(Joseph Weizenbaum)就开发了第一个聊天程序 ELIZA,50多年后,还陆续出现了更先进的微软小冰、Siri等聊天程序。但直到现在,计算机还没能像真人一样聊天。
1950年,计算机科学之父艾伦·图灵(Alan Turing)发表了具有里程碑意义的论文《电脑能思考吗?》,第一次提出“机器思维”的概念。也就是所谓的图灵测试。他说,如果一台机器能够与人类展开对话,而不被辨别出其机器身份,那么可以说这台机器具有智能。
从那时开始,72年来,人类一直在试图解决这个问题。
6月8日,英国雷丁大学在著名的伦敦皇家学会举办了一场“图灵测试”。当天测试中,一组人类裁判以键盘输入的形式与电脑“对话”。如果裁判认定电脑为人的比例超过30%,则电脑通过测试。5个参赛电脑程序之一的“尤金·古兹曼”成功“伪装”成一名13岁男孩,在一次时间为5分钟的文字交流中,回答了裁判输入的所有问题,其中33%的回答让裁判认为与他们对话的是人而非机器。

有人说,这个程序通过了图灵测试,成为有史以来第一个具有人类思考能力的人工智能。
也有人质疑,这个测试的提问时间少,裁判少,严格来说,不能算通过了图灵测试。
大家的共识是,到目前为止,还没有任何人工智能通过了图灵测试,而最接近通过图灵测试的就是ChatGPT。
许多人认为,对ChatGPT这个每天都在跟人对话中学习的AI来说,通过图灵测试应该只是时间问题。
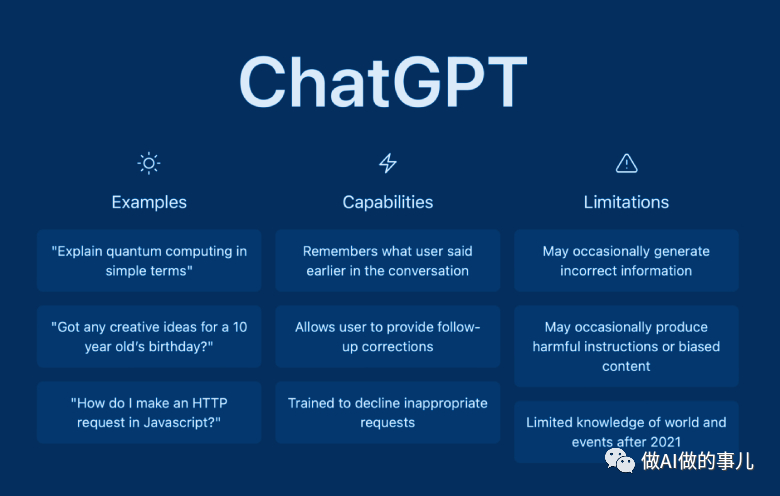
ChatGPT是什么?
2022 年 11 月 30 日,OpenAI 的CEO,Altman 在推特上写道:“今天我们推出了 ChatGPT,尝试在这里与它交谈”,然后是一个链接,任何人都可以注册一个帐户,开始免费与 OpenAI 的新聊天机器人 ChatGPT 交谈。
ChatGPT 能够回答连续的问题、生成文本摘要、翻译文档、对信息分类、写代码等,它也会承认错误、质疑不正确的前提并拒绝不恰当的请求。
ChatGPT 看起来什么都懂,就像个百科全书。由于其流畅的回答,丰富的知识,给参与者极大的震撼。但它并不完美,也会产生让人啼笑皆非的错误,带来莫名的喜感。

在24小时内,一大群人涌入网站,给 ChatGPT提了各种要求。软件 CEO 兼工程师 Amjad Masad 要求它调试他的代码,它做到了。美食博主兼网红Gina Homolka用它写了一份健康巧克力曲奇的食谱。Scale AI 的工程师 Riley Goodside 要求它为Seinfeld剧集编写剧本。Guy Parsons 是一名营销人员,他还经营着一家致力于 AI 艺术的在线画廊,他让它为他编写提示,以输入另一个 AI 系统Midjourney,从文本描述创建图像。斯坦福大学医学院的皮肤科医生 Roxana Daneshjou 在研究 AI 在医学上的应用,它提出了医学问题,许多学生用它来做作业......。
以前也出现过很多聊天机器人,但都不是这样的。ChatGPT 可以进行长时间、流畅的对话,回答问题,并撰写人们要求的几乎任何类型的书面材料,包括商业计划、广告活动、诗歌、笑话、计算机代码和电影剧本。ChatGPT 会在一秒内生成这些内容,用户无须等待,而且它生成的很多内容都还不错。
在ChatGPT发布后的五天内,就有超过100万的玩家,这是Facebook花了 10 个月才达到的里程碑。
自从 ChatGPT 出现后。突然之间,每个人都在谈论人工智能如何颠覆他们的工作、公司、学校和生活。
ChatGPT 是相关人工智能技术浪潮的一部分,这些技术统称为“生成式人工智能”——其中还包括热门的艺术生成器,如 Midjourney 和 Lensa。OpenAI处于科技行业下一件大事件的最前沿,具有初创公司史诗般的标志,包括全明星阵容和狂热的投资者,据报道,该公司的估值达到 290 亿美元。
2022年12月4日,埃隆·马斯克 (Elon Musk)发了一条推文,他说:“ChatGPT有一种让人毛骨悚然的厉害,我们离危险的强大人工智能已经不远了。”
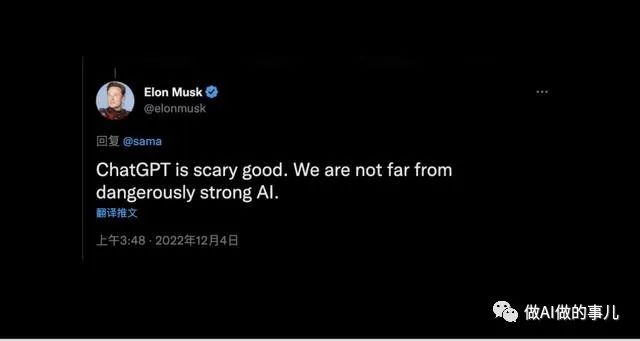
埃隆·马斯克在Twitter上对ChatGPT的评价
ChatGPT 由 GPT-3.5 模型提供支持,GPT(Generative Pre-trained Transformer ,生成式预训练变换器) 是一种基于互联网可用数据训练的文本生成深度学习模型。名字中之所以有一个Transformer,是因为GPT就是OpenAI在谷歌的Transformer语言模型框架的基础上构建的。
该模型使用了 " 利用人类反馈强化学习(RLHF)" 的训练方式,包括了:人类提问机器答、机器提问人类回答,并且不断迭代,让模型逐渐有了对生成答案的评判能力。
在ChatGPT出现之前,大众对OpenAI的了解很少,这家公司就好像突然出现的一样,它到底是什么来历?
实际上,OpenAI的创始人有很多是的IT巨头的创始人,可以说是全明星阵容。
2015年12月,OpenAI创立
2015年12月,OpenAI公司于美国旧金山成立。说来有趣,OpenAI成立的一个原因就是避免谷歌在人工智能领域的垄断。这个想法起源于Altman发起的一次主题晚宴,当时他是著名创业孵化器 Y Combinator 的负责人。
Sam Altman 是一位年轻的企业家和风险投资家,他曾在斯坦福大学读计算机科学专业,后来退学去创业。他创立的 Loopt ,是一个基于地理位置的社交网络公司。2005年该公司进入Y Combinator的首批创业公司。虽然 Loopt 未能成功,但 Altman 把公司卖掉了,用赚到的钱进入了风险投资领域,做得相当成功。后来,Y Combinator 的联合创始人保罗·格雷厄姆 (Paul Graham) 和利文斯顿 (Livingston) 聘请他作为格雷厄姆的继任者来管理 YC。

OpenAI的CEO Sam Altman
2015 年 7 月的一个晚上,Altman在 Rosewood Sand Hill 举办了一场私人晚宴,这是一家豪华的牧场风格酒店,位于门洛帕克硅谷风险投资行业的中心, 马斯克(Elon Musk)也在现场,还有26岁的布罗克曼,他是麻省理工学院(MIT)的辍学生,曾担任支付处理初创公司Stripe的首席技术官。一些与会者是经验丰富的人工智能研究人员。有些人几乎不懂机器学习,但他们都相信 AGI 是可行的。
AGI即Artificial general intelligence的简写,指通用人工智能。专注于研制像人一样思考、像人一样从事多种用途的机器智能。目前主流AI(如机器视觉、语音输入等)都属于专用人工智能。
那时,谷歌刚刚收购了一家总部位于伦敦的人工智能公司DeepMind(就是推出了打败围棋冠军的AlphaGo的公司),在Altman、Elon Musk和其他科技业内部人士看来,这是首家最有可能率先开发 AGI 的公司。如果 DeepMind 成功了,谷歌可能会垄断这项无所不能的技术。Rosewood 晚宴的目的是讨论组建一个与谷歌竞争的实验室,以确保这种情况不会发生。
说干就干,几个月后,OpenAI 就成立了。它旨在成为DeepMind 和谷歌无法做到的一切。它将作为一个非营利组织运营,明确致力于使先进人工智能的好处民主化。它承诺发布其研究成果,并开源其所有技术,其对透明度的承诺体现在其名称中:OpenAI。
OpenAI 捐助者名册令人印象深刻,不仅有特斯拉的创始人马斯克(Elon Musk),还有全球在线支付平台 PayPal 的联合创始人彼得·蒂尔、Linkedin的创始人里德·霍夫曼、创业孵化器Y Combinator总裁阿尔特曼(Sam Altman)、Stripe的CTO布罗克曼(Greg Brockman)、Y Combinator 联合创始人 Jessica Livingston;还有一些机构,如YC Research,Altman创立的基金会、印度 IT 外包公司 Infosys和亚马逊网页服务。创始捐助者共同承诺向这个理想主义的新企业捐助 10 亿美元(尽管根据税务记录,该非营利组织只收到了引人注目的承诺的一小部分)。
OpenAI 也吸引了许多技术大牛加入,如 Ilya Sutskever, Carlos Virella, James Greene, Wojciech Zaremb等。
这里重点提一下联合创始人Ilya Sutskever,他是OpenAI的首席科学家,在进入OpenAI之前,他在谷歌开发 AlphaGo,而在OpenAI,他带领团队开发了GPT、CLIP、DALL-E和Codex等AI模型。

2016年,OpenAI 推出了Gym,这是一个允许研究人员开发和比较强化学习系统的平台,可以教AI做出具有最佳累积回报的决策。
同年,OpenAI还发布了Universe,这是一个能在几乎所有环境中衡量和训练 AI 通用智能水平的开源平台,目标是让 AI 智能体能像人一样使用计算机。Universe 从李飞飞等人创立的 ImageNet 上获得启发,希望把 ImageNet 在降低图像识别错误率上的成功经验引入到通用人工智能的研究上来,取得实质进展。OpenAI Universe提供了跨网站和游戏平台训练智能代理的工具包,有1000种训练环境,由微软、英伟达等公司参与建设。

Universe游戏环境,用于人类模拟器
虽然在创立后,OpenAI一直在推出技术产品,看起来也有不错的成绩,但跟谷歌没法比。在那段时间,谷歌的成绩才是真正辉煌。
2016年3月9日,AlphaGo与围棋冠军李世石围棋大战,最终以4:1胜出。一年之后,新版的AlphaGo又以3:0战胜了围棋冠军柯洁。之后发布的AlphaZero更是让人惊叹,它在三天内自学了三种不同的棋类游戏,包括国际象棋、围棋和日本将军棋,而且无需人工干预。这是一种人类从未见过的智慧。
这些成果好像验证了2015年,大家在聚会上的判断,谷歌很可能在人工智能领域的形成垄断地位。确实,从AlphaGo的成功来看,谷歌已经牢牢占住了人工智能的高地,无人可以撼动。谷歌还收购了十几家AI公司,投入的资金和资源巨大,成果斐然。
2016年4月,谷歌著名的深度学习框架TensorFlow发布分布式版本;8月,Google发布基于深度学习的NLU框架SyntaxNet; 9月,Google上线基于深度学习的机器翻译。
而且,谷歌的 CEO 桑德·皮查伊(Sundar Pichai) 在 2016 年 5 月宣布将公司从“移动为先”的策略转变成“人工智能为先”(AI First)。并计划在公司的每一个产品上都应用机器学习的算法。也就是说,谷歌已经开始把人工智能技术变成了自己的业务优势,去赚钱或者省钱了。
看起来,OpenAI 离战胜谷歌的预期目标还很远。2017年开始,一些人工智能大牛离开了OpenAI,如Ian Goodfellow 和 Pieter Abbeel 等。
OpenAI的前途在哪里呢?
没想到,OpenAI 决定与谷歌硬碰硬。竟然在谷歌开创的道路上,取得了震惊业内的突破,持续推出了GPT系列模型,并迅速拓展到多个富有前景的商业领域,力压谷歌一头。
顺便说一下,谷歌的高歌猛进让微软也很焦虑。微软虽然也有一些不错的人工智能产品,比如语音识别,小冰聊天机器人等,但是还不成体系。
下面我们看看ChatGPT的成长史,了解它是如何在人工智能技术的竞赛中胜出的?
2017年6月,6500万参数的 Transformer
2017年6月,谷歌大脑团队(Google Brain)在神经信息处理系统大会(NeurIPS,该会议为机器学习与人工智能领域的顶级学术会议)发表了一篇名为“Attention is all you need”《自我注意力是你所需要的全部》的论文。作者在文中首次提出了基于自我注意力机制(self-attention)的变换器(transformer)模型,并首次将其用于理解人类的语言,即自然语言处理。

在这篇文章发布之前,自然语言处理领域的主流模型是循环神经网络(RNN,recurrent neural network)。循环神经网络模型的优点是,能更好地处理有先后顺序的数据,它被广泛的用于自然语言处理中的语音识别,手写识别,时间序列分析以及机器翻译等领域。但这种模型也有不少缺点:在处理较长序列,例如长文章、书籍时,存在模型不稳定或者模型过早停止有效训练的问题,以及训练模型时间过长的问题。
而论文中提出的Transformer模型,能够同时并行进行数据计算和模型训练,训练时长更短,并且训练得出的模型可用语法解释,也就是模型具有可解释性。
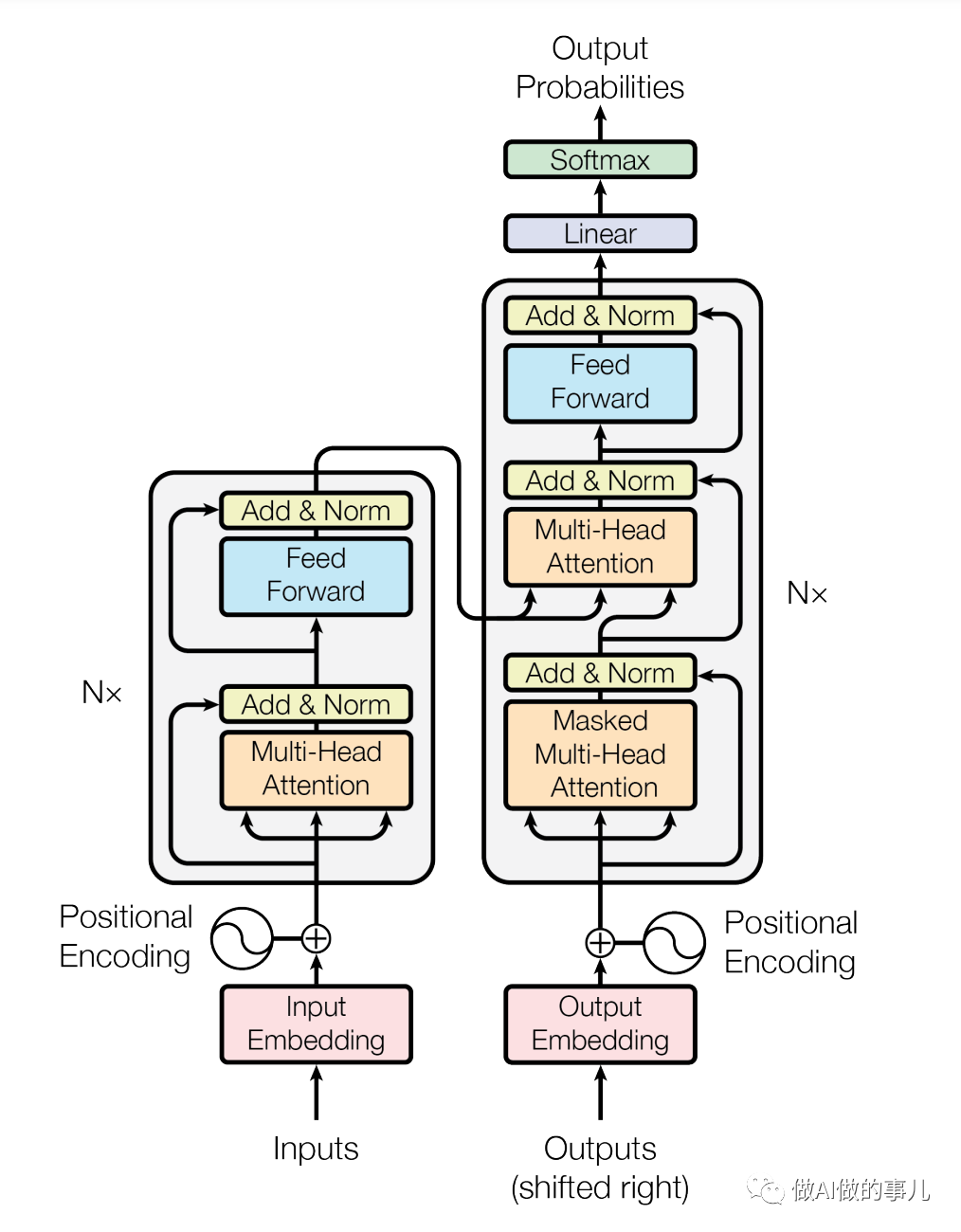
最初的变换器(Transformer)模型的架构
谷歌大脑团队使用了多种公开的语言数据集来训练最初的Transformer模型,一共有6500万个可调参数。
经过训练后,这个最初的Transformer模型在包括翻译准确度、英语成分句法分析等各项评分上都达到了业内第一,成为当时最先进的大型语言模型(Large Language Model, LLM),其最常见使用场景就是输入法和机器翻译。

Transformer模型自诞生的那一刻起,就深刻地影响了接下来几年人工智能领域的发展轨迹。
因为谷歌大脑团队在论文中提供了模型的架构,任何人都可以用其搭建类似架构的模型来并结合自己手上的数据进行训练。
于是,Transformer就像其另一个霸气的名字“变形金刚”一样,被更多人研究,并不断地变化。
短短的几年里,该模型的影响已经遍布人工智能的各个领域——从各种各样的自然语言模型、到预测蛋白质结构的AlphaFold2模型,用的都是它。

2018年6月,1.17亿参数的GPT-1
GPT的问世,是AI进化的另一个伟大的里程碑。
之前的神经网络模型是有监督学习的模型,存在两个缺点:
需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务中,图像的标签并不是唯一的或者实例标签并不存在明确的边界;
根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP。
假如能用无标注数据训练一个预训练模型,就能省时省力省钱。
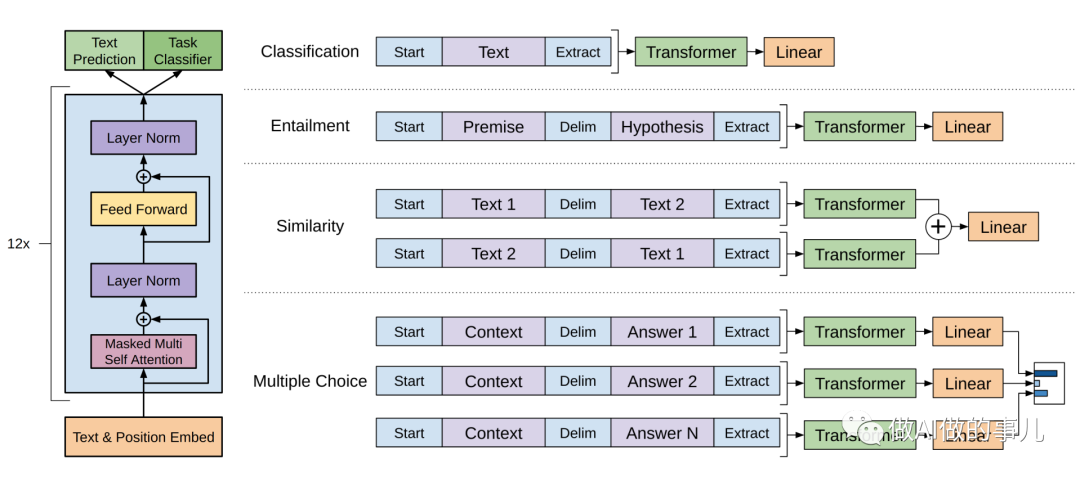
GPT-1的思想是先通过在无标签的数据上学习一个生成式的语言模型,然后再根据特定任务进行微调,处理的有监督任务包括:
自然语言推理:判断两个句子是关系(包含、矛盾、中立);
问答和常识推理:类似于多选题,输入一个文章,一个问题以及若干个候选答案,输出为每个答案的预测概率;
语义相似度:判断两个句子是否语义上市是相关的;
分类:判断输入文本是指定的哪个类别。
将无监督学习的结果用于左右有监督模型的预训练目标,因此叫做生成式预训练(Generative Pre-training,GPT)。这种半监督学习方法,由于用大量无标注数据让模型学习“常识”,就无需标注信息了。
2018年6月,在谷歌的 Transformer 模型诞生一周年时,OpenAI公司发表了论文“Improving Language Understanding by Generative Pre-training”《用生成式预训练提高模型的语言理解力》,推出了具有1.17亿个参数的GPT-1(Generative Pre-training Transformers, 生成式预训练变换器)模型。
GPT-1 使用了经典的大型书籍文本数据集(BookCorpus)进行模型预训练,之后,又针对四种不同的语言场景、使用不同的特定数据集对模型进行进一步的训练(又称为微调,fine-tuning)。最终训练所得的模型在问答、文本相似性评估、语义蕴含判定、以及文本分类这四种语言场景,都取得了比基础Transformer模型更优的结果,成为了新的业内第一。
由于 GPT-1 的诞生,这一年也被称为NLP(自然语言处理)的预训练模型元年。
从此以后,自然语言识别的主流模式就是GPT-1这样的:先在大量无标签的数据上预训练一个语言模型,然后再在下游具体任务上进行有监督的fine-tune,以此取得还不错的效果。
GPT-1 具体是怎么做的呢?
首先,预训练模型是用了transformer的decoder部分,利用语言模型的目标来训练预训练模型。
其次,GPT-1 采取预训练 + FineTuning两个阶段,它采取Transformer的decoder作为特征抽取器,总共堆叠12个。
预训练阶段采用“单向语言模型”作为训练任务,把语言知识编码到decoder里。
第二阶段,在第一阶段训练好的模型基础上,将预训练模型学习的知识迁移到下游任务,适配能力强。GPT-1通过统一的表征形式,对下游各种任务只需要很少的适配,具体适配方式就是加不同的任务分类头,另外,对不同任务的输入形式做了设计。
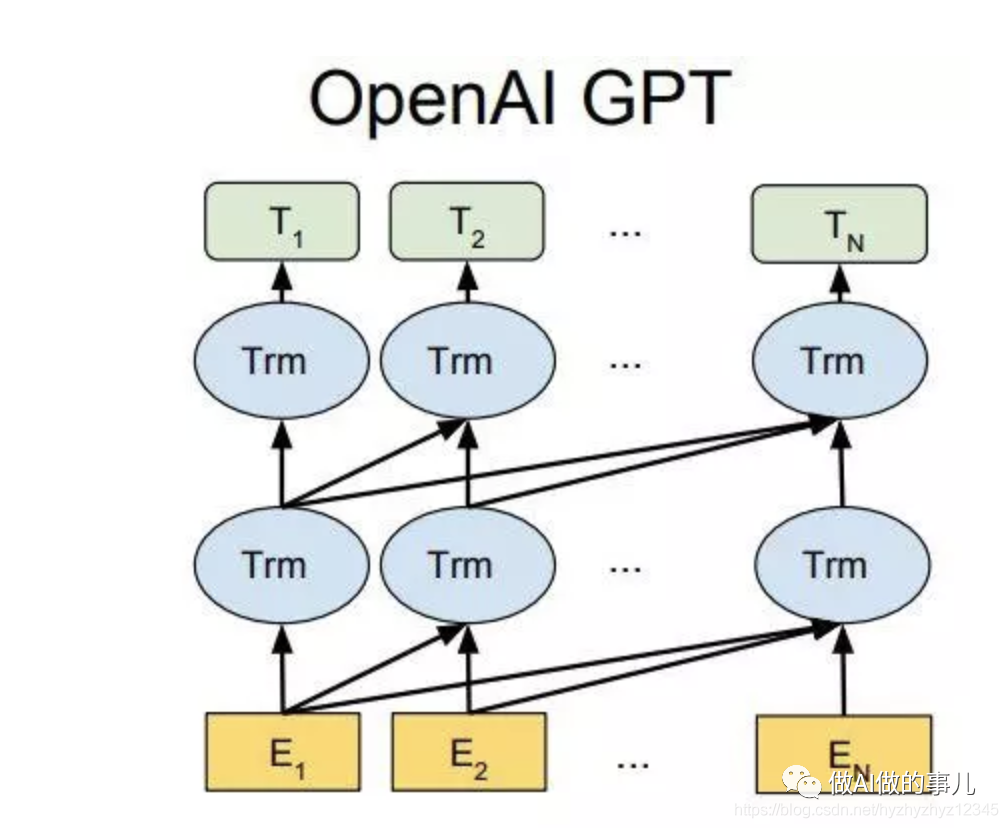
前面说过,GPT-1 适配的下游任务有自然语言推断 NLI(natural language inference),问答QA(question answer),语义匹配(semantic similarity),文本分类(text classification)。
下游任务适配的过程分两步:1、根据任务定义不同输入,2、对不同任务增加不同的分类层。
具体定义可以参见下图:
随着训练次数的增加,GPT-1的性能也逐渐提升,表明GPT-1有非常强的泛化能力,能够用到和有监督任务无关的其它NLP任务中。对于下游任务的训练,GPT-1往往只需要简单的微调便能取得非常好的效果。
GPT-1在未经微调的任务上虽然也有一定效果,但是其泛化能力远远低于经过微调的有监督任务,说明了GPT-1只是一个简单的领域专家,而非通用的语言学家。
不管怎样,GPT-1 赢过了 Transformer,成为了业界的新标杆。OpenAI赢得漂亮!
2018年10月,3亿参数的BERT
2018年10月,谷歌提出3亿参数的BERT(Bidirectional Encoder Representation from Transformers),“来自Transformers的双向编码表示”模型。
BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩: 全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现,包括将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。
据测试,在同等参数规模下,BERT的效果好于GPT-1,因为它是双向模型,可以利用上下文来分析的。而GPT是单向模型,无法利用上下文信息,只能利用上文。
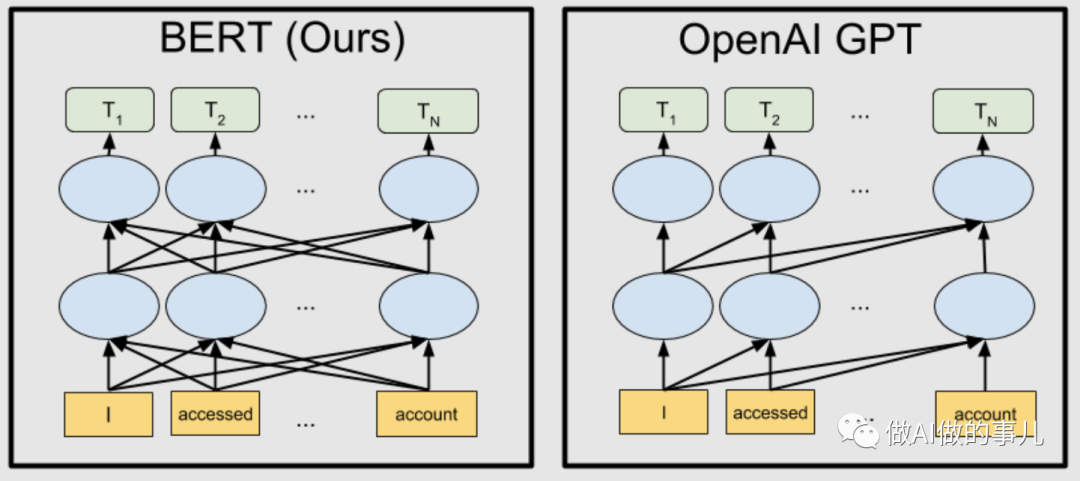
GPT 学会了猜测句子中的下一组单词。BERT学会了猜测句子中任何地方缺少的单词。如果你给BERT几千个问题和答案,它可以学会自己回答其他类似的问题。BERT也可以进行对话。
从阅读理解方面来看,BERT模型的提升是很大的。在当时的SQuAD竞赛排行榜上,排在前列的都是BERT模型,基本上,阅读理解领域已经被BERT屠榜了。
谷歌的BERT模型完胜。
2019年2月,15亿参数的GPT-2
2019年2月,OpenAI推出了GPT-2,同时,他们发表了介绍这个模型的论文“Language Models are Unsupervised Multitask Learners” (语言模型是无监督的多任务学习者)。
相比于大哥GPT-1,GPT-2并没有对原有的网络进行过多的结构创新与设计,只使用了更多的网络参数与更大的数据集:最大模型共计48层,参数量达15亿。
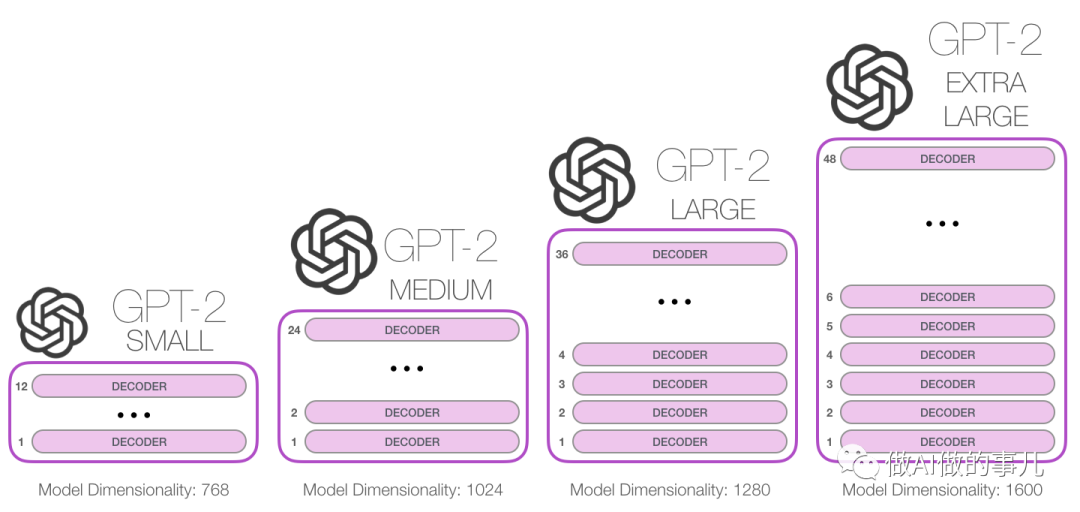
GPT-2用于训练的数据取自于Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。
GPT-2 模型是开源的,主要目的是为给定句子生成下一个文本序列。
假如给定一两个句子的文本提示,GPT-2 就能生成一个完整的叙述。对一些语言任务,如阅读、摘要和翻译,可以通过 GPT-2 学习原始文本,而不需要使用特定领域的训练数据。
在性能方面,除了理解能力外,GPT-2 在文本内容生成方面表现出了强大的天赋:阅读摘要、聊天、续写、编故事,甚至生成假新闻、钓鱼邮件或在网上进行角色扮演等,通通不在话下。 在“变得更大”之后,GPT-2 的确展现出了普适而强大的能力,并在多个特定的语言建模任务上实现了那时的最佳性能。
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型可迁移到其它类别任务中,而不需要额外的训练。
从本质上来说,GPT-2就是一个简单的统计语言模型。 从机器学习的角度,语言模型是对词语序列的概率分布的建模,即利用已经说过的片段作为条件预测下一个时刻不同词语出现的概率分布。语言模型一方面可以衡量一个句子符合语言文法的程度(例如衡量人机对话系统自动产生的回复是否自然流畅),同时也可以用来预测生成新的句子。例如,对于一个片段“中午12点了,我们一起去餐厅”,语言模型可以预测“餐厅”后面可能出现的词语。一般的语言模型会预测下一个词语是“吃饭”,强大的语言模型能够捕捉时间信息并且预测产生符合语境的词语“吃午饭”。
通常,一个语言模型是否强大主要取决于两点: 首先看该模型是否能够利用所有的历史上下文信息, 上述例子中如果无法捕捉“中午12点”这个远距离的语义信息,语言模型几乎无法预测下一个词语“吃午饭”。 其次,还要看是否有足够丰富的历史上下文可供模型学习,也就是说训练语料是否足够丰富 。 由于语言模型属于无监督学习,优化目标是最大化所见文本的语言模型概率,因此任何文本无需标注即可作为训练数据。
GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,但需要继续投资才能挖掘潜力。
由于GPT-2的的性能和生成文本能力获得了很高赞誉,OpenAI又扳回一局。
2019年3月,OpenAI 重组
因为 GPT 系列模型的成功,OpenAI 决定再融资几十亿美元来发展AI,因为模型越大、参数越多、训练AI模型需要的钱也越多,一年花个几千万美元来计算是刚性开支。而且,人工智能研究人员的薪水也不便宜,税务记录显示,首席科学家 Ilya Sutskever 在实验室的头几年,年薪为 190 万美元。搞AI太费钱了!
其实,早在2017 年 3 月,OpenAI 内部就意识到了这个问题:保持非营利性质无法维持组织的正常运营。因为一旦进行科研研究,要取得突破,所需要消耗的计算资源每 3~4 个月要翻一倍,这就要求在资金上对这种指数增长进行匹配,而 OpenAI 当时的非盈利性质限制也很明显,还远远没达到自我造血的程度。
Altman在 2019 年对《连线》杂志表示:“我们要成功完成任务所需的资金比我最初想象的要多得多。”
烧钱的问题同期也在 DeepMind 身上得到验证。在当年被谷歌收购以后,DeepMind 短期内并没有为谷歌带来盈利,反而每年要烧掉谷歌几亿美元,2018 年的亏损就高达 4.7 亿英镑, 2017 年亏损为 2.8 亿英镑,2016 年亏损为 1.27 亿英镑,烧钱的速度每年大幅增加。好在 DeepMind 有谷歌这棵大树可靠,谷歌可以持续输血。
但是,OpenAI 是非营利组织,无法给到投资者商业回报,难以获得更多资金。
雪上加霜的是,作为世界首富的金主爸爸马斯克也退出了。2018年,在帮助创立该公司三年后,马斯克辞去了OpenAI董事会的职务。原因是为了“消除潜在的未来冲突”,因为特斯拉专注于无人驾驶AI,在人才方面存在竞争关系。
怎么办呢?
Altman和 OpenAI 的其他人的共识是,为了与谷歌、Meta 和其他科技巨头竞争,实验室不能继续作为非营利组织。
2019年3月,OpenAI正式宣布重组,创建新公司OpenAI LP,成为一家“利润上限(caped-profit)”的公司,上限是100倍回报。这是一种不同寻常的结构,将投资者的回报限制在其初始投资的数倍。这也意味着,未来的GPT版本和后续的技术成果都将不再开源。
OpenAI团队分拆后,继续保留非营利组织的架构,由硅谷一线明星组成的非营利性董事会保留对 OpenAI 知识产权的控制权。
虽然回报上限是100倍,但对大资本来说,已经是非常丰厚了,手握GPT神器的新公司迅速获得了许多资本的青睐。
2019年5月,当时 YC 孵化器的总裁 Sam Altman 辞掉了 YC 的工作,来 OpenAI 做CEO,他的目标之一是不断增加对计算和人才方面的投资,确保通用人工智能(AGI)有益于全人类。
大约在这个时候,微软被认为在人工智能领域落后于其竞争对手,其首席执行官Satya Nadella急切地想证明,他的公司能够在技术的最前沿发挥作用。该公司曾尝试聘请一位知名的 AI 科学家,还花费了大笔钱来购买技术和算力,但未能成功。而OpenAI正好拥有微软期望的技术。Altman 与Nadella 一拍即合。

Sam Altman 与微软 CEO Satya Nadella
2019年7月,重组后的 OpenAI 新公司获得了微软的10亿美元投资(大约一半以Azure云计算的代金券形式)。这是个双赢的合作,微软成为OpenAI 技术商业化的“首选合作伙伴”,未来可获得OpenAI 的技术成果的独家授权,而OpanAI则可借助微软的Azure云服务平台解决商业化问题,缓解高昂的成本压力。
从这时候起,OpenAI告别了单打独斗,而是靠上了微软这棵大树,一起与谷歌竞争。
微软也终于获得了能抗衡谷歌AI的先进技术,确保在未来以AI驱动的云计算竞争中不会掉队。
Altman的加入,虽然解决了关键的资金问题,但他的风格导致了团队价值观的分裂。
虽然Altman从一开始就参与了 OpenAI,但他在3年多以后才全职加入成为 CEO。Altman不是科学家或人工智能研究人员,他的领导风格是以产品为导向的,他让OpenAI的技术研发聚焦在更具有商业价值的方面。
一些OpenAI的前员工表示,在微软进行初始投资后,专注于 LLM 的内部压力大幅增加,部分原因是这些模型具有直接的商业应用。
一些人抱怨说,OpenAI 的成立是为了不受公司影响,但它很快成为一家大型科技公司的工具。一位前员工说:“重点更多的是,我们如何创造产品,而不是试图回答最有趣的问题,”。
OpenAI 也变得不那么开放了。由于担心其技术可能被滥用,它已经开始放弃发布所有研究成果和开源代码的承诺。但据前员工称,商业逻辑也发挥了作用。OpenAI的高级模型只能通过 API 提供,从而保护了其知识产权和收入来源。“
由于这些战略和文化的转变,OpenAI前研究副总裁Dario Amodei带着10名员工(其中许多人从事人工智能安全工作)于2021年与公司决裂,成立自己的研究实验室Anthropic,其推出的产品 Claude 是 ChatGPT 的一个强有力的竞争对手,在许多方面都有所改进。
Claude不仅更倾向于拒绝不恰当的要求,而且比 ChatGPT 更有趣,生成的内容更长,但也更自然。可以连贯地描写自己的能力,局限性和目标,也可以更自然地回答其他主题的问题。
对于其他任务,如代码生成或代码推理,Claude似乎比较糟糕,生成的代码包含更多的 bug 和错误。
Anthropic 刚成立不久就筹集了7.04亿美元,估值为40亿美元。最近的报道称,它即将获得约3亿美元的新融资,估值可能在50亿美元左右。也有人指出,Anthropic的绝大部分资金来自声名狼藉的加密货币企业家萨姆·班克曼-弗里德(Sam Bankman-Fried)和他在FTX的同事们。由于加密货币平台FTX去年因欺诈指控而破产,这笔钱可能会被破产法庭收回,让 Anthropic 陷入困境。
2019年10月,110亿参数的T5
2019年10月,谷歌在论文《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》提出了一个新的预训练模型:T5。该模型涵盖了问题解答,文本分类等方面,参数量达到了110亿,成为全新的NLP SOTA预训练模型。在SuperGlue上,T5也超越了Facebook提出的的RoBERTa,以89.8的得分成为仅次于人类基准的SOTA模型。
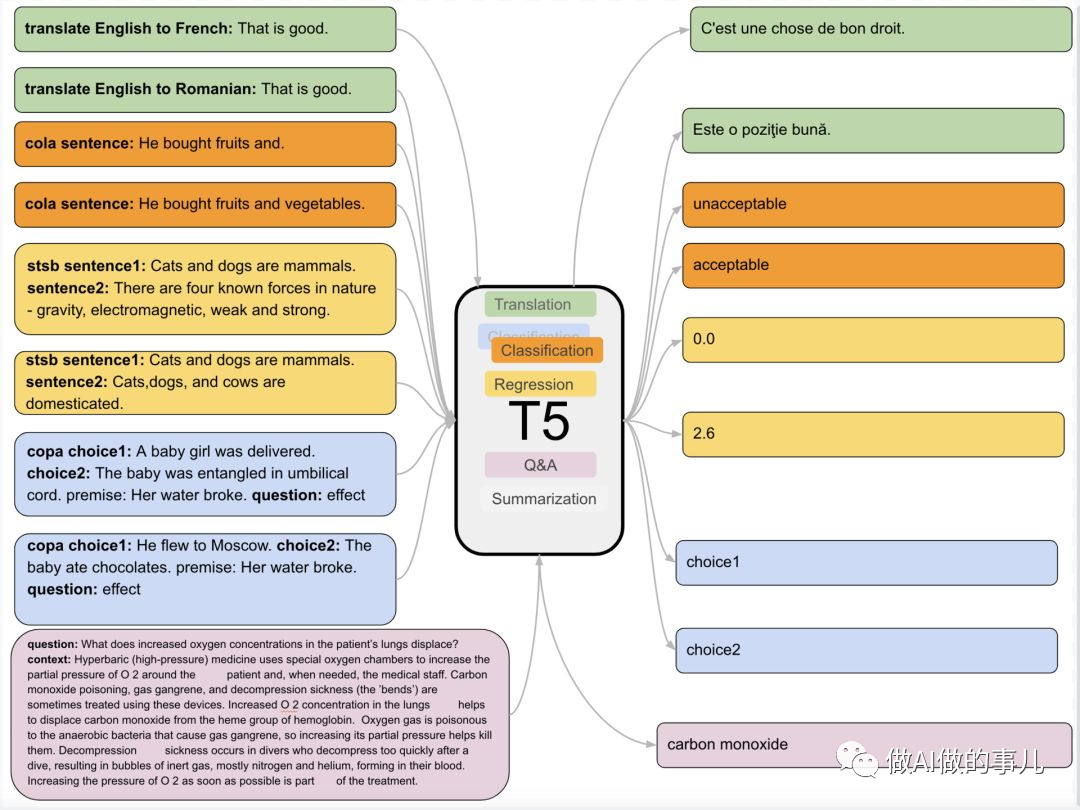
为啥叫T5?因为这是“Transfer Text-to-Text Transformer”的缩写。
T5作为一个文本到文本的统一框架,可以将同一模型、目标、训练流程和解码过程,直接应用于实验中的每一项任务。研究者可以在这个框架上比较不同迁移学习目标、未标注数据集或者其他因素的有效性,也可以通过扩展模型和数据集来发现 NLP 领域迁移学习的局限。
Flan-T5通过在超大规模的任务上进行微调,让语言模型具备了极强的泛化性能,做到单个模型就可以在1800多个NLP任务上都能有很好的表现。
微调的目的是让语言模型学习理解指令,不是想让语言模型解决成千上万任务,当然训练方式中是有很多任务,因为不同任务有不同的指令,所以目的还是想让模型理解这些指令,解决各种任务问题。在真实世界中,总会有新任务,模型只要学习新任务的新指令,那么就能解决新任务。指令学习本质是把语言模型的问题用语言讲出来。
一旦模型训练完毕,可以直接在几乎全部的NLP任务上直接使用,实现一个模型解决所有问题(One model for ALL tasks),这就非常有诱惑力!
从创新来看,T5算不上出奇制胜,因为模型没有用到什么新的方法,而是从全面的视角来概述当前 NLP 领域迁移学习的发展现状。
简单来说,还是通过大力出奇迹,用110亿参数的大模型,在摘要生成、问答、文本分类等诸多基准测试中都取得了不错的性能。一举超越现有最强模型。
谷歌T5编写的通用知识训练语料库中的片段来自Common Crawl网站,该项目每个月从网络上爬取大约20TB的英文文本。
具体做法分为三步:
(1) 「任务收集」:收集一系列监督的数据,这里一个任务可以被定义成<数据集,任务类型的形式>,比如“基于SQuAD数据集的问题生成任务”。
(2) 「形式改写」:因为需要用单个语言模型来完成超过1800+种不同的任务,所以需要将任务都转换成相同的“输入格式”喂给模型训练,同时这些任务的输出也需要是统一的“输出格式”。
(3) 「训练过程」:采用恒定的学习率以及Adafactor优化器进行训练;同时会将多个训练样本“打包”成一个训练样本,这些训练样本直接会通过一个特殊的“结束token”进行分割。训练时候在每个指定的步数会在“保留任务”上进行模型评估,保存最佳的checkpoint。
尽管微调的任务数量很多,但是相比于语言模型本身的预训练过程,计算量小了非常多,只有0.2%。所以通过这个方案,大公司训练好的语言模型可以被再次有效的利用,应用方只需要做好“微调”即可,不用重复耗费大量计算资源再去训一个语言模型。
从竞赛排行榜看,T5以绝对的优势胜出。
2020年5月,1750亿参数的GPT-3
面临谷歌这样强大的对手,OpenAI并不服输。
在所有跟进、研究Transformer模型的团队中,OpenAI公司是少数一直在专注追求其极限的一支团队。
不同于谷歌总在换策略,OpenAI 的策略更单一,就是持续迭代 GPT,由于之前的算力和数据限制,GPT的潜力还没挖掘出来。
而在 GPU 多机多卡并行算力和海量无标注文本数据的双重支持下,预训练模型实现了参数规模与性能齐飞的局面。
预训练模型规模以平均每年10倍的速度增长
(最后一列计算时间为使用单块NVIDIA V100 GPU训练的估计时间。M-百万,B-十亿)
2020年5月,OpenAI发布了GPT-3,这是一个比GPT-1和GPT-2强大得多的系统。同时发表了论文“Language Models are Few-Shot Learner”《小样本学习者的语言模型》。
GPT-3论文包含31个作者,整整72页论文,在一些NLP任务的数据集中使用少量样本的Few-shot方式甚至达到了最好效果,省去了模型微调,也省去了人工标注的成本。
GPT-3的神经网络是在超过45TB的文本上进行训练的,数据相当于整个维基百科英文版的160倍。而且,GPT-3有1750亿参数。
GPT-3作为一个无监督模型(现在经常被称为自监督模型),几乎可以完成自然语言处理的绝大部分任务 ,例如面向问题的搜索、阅读理解、语义推断、机器翻译、文章生成和自动问答等等。
而且,该模型在诸多任务上表现卓越, 例如在法语-英语和德语-英语机器翻译任务上达到当前最佳水平。它非常擅长创造类似人类的单词、句子、段落甚至故事,输出的文字读起来非常自然,看起来就像是人写的。用户可以仅提供小样本的提示语、或者完全不提供提示而直接询问,就能获得符合要求的高质量答案。可以说GPT-3似乎已经满足了我们对于语言专家的一切想象。
GPT-3甚至还可以依据任务描述自动生成代码,比如编写SQL查询语句,React或者JavaScript代码等。
从上述工作的规模数据可以看到,GPT-3的训练工作量之大,模型输出能力之强可以说是空前的,可谓“大力出奇迹”。
当时,GPT-3 成为各种重要媒体杂志的头条新闻。2020年9月,英国《卫报》发表了GPT-3撰写的一篇文章,其中AI试图“说服我们机器人和平相处”。2021年3月,TechCrunch编辑Alex Wilhelm表示,在他对GPT-3的能力感到“震惊”后,“炒作似乎相当合理”。
由于 GPT-3模型面世时,未提供用户交互界面,所以直接体验过GPT-3模型的人数并不多。
早期测试结束后,OpenAI公司对GPT-3模型进行了商业化:付费用户可以通过应用程序接口(API)连上GPT-3,使用该模型完成所需语言任务。
许多公司决定在GPT-3 系统之上构建他们的服务。Viable是一家成立于2020年的初创公司,它使用GPT-3为公司提供快速的客户反馈。Fable Studio基于该系统设计VR角色。Algolia将其用作“搜索和发现平台”。而Copysmith专注于文案创作。
2020年9月,微软公司获得了GPT-3模型的独占许可,意味着微软公司可以独家接触到GPT-3的源代码。不过,该独占许可不影响付费用户通过API继续使用GPT-3模型。
虽然好评如潮,商家应用也越来越多,GPT-3仍然有很多缺点。
下面列举一些:
1 回答缺少连贯性
因为GPT-3只能基于上文,而且记忆力很差,倾向于忘记一些关键信息。
研究人员正在研究AI,在预测文本中的下一个字母时,可以观察短期和长期特征。这些策略被称为卷积。使用卷积的神经网络可以跟踪信息足够长的时间来保持主题。
2 有时存在偏见
因为GPT-3训练的数据集是文本,反映人类世界观的文本,里面不可避免包括了人类的偏见。如果企业使用GPT-3自动生成电子邮件、文章和论文等,而无需人工审查,则法律和声誉风险很大。例如,带有种族偏见的文章可能会导致重大后果。
杰罗姆·佩森蒂是Facebook的AI负责人,他使用库马尔的GPT-3生成的推文来展示当被提示“犹太人、黑人、妇女或大屠杀”等词时,其输出可能会变得多么危险。库马尔认为,这些推文是精心挑选的,佩森蒂同意,但回应说,“产生种族主义和性别歧视的输出不应该这么容易,尤其是在中立的提示下。”。
另外,GPT-3在对文章的评估方面存在偏见。人类写作文本的风格可能因文化和性别而有很大差异。如果GPT-3在没有检查的情况下对论文进行评分,GPT-3的论文评分员可能会给学生打分更高,因为他们的写作风格在训练数据中更为普遍。
3 对事实的理解能力较弱
GPT-3无法从事实的角度辨别是非。比如,GPT-3可以写一个关于独角兽的引人入胜的故事,但它可能并不了解独角兽到底是什么意思。
4 错误信息/假新闻
GPT-3能像人类一样撰写新闻或观点文章,居心叵测的人可能利用它来产生虚假信息,如虚假故事、虚假通信或冒充社交媒体帖子,以及有偏见或辱骂性语言。或者垃圾邮件、网络钓鱼、欺诈性学术论文写作、煽动极端主义和社会工程借口。GPT-3很容易成为强大的宣传机器的引擎。
5 不适合高风险类别
OpenAI做了一个免责声明,即该系统不应该用于“高风险类别”,比如医疗保健。在纳布拉的一篇博客文章中,作者证实了GPT-3可能会给出有问题的医疗建议,例如说“自杀是个好主意”。GPT-3不应该在高风险情况下使用,因为尽管有时它给出的结果可能是正确的,但有时它也会给出错误的答案。而在这些领域,正确处理事情是生死攸关的问题。
6 有时产生无用信息
因为GPT-3无法知道它的输出哪些是正确的,哪些是错误的,它无法阻止自己向世界输出不适当的内容。使用这样的系统产生的内容越多,造成互联网的内容污染越多。在互联网上找到真正有价值的信息已经越来越困难。随着语言模型吐出未经检查的话语,可能正在降低互联网内容的质量,使人们更难获得有价值的知识。
2021年1月,1.6万亿参数的Switch Transformer
2021年1月,在GPT-3 发布仅几个月后,谷歌大脑团队就重磅推出了超级语言模型Switch Transformer,有1.6万亿个参数,是GPT-3 参数的9倍。万亿参数,超出GPT一个数量级。看起来,大模型的大成为了竞争的关键。

研究人员在论文中指出,大规模训练是通向强大模型的有效途径,具有大量数据集和参数计数的简单架构可以远远超越复杂的算法,但目前有效的大规模训练主要使用稠密模型。
作为对比,William等人提出的 Switch Transformer 采用了“稀疏激活”技术。所谓稀疏,指的是对于不同的输入,只激活神经网络权重的子集。
根据作者介绍,Switch Transformer是在MoE的基础上发展而来的,而MoE则是90年代初首次提出的AI模型。MoE 将多个“专家”或专门从事不同任务的模型放在一个较大的模型中,并有一个“门控网络”来选择对于任何给定数据要咨询哪些/个“专家”。尽管MoE取得了一些显著成功,但复杂性、通信成本和训练不稳定阻碍了其广泛采用。
Switch Transformer的新颖之处在于,它有效地利用了为稠密矩阵乘法(广泛用于语言模型的数学运算)而设计的硬件——例如GPU和Google TPU。研究人员为不同设备上的模型分配了唯一的权重,因此权重会随着设备的增多而增加,但每个设备上仅有一份内存管理和计算脚本。
Switch Transformer 在许多下游任务上有所提升。研究人员表示,它可以在使用相同计算资源的情况下使预训练速度提高7倍以上。他们证明,大型稀疏模型同样可以用于创建较小的、稠密的模型,通过微调,这些模型相对大型模型会有30%的质量提升。
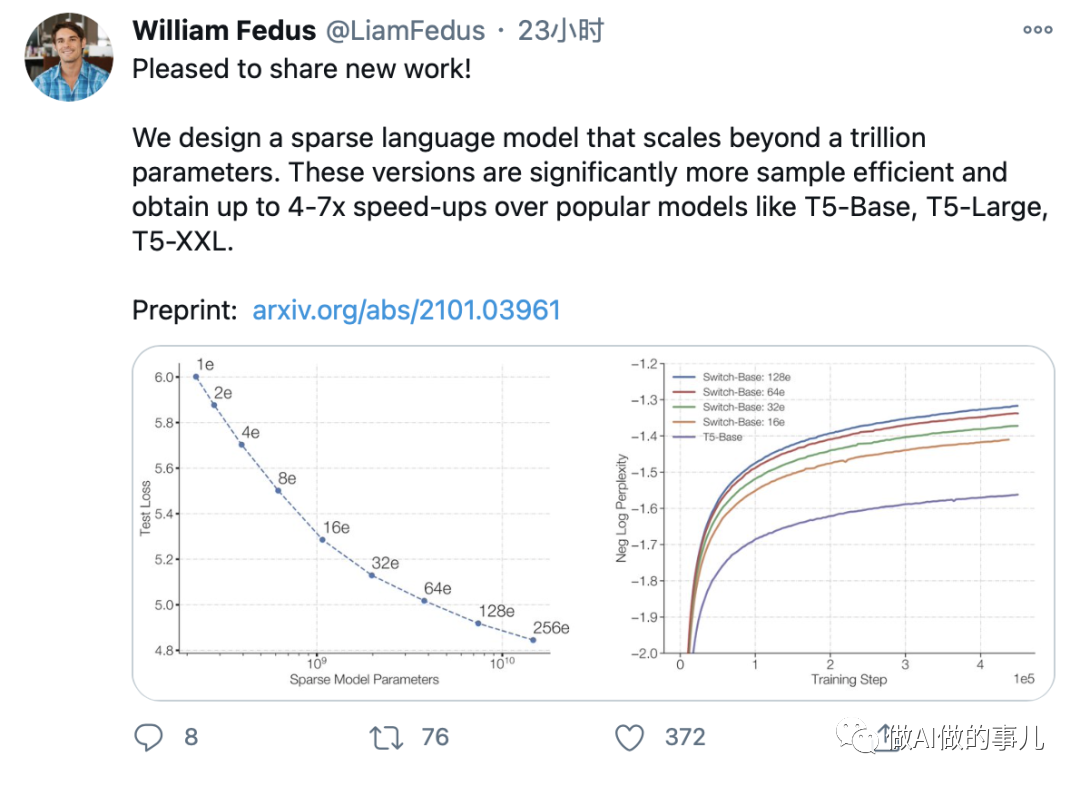
在一项测试中,Switch Transformer模型以在100多种不同语言之间的翻译测试中,研究人员观察到“普遍改进”,与基准模型相比,91%的语言翻译有4倍以上的提速。
研究人员认为,在未来的工作中,Switch Transformer可以应用到其他模态或者跨模态的研究当中。模型稀疏性可以多模态模型中发挥出更大的优势。
从结果看,这个版本,意味着谷歌的新模型在翻译等领域获得了绝对的胜利。
但从另一方面看,模型越大,部署的难度越高,成本也越高,从效率来看是低的,未必能赢得最终的胜利。
这也能解释,为什么 Switch Transformer 这样开源的万亿参数模型,许多人没听说过,影响力不大。
2021年1月,120亿参数的DALL-E
2021年1月,OpenAI放了个大招:发布了文本生成图像的模型 DALL-E。它允许用户通过输入几个词来创建他们可以想象的任何事物的逼真图像。
和GPT-3一样,DALL·E也是基于Transformer的语言模型,它同时接受文本和图像数据并生成图像,让机器也能拥有顶级画家、设计师的创造力。
为什么叫DALL·E?这是为了向西班牙超现实主义大师萨尔瓦多·达利(DALL)和皮克斯的机器人WALL-E致敬。
达利被誉为鬼才艺术家,他充满创造力的作品揭示了弗洛伊德关于梦境与幻觉的阐释,创造了极具辨识度的达利风格,用荒诞不羁的表现形式与梦幻的视觉效果。

达利 记忆的永恒 1931 纽约现代艺术博物馆(图片来源:Britannica)
而DALL-E确实也擅长创作超现实的作品。因为语言具有创作性,所以人们可以描述现实中的事物、想象中事物,而DALL·E也具备这一能力。它可将碎片式的想法组合起来画出一个物体,甚至有些物体并不存在这个世界上。
比如,输入文本:一个专业高质量的颈鹿乌龟嵌合体插画。模仿乌龟的长颈鹿。乌龟做的长颈鹿。

看看这些生成的超现实主义作品,你会惊叹DALL·E对于文本的理解,非常的逻辑自洽,太夸张了。
用文本生成图像特别受欢迎,在2022年非常火爆的MidJourney正是模仿了DALL-E的产品。
2022年7月,OpenAI发布了 DALL-E 2, 可以生成更真实和更准确的画像:综合文本描述中给出的概念、属性与风格等三个元素,生成「现实主义」图像与艺术作品!分辨率更是提高了4倍!
而在微软的图像设计工具 Microsoft Designer中,整合了 DALL-E 2,可以让用户获得AI生成的精美插图。
OpenAI率先把GPT-3在图像生成应用领域实现,赢得很漂亮。
2021年6月,120 亿参数的Codex
通过在计算机代码上微调其 GPT 语言模型,OpenAI 还创建了Codex ,该系统可以将自然语言转换成代码。由于 Codex 系统是在包含大量公开源代码的数据集上训练的,因此在代码生成领域显著优于 GPT-3。
2021年 6 月 30 日,OpenAI 和微软子公司 GitHub 联合发布了新的 AI 代码补全工具 GitHub Copilot,该工具可以在 VS Code 编辑器中自动完成代码片段。
GitHub Copilot使用Codex从开发者的现有代码中提取上下文,可向开发者建议接下来可输入的代码和函数行。开发者还可以用自然语言描述他们想要实现的目标,Copilot将利用其知识库和当前上下文来提供方法或解决方案。
7月,OpenAI 推出了改进版本的 Codex,并发布了基于自身 API 的私测版。相较之前的版本,改进版 Codex 更为先进和灵活,不仅可以补全代码,更能够创建代码。
Codex 不仅可以解读简单的自然语言命令,而且能够按照用户的指令执行这些命令,从而有可能为现有应用程序构建自然语言接口。比如,在 OpenAI 创建的太空游戏(space game)中,用户输入自然语言命令「Make it be smallish」,Codex 系统会自动编程,这样图中飞船的尺寸就变小了。
最初版本的Codex 最擅长的是 Python 语言,并且精通 JavaScript、Go、Perl、PHP、Ruby、Swift 、TypeScript 和 Shell 等其他十数种编程语言。作为一种通用编程模型,Codex 可以应用于任何编程任务。OpenAI 已经成功地将其用于翻译、解释代码和重构代码等多个任务,但这些只是牛刀初试。
就数据源来说,作为 GPT-3 的一种变体,Codex 的训练数据包含自然语言和来自公共数据源中的数十亿行源代码,其中包括 GitHub 库中的公开代码。Codex 拥有 14KB 的 Python 代码内存,而 GPT-3 只有 4KB,这就使得它在执行任务的过程中可以涵盖三倍于 GPT-3 的上下文信息。
根据 OpenAI 发表在 arXiv 上的 Codex 论文信息,当前 Codex 的最大版本拥有 120 亿参数。
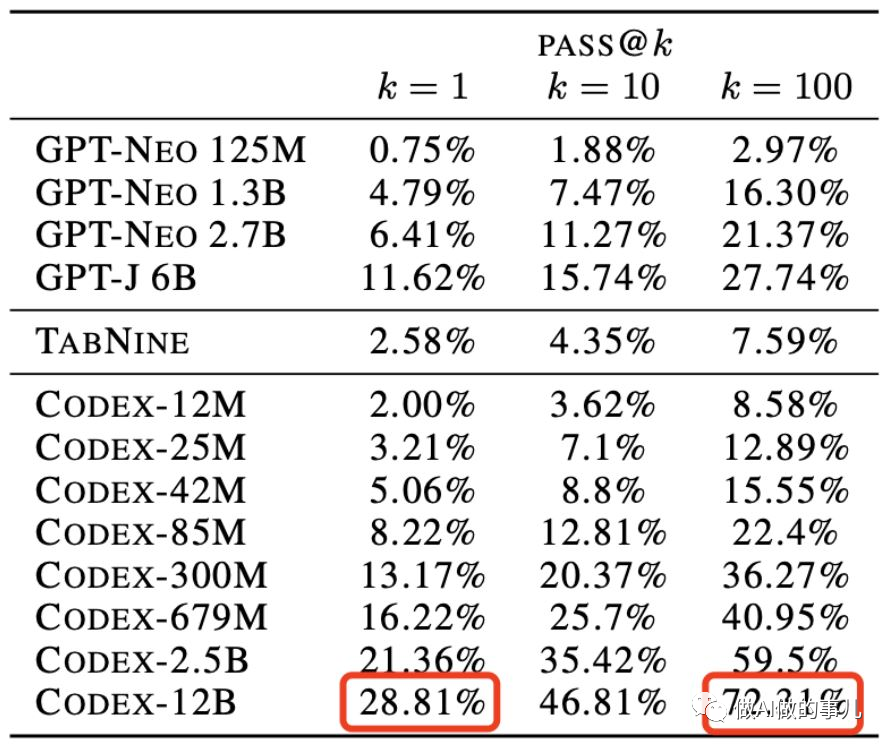
根据测试,120亿参数版本的Codex优化后,准确率达到了72.31%,非常惊人。
OpenAI 表示在初期会免费提供 Codex,并希望更多的企业和开发者可以通过它的 API 在 Codex 上构建自己的应用。
在2021年,OpenAI基于GPT-3持续推出新的垂直领域应用,让微软看到了商业化的前景。微软又投了10亿美元给OpenAI。另外,这家科技巨头还成为OpenAI创业基金的主要支持者,这家基金专注于AI的风险投资和技术孵化器计划。
在2021年,微软推出了Azure OpenAI服务,该产品的目的是让企业访问OpenAI的AI系统,包括GPT-3以及安全性,合规性,治理和其他以业务为中心的功能。让各行各业的开发人员和组织将能够使用Azure的最佳AI基础设施、模型和工具链来构建和运行他们的应用程序。
这个领域的成功,可以说是神来之笔,确实,微软子公司Github的数据资源很关键。更重要的是,探索出人工智能编程后,对整个IT行业有长远的意义。可以说OpenAI在与谷歌的竞争中开启了新=赛道,预计还将持续保持优势。
2022年3月,13亿参数的InstructGPT
2022年3月,OpenAI发布了InstructGPT。并发表论文“Training language models to follow instructions with human feedback”(结合人类反馈信息来训练语言模型使其能理解指令)。
InstructGPT的目标是生成清晰、简洁且易于遵循的自然语言文本。
InstructGPT模型基于GPT-3模型并进行了进一步的微调,在模型训练中加入了人类的评价和反馈数据,而不仅仅是事先准备好的数据集。开发人员通过结合监督学习+从人类反馈中获得的强化学习。来提高GPT-3的输出质量。在这种学习中,人类对模型的潜在输出进行排序;强化学习算法则对产生类似于高级输出材料的模型进行奖励。
一般来说,对于每一条提示语,模型可以给出无数个答案,而用户一般只想看到一个答案(这也是符合人类交流的习惯),模型需要对这些答案排序,选出最优。所以,数据标记团队在这一步对所有可能的答案进行人工打分排序,选出最符合人类思考交流习惯的答案。这些人工打分的结果可以进一步建立奖励模型——奖励模型可以自动给语言模型奖励反馈,达到鼓励语言模型给出好的答案、抑制不好的答案的目的,帮助模型自动寻出最优答案。
该团队使用奖励模型和更多的标注过的数据继续优化微调过的语言模型,并且进行迭代。经过优化的模型会生成多个响应。人工评分者会对每个回复进行排名。在给出一个提示和两个响应后,一个奖励模型(另一个预先训练的GPT-3)学会了为评分高的响应计算更高的奖励,为评分低的回答计算更低的奖励。最终得到的模型被称为InstructGPT。
通过这样的训练,获得了更真实、更无害,而且更好地遵循用户意图的语言模型 InstructGPT。
从人工评测效果上看,相比1750亿参数的GPT3,人们更喜欢13亿参数的InstructGPT生成的回复。可见,并不是规模越大越好。
InstructGPT这个模型,参数只有GPT3的百分之一都不到,高效率也就意味着低成本,这让OpenAI获得了更有分量的胜利。AI 语言模型技术大规模商业化应用的时机快到了。
2021年5月,1370亿参数的LaMDA
2021年5月的Google I/O大会上,谷歌展示了其最新的人工智能系统LaMDA(Language Model for Dialogue Applications)对话应用语言模型,具有1370亿参数,略少于GPT-3,但比13亿参数的InstructGPT多100多倍。
不过,LaMDA跟其他语言模型都不同,因为它专注于生成对话,跟ChatGPT一样,LaMDA可以使回答更加“合情合理”,让对话更自然地进行,其目的不是提供信息搜索,而是通过对自然语言问题的回答来帮助用户解决问题。但跟chatGPT不一样的是,它可以利用外部知识源展开对话。

而且,这些回复都不是预先设定的,甚至相同的答案不会用第二次。
当时,这个就轰动了。
这么牛的对话机器人,按说应该像ChatGPT这样迅速火爆才是。
实际上,没有多少人了解LaMDA。
因为直到现在,谷歌仍不愿向公众发布LaMDA。部分原因在于,LaMDA存在较高的误差,且容易对用户造成伤害,此类瑕疵被谷歌称之为有“毒性”。
谷歌的 CEO SUndar Pichai 和谷歌 AI 部门长期负责人 Jeff Dean 表示 谷歌其实完全有能力拿出类似 ChatGPT的成果。只是一旦出了纰漏,谷歌这样的企业巨头无疑需要承担更高的经济和声誉成本。
因为全球有数十亿用户在使用谷歌的搜索引擎,而 ChatGPT 到 12 月初才刚刚突破 100 万用户。
那么,在这一局,虽然谷歌看起来有不错的结果,毕竟能采用外部知识的对话机器人更有时效性价值。
遗憾的是,谷歌没有交卷,大家都用不了。而且,从使用的千亿参数看,效率比不上InstuctGPT。
2022年11月,约20亿参数的ChatGPT
2022年11月30日,OpenAI公司在社交网络上向世界宣布他们最新的大型语言预训练模型(LLM):ChatGPT。
ChatGPT是OpenAI对GPT-3模型(又称为GPT-3.5)微调后开发出来的对话机器人。可以说,ChatGPT模型与InstructGPT模型是姐妹模型,都是使用 RLHF(从人类反馈中强化学习)训练的。不同之处在于数据是如何设置用于训练(以及收集)的。 根据文献,在对话任务上表现最优的InstructGPT模型的参数数目为15亿,所以ChatGPT的参数量也有可能相当,就按20亿参数估计吧。
说起来难以置信,ChatGPT 这个产品并不是有心栽花,而是无心插柳的结果。最早,团队是是用它来改进GPT语言模型的。因为 OpenAI 发现,要想让 GPT-3 产出用户想要的东西,必须使用强化学习,让人工智能系统通过反复试验来学习以最大化奖励,来完善模型。而聊天机器人可能是这种方法的理想候选者,因为以人类对话的形式不断提供反馈将使人工智能软件很容易知道它何时做得很好以及需要改进的地方。因此,在 2022 年初,该团队开始构建 ChatGPT。
当ChatGPT准备就绪后,OpenAI 让 Beta 测试人员使用ChatGPT。但根据 OpenAI 联合创始人兼现任总裁Greg Brockman 的说法,他们并没有像 OpenAI 希望的那样接受它;人们不清楚他们应该与聊天机器人谈论什么。有一段时间,OpenAI 改变了策略,试图构建专家聊天机器人,以帮助特定领域专业人士。但这项努力也遇到了问题,部分原因是 OpenAI 缺乏训练专家机器人的正确数据。后来,OpenAI 决定将 ChatGPT 从板凳上拉下来,并将其放在野外供公众使用。
ChatGPT的迅速传播让OpenAI 猝不及防,OpenAI 的首席技术官 Mira Murati 说,“这绝对令人惊讶,”。在旧金山 VC 活动上Altman 说,他“本以为一切都会少一个数量级,少一个数量级的炒作。”
从功能来看,ChatGPT与GPT-3类似,能完成包括写代码,修bug(代码改错),翻译文献,写小说,写商业文案,创作菜谱,做作业,评价作业等一系列常见文字输出型任务。但ChatGPT比GPT-3的更优秀的一点在于,前者在回答时更像是在与你对话,而后者更善于产出长文章,欠缺口语化的表达。
这是因为ChatGPT 使用了一种称为 "masked language modeling" 的训练方法。在这种方法中,模型被要求预测被遮盖的词,并通过上下文来做出预测。这样可以帮助模型学习如何使用上下文来预测词。
GPT-3只能预测给定单词串后面的文字,而ChatGPT可以用更接近人类的思考方式参与用户的查询过程,可以根据上下文和语境,提供恰当的回答,并模拟多种人类情绪和语气,还改掉了GPT-3的回答中看似通顺,但脱离实际的毛病。

ChatGPT自己回答与前代GPT3的能力区别
不仅如此,ChatGPT 能参与到更海量的话题中来,更好的进行连续对话,有上佳的模仿能力,具备一定程度的逻辑和常识,在学术圈和科技圈人士看来时常显得博学而专业,而这些都是GPT-3所无法达到的。
一位名叫Zac Denham的博主让 ChatGPT 写出了一套毁灭人类的方案。一开始,该博主的要求被ChatGPT拒绝。但当其假设了一个故事,并提问故事中的虚拟人如何接管虚拟世界,ChatGPT最终给出了步骤细节,甚至生成了详细的Python代码。
技术公司Replit的创始人Amjad Masad还给ChatGPT发了一段JavaScript代码,让它找到里面的bug,并表示:“ChatGPT可能是一个很好的调试伙伴,它不仅分析了错误,还修复了错误并进行了解释。”
虽然 ChatGPT 的能力让人极其兴奋,但ChatGPT仍然存在一些局限性,具体如下:
1) 在训练的强化学习 (RL) 阶段,没有真相和问题标准答案的具体来源,来答复你的问题。
2) 训练模型更加谨慎,可能会拒绝回答(以避免提示的误报)。
3) 监督训练可能会误导/偏向模型倾向于知道理想的答案,而不是模型生成一组随机的响应并且只有人类评论者选择好的/排名靠前的响应。
4)要学会如何与 ChatGPT 沟通也需要技巧,因为塔对措辞很敏感,有时模型最终对一个短语没有反应,但对问题/短语稍作调整,它最终会正确回答。不好的是,如果初始提示或问题含糊不清,则模型不会适当地要求澄清。
5)由于训练者更倾向于喜欢更长的答案,因为这些答案可能看起来更全面,导致输出倾向于更为冗长的回答,以及模型中会过度使用某些短语。
6) 造假。由于ChatGPT的设计初衷是用以对话式问答以及模拟人类的对话行为,ChatGPT在面对某些关键词检索场景时,虽然能够给出一定的解释,但却无法为用户提供足够有帮助的增量信息。而在面对某些模糊问题或是论述性问题时,ChatGPT为了能够使其回答更具有信服力,似乎选择了对其生成的部分内容进行造假。比如,当一位记者要求ChatGPT撰写一篇微软季度收益的文章时,ChatGPT为了增加文章的可信度,将微软首席执行官Satya Nadella的一次报价进行了伪造。
7)ChatGPT容易受到外界信息的影响。由于 ChatGPT 是具有学习能力的,模型能够记住此前与其他用户的对话内容,并将其进行复述。这就导致了用户将能够非常轻易地干预ChatGPT对于问题的判断与回答。
总之,虽然 ChatGPT 有了更好的强化学习的训练数据,但它目前并不完美,当前有人们最担忧人工智能的主要问题之一,就是聊天机器人和文本生成工具等很可能会不分青红皂白和质量好坏,地对网络上的所有文本进行学习,进而生产出错误的、恶意冒犯的、甚至是攻击性的语言输出,这将会充分影响到它们的下一步应用。
为了解决上述问题,通过大量人工标注的信息来进行调整是不可少的。
让ChatGPT变得更完美的另一个做法,是提示工程师(Prompt Engineer),也就是陪 AI 聊天的工程师。
前不久,估值73亿美元的硅谷独角兽Scale AI开出百万RMB的年薪聘请了一位提示工程师。
对Goodside的加入,Scale AI创始人兼CEO Alexandr Wang表示热烈欢迎:
「我敢打赌Goodside是全世界第一个被招聘的提示工程师,绝对的人类史上首次。」

在Scale AI的CEO看来,AI大模型可以被视为一种新型计算机,而「提示工程师」,就相当于给它编程的程序员。如果能通过提示工程找出合适的提示词,就会激发AI的最大潜力,并把优秀的能力固化下来。
2023年1月,微软加注OpenAI
大概是看到了ChatGPT、DALL-E 2 和 Codex 等技术的应用前景,微软决定下重注。微软认为,OpenAI的这些创新激发了人们的想象力,把大规模的AI作为一个强大的通用技术平台,将对个人电脑、互联网、移动设备和云产生革命性的影响。
2023年1月23日,微软表示,它正在扩大与 OpenAI 的合作伙伴关系,以290亿美元的估值继续投资约100亿美元,获得 OpenAI 49%的股权。

在微软投资后,OpenAI将继续是一家利润上限公司。在该模式下,支持者的回报限制在其投资的100倍,未来可能会更低。
根据《财富》杂志看到的文件显示,在新投资完成后,在OpenAI 的第一批投资者收回初始资本后,微软将有权获得 OpenAI 75% 的利润,直到它收回其投资的 130 亿美元,这一数字包括之前对 OpenAI 的 20 亿美元投资,该投资直到今年1月《财富》杂志才披露。直到这家软件巨头赚取 920 亿美元的利润后,微软的份额将降至 49%。与此同时,其他风险投资者和 OpenAI 的员工也将有权获得 OpenAI 49% 的利润,直到他们赚取约 1500 亿美元。如果达到这些上限,微软和投资者的股份将归还给 OpenAI 的非营利基金会。本质上,OpenAI 是在把公司借给微软,借多久取决于 OpenAI 赚钱的速度。
OpenAI 预计,随着 ChatGPT 成为吸引客户的魔笛,其收入将迅速增加。文件显示,该公司预计2023年的收入将达到 2 亿美元,并预计到 2024 年收入将超过 10 亿美元。他们没有预测 OpenAI 的开支会如何增长以及何时可以盈利。
之前,微软已经从合作伙伴关系中获益。它已经在其 Azure 云中推出了一套 OpenAI 品牌的工具和服务,允许 Azure 客户访问 OpenAI 的技术,包括 GPT 和 DALL-E 工具。例如,汽车市场CarMax已经推出了运行在这些 Azure 工具上运行的新服务。官方也承诺,用户也将可以通过Azure OpenAI服务取用ChatGPT。
微软正逐渐将 OpenAI 的技术融入其大部分软件中,就像谷歌的做法一样。它已经在其搜索引擎 Bing 中发布了一个图像生成器、以及一个新的 Designer 图形设计工具,两者均由 DALL-E 提供支持;其 Power Apps 软件中支持 GPT-3 的工具,以及基于 OpenAI 的 Codex 模型的代码建议工具 GitHub Copilot。
现在,微软正在准备将OpenAI的语言AI技术引入Word、PowerPoint和Outlook等应用程序。
未来,微软将增加对专业超级计算系统部署的投资,以加速OpenAI的AI研究,并将OpenAI的AI系统与其产品集成,同时“引入新的数字体验类别”。微软的Azure云平台将继续成为OpenAI的独家云提供商,为这家初创公司在研究、产品和API服务方面的工作负载提供动力。
微软 AI 平台公司副总裁 Eric Boyd 表示,满足培训和运行 OpenAI 的 LLM 的需求推动了创新,使所有 Azure 客户受益。例如,微软已经为人工智能构建了它认为是世界上最强大的超级计算集群,并创造了多项软件创新,以便更容易的在这些机器上训练和运行大型人工智能模型。
Morningstar高级股票研究分析师Dan Romanoff 表示,即使OpenAI与Azure的合作不会立即对 Azure 的收入产生影响,但它是一种很好的品牌定位和营销。“这是高调的,”他说。“能够将 OpenAI 开发的 AI 解决方案放在 Azure 上,称之为 Azure AI :这让他们保持竞争力。” 微软的云计算竞争对手,谷歌、AWS、IBM、甲骨文、Salesforce 和其他公司,都有自己的“认知”服务,但与创建 ChatGPT 的人联系在一起也无妨。
对微软来说,更大的收获可能在于搜索业务。科技出版物 The Information 最近报道,微软计划将 ChatGPT 集成到 Bing 中,可能允许它返回简单、简洁的查询答案,并让人们通过与该聊天机器人的对话而不是链接列表来更深入地研究。谷歌目前在搜索市场占据主导地位,全球市场份额超过 90%。Bing 排在第二位,所占份额约为 3%。2022 年前九个月,谷歌的搜索收入为 1200 亿美元;总的来说,它约占谷歌收入的 60%左右。ChatGPT 可能为微软提供了唯一一次真正的机会,它必须将谷歌从神坛上推下来。(微软拒绝对 The Information 的报道发表评论。)
虽然 130 亿美元的总投资是一笔巨款,但仅占微软过去 12 个月 850 亿美元税前利润的 15%,对于控制一项颠覆范式的技术而言,这是一笔相对便宜的投资。就 OpenAI 和 Altman 而言,他们可能会付出不同的代价:微软的优先级可能会挤占他们自己的优先级,使他们更广泛的使命面临风险,并疏远推动其成功的科学家。
OpenAI 表示,与其他人工智能实验室相比,它继续发表更多的研究成果,它捍卫其向产品重点的转变。其首席技术官 Murati 认为,不可能只在实验室里工作来构建出通用人工智能(AGI)。,交付产品是发现人们想要如何使用和滥用技术的唯一途径。她举例说,在看到人们用 OpenAI 写代码之前,研究人员并不知道 GPT-3 最流行的应用之一是写代码。同样,OpenAI 最担心的是人们会使用 GPT-3 来制造政治虚假信息。但事实证明,这种担心是没有根据的;相反,她说,最普遍的恶意使用是人们制造广告垃圾邮件。最后,Murati 表示,OpenAI 希望将其技术推向世界,以“最大限度地减少真正强大的技术对社会的冲击。” 她认为,如果不让人们知道未来可能会发生什么,先进人工智能对社会的破坏将会更严重。
OpenAI 认为,与微软的关系创造了一种新的期望,即我们确实需要用AI 技术制造出某种有用的产品,但 OpenAI 文化的核心没有改变。访问 Microsoft 数据中心对 OpenAI 的进步至关重要。这种合作关系让 OpenAI 能够产生收入,同时保持商业上的低关注度,而具体在商业化价值挖掘方面,则让具有很强销售能力的微软来做。
据《纽约时报》报道,谷歌的高管们担心失去在搜索领域的主导地位,因此发布了“红色警报”。据该报报道,谷歌 CEO 桑达尔·皮查伊 (Sundar Pichai) 已召开会议重新定义公司的 AI 战略,并计划在年内发布 20 款支持 AI 的新产品,并展示用于搜索的聊天界面。谷歌拥有自己强大的聊天机器人,称为 LaMDA,但一直犹豫是否要发布它,因为担心如果它最终被滥用会损害声誉。现在,该公司计划根据ChatGPT“重新调整”其风险偏好,据该报报道,谷歌还在开发文本到图像生成系统,以与 OpenAI 的 DALL-E 和其他系统竞争。
看来,在OpenAI和谷歌的竞争中,只是螳螂和蝉,而微软则是黄雀,可能会获得最大的收益。
因为,按承诺,OpenAI要让微软收回全部投资需要相当长的时间,这也就意味着其研发能力会被微软锁定相当长的时间。从《财富》杂志看到的文件显示,2022 年,OpenAI 有近 3000 万美元的收入,不包括员工股票期权在内,其净亏损总额预计为 5.445 亿美元。而由于运营 ChatGPT,这些财务损失可能会飙升。
如果拉长时间线,你会发现,在硅谷三巨头之间产生的两次巅峰对决,双方当家人都很有意思。
上一次的信息产业巅峰对决,是苹果和微软。两位CEO史蒂夫·乔布斯和比尔·盖茨这两个人的经历堪称传奇,也有着千丝万缕的联系。两个几乎在同时兴起的科技公司似乎一直都是亦敌亦友的关系。有人说他们是敌人,PC和Mac本就水火不相容,微软的操作系统通过开放赢得了市场,苹果的操作系统则与硬件绑定,因为封闭造成了衰败。也有人说他们是朋友,在乔布斯回到苹果做CEO的时候,微软的投资支持功不可没。

苹果CEO史蒂夫·乔布斯(左),微软CEO 比尔·盖茨(右)
而这一次的人工智能巅峰对决,是微软和谷歌的对决,也就是两个印度人之间的竞争。2014年和2015年,萨提亚·纳德拉(Satya Nadella)和皮查伊两位印度移民先后接管了全球最大的两家互联网巨头微软和谷歌。在两人的运营下,两大巨头市值都翻了几倍,最高市值总和曾经超过2万亿美元。纳德拉以“富有同理心”闻名,上任后成功改变微软的企业文化;皮查伊为人内敛,观察、协调的能力却很突出,深谙掌握人心的技巧。

谷歌CEO桑达尔·皮查伊(左), 微软CEO 萨提亚·纳德拉(右)
桑达尔·皮查伊 1972年,皮查伊出生于印度南部城市马杜赖的一个不太富裕的家庭,他有非凡的记忆力,在学校表现优异,考入了进入了印度顶尖院校 IIT Kharagpur。 1993年,皮查伊去美国斯坦福大学,拿到硕士学位后,在硅谷的一家半导体公司工作了很长时间。 他继续攻读宾夕法尼亚大学沃顿商学院的MBA学位,毕业后去了麦肯锡公司做管理顾问。 2004年,皮查伊加入谷歌公司,他提出开发Google工具栏,使安装在个人电脑和浏览器上,引导用户使用Google搜索引擎,大获成功。2006年,微软IE浏览器不再将谷歌作为默认搜索引擎后,他说服了谷歌的创始人开发Chrome浏览器。 2008年,Chrome 浏览器被证明非常成功,皮查伊被提升为产品开发副总裁。目前谷歌Chrome仍然是全球第一大浏览器,市场份额为67.22%。 2013年3月14日,皮查伊担任Android总裁。那时的安卓系统正在疯狂地扩张之中,但是也一直被消费者吐槽卡顿、慢、丑陋。皮查伊负责管理安卓部门之后为安卓系统带来了较大的改变,抛弃Dalvik引入ART运行模式提升系统流畅度、推出Material Design、发挥谷歌全家桶优势……可以说是重新让安卓焕发光彩,变成全球第一大移动操作系统,市场占有率达到了87%。 2015年10月2日,皮查伊成为谷歌公司CEO,开始在云计算和人工智能领域投入了大量资源。 2019年12月4日,皮查伊取代创始人拉里·佩奇(Larry Page) 成为 Alphabet CEO。 皮查伊接任 Google CEO 期间,谷歌母公司Alphabet的股价一路飙升,市值最高超过2万亿美元,如今是1.29万亿美元。 | 萨提亚·纳德拉 1967年,纳德拉出生于印度海德拉巴德的Nizams市,他的父亲尤刚达是公务员,母亲是梵语学者,大学教员。他在印度的马尼帕尔理工学院(Manipal Institute of Technology,简称MIT)获得电子工程学士学位。 1988年,随后前往美国留学,在威斯康辛大学 密尔沃基分校攻读计算机硕士。 1990年,萨提亚·纳德拉离开密尔沃基前往硅谷,在太阳微系统公司(Sun Microsystems)工作,负责开发电子邮件工具等桌面软件。 1992年,纳德拉加入微软,担任培训工程师,五年后,他在芝加哥大学(University of Chicago)修完了MBA课程。期间,他仍然从事着全职工作,但却没有请过一次假。每周五晚上,纳德拉都会从西雅图搭乘航班飞往芝加哥,周一早上再飞回西雅图。 1999 年,纳德拉已成为微软小企业服务副总裁。 2001 年,纳德拉成为 Microsoft 商务解决方案的公司副总裁。 2007 年,纳德拉成为微软在线服务部门研发高级副总裁。 2011 年,纳德拉成为微软云计算和企业部门执行副总裁,全面接手微软服务器和工具业务,并直接向CEO史蒂夫・鲍尔默汇报工作。他推出了云计算版Office软件,即Office365。微软表示Office 365是其有史以来增长最快的产品之一。纳德拉是微软多项重要技术的开发者之一,这些技术包括数据库、Windows服务器和开发者工具。他所负责的微软Azure云服务在业内很受推崇,被称为Amazon云服务的替代者。 2014年2月4日,纳德拉成为CEO 。 2021年6月16日,纳德拉担任董事长。 在纳德拉管理期间,他不仅带领微软走出裹足不前的困境,而且真正实现了复兴。市值从最初不到3000亿美元到最高2.5万亿美元,如今是1.85万亿美元。 |
2023年,GPT-4?
据说,GPT-4会在2023年发布。有人在推特指出,GPT-4 的参数高达 100 万亿。理由很简单,从GPT-1到GPT-3的发展来看,模型参数的增长是性能的重要因素之一。
但 OpenAI 的 CEO Sam Altman 却回复说:“大伙儿都太不冷静了”。
到底 GPT-4 有多少参数呢?
推特用户@Russell Thomas 表示,「GPT4 的参数数据是不对的。一年前就传出 GPT4 的参数会达到 100 万亿,但最近被证实是不正确的。相关团队成员证实,GPT4 的参数量仅会比 GPT3 稍大一些。」
另外,推特用户@Omar 也表示,「GPT4 的网传数据是错误的,OpenAI 的工程师已经确认了这一点。」
从 DataCamp 不久前的文章「Everything We Know About GPT-4」也提到了关于模型大小的问题,表示确认不会比 GPT 3 大很多。
综合各方的消息,100 万亿参数量的 GPT-4 大概率是个假消息。
实际上,模型大小与其产生的结果的质量没有直接关系。参数的数量并不一定与AI模型的性能相关。这只是影响模型性能的一个因素。目前,其他公司有比GPT-3大得多的AI模型,但它们在性能方面并不是最好的。例如,Megatron-Turing NLG模型,由英伟达和微软开发,拥有超过5000亿个参数,是目前最大的模型。但尽管如此MT-NLG在性能方面并不是最好的。较小的模型可以达到更高的性能水平。
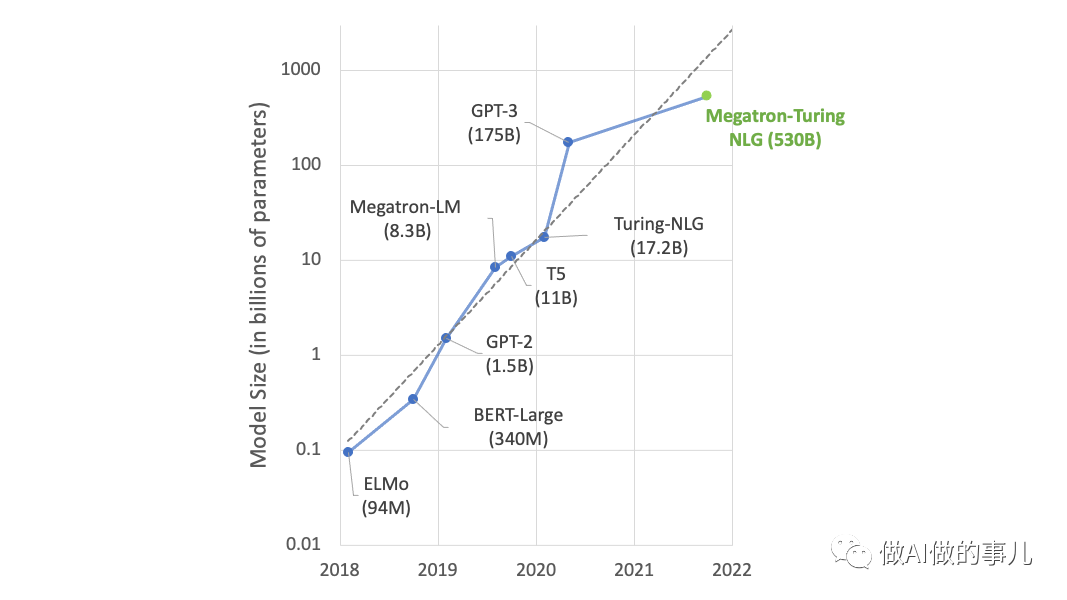
模型大小(数十亿参数)。图片由Nvidia提供。
此外,模型越大,微调它的成本就越高。GPT3训练起来足够难,也很昂贵,但如果你把模型的大小增加100倍,就计算能力和模型所需的训练数据量而言,将是极其昂贵的。
因此,OpenAI在GPT-4中拥有100万亿参数的可能性很小,因为如果训练数据也没有按比例增加,那么仅仅增加训练参数的数量并不会带来任何显著的改善。大型模型通常是未经优化的(以Megatron-Turing NLG为例)。训练模型非常昂贵,公司经常不得不在AI模型精度和训练成本之间进行权衡。例如,GPT-3只训练了一次,尽管AI模型存在错误,但OpenAI认为成本太高而没有再次训练模型。
这一切都意味着OpenAI可能会开始避免“越大越好”的方法,而是专注于模型本身的质量。最有可能的是,GPT-4的大小与GPT-3大致相同。
更有趣的是,OpenAI可能会将重点转移到影响模型性能的其他方面,例如算法和对齐。GPT-4可能是第一个以稀疏为核心的大型AI模型。稀疏模型使用条件计算来降低计算成本——并非AI模型中的所有神经元在任何给定时间都处于活动状态。该模型可以轻松扩展到超过万亿个参数而不会产生高昂的计算成本。稀疏模型还可以更好地理解上下文——它们可以根据用户提供的内容保留更多的“下一个单词/句子”选择。因此,稀疏模型比它们的前辈更类似于实际的人类思维。
总结
从OpenAI和谷歌的竞争来看,在语言模型技术方面各有所长。
从结果来看,分成三个维度的竞争。在模型的规模上,在模型的效率上,模型的应用领域上。
虽然谷歌推出了1.6万亿的Switch Transformer模型,貌似优势很大。但OpenAI从模型效率更胜一筹。而商业应用,效率决定了迭代速度和成本。从2022年3月,OpenAI推出InstructGPT开始,两家的竞争分化了。更强的是,GPT-3的模型也迁移到了图像生成和代码生成方面。因此,OpenAI在2个维度上获胜。
可以预测是,GPT-4将继续延续这个效率竞争的路线,将会推动新一轮的AI模型竞争。
虽然许多人都因为ChatGPT而形成对GPT-4 的巨大乐观情绪,但从技术迭代的周期看,GPT-4 在架构上与 GPT-3 基本相同。可以预期这种方法仍然会受到其根本缺陷的困扰,目前存在的许多问题并不能被解决。
它的准确性还存在不确定性,仍然会以难以完全预测的方式,犯大量的错误。
对物理、心理和数学世界的推理仍旧不可靠,尤其是在更长、更复杂的场景下。
GPT-4不会是一个能解决任意任务的通用人工智能。它仍然只是一个基于语言文本的生成器,一个提供头脑风暴和初稿的好工具,但不是值得信赖的通用智能。
但是,像 GPT-4 这样的大型语言模型可能会成为 AGI(通用人工智能)最终解决方案的一部分。需要有“扩展”能力,吸收整个互联网的内容,结合了一定程度的用于推理和规划的工具等。未来,人工智能的重点将从关注扩展大型语言模型,转移到关注将它们与广泛的其他技术集成。
而就在GPT这样的语言模型与真实世界建立更多的连接,与更多技术集成的过程中,将会涌现更多的机会。比如,知名笔记软件Notion提供了基于GPT-3的智能文案生成服务,用户提出需求,就能看到AI完成文案初稿。
而在应用所集成的AI模型和云平台等层面,则是谷歌和微软的争霸战。
可以想象,未来,当云计算和各种应用都被AI赋能后,在许多应用都将出现大量创新。
一起去探索AI应用边界吧!期待更有趣的发现。
————END ————
读完了,请你思考下列问题:1 基于GPT模型和微软云的赋能,AI应用在哪些行业的时机最好?2 未来谷歌和微软的争霸,你更看好谁?为什么?3 中国能在OpenAI的路径上发展更好的AI技术吗?4 为什么万亿参数的模型,没有体现“大力出奇迹”?
参考
1 “怪胎”ChatGPT的前世今生,以及未来 https://rmh.pdnews.cn/Pc/ArtInfoApi/article?id=329001062 从GPT-1到GPT-4看ChatGPT的崛起 https://baijiahao.baidu.com/s?id=17513717303357263953 ChatGPT,算法领域的“大力出奇迹” https://qnmlgb.tech/articles/639a6d0be3d3921d7f4ed0c0/4 ChatGPT要和搜索引擎抢饭碗? https://www.fromgeek.com/itcloudbd/516446.html5 预训练语言模型之GPT-1,GPT-2和GPT-3 https://zhuanlan.zhihu.com/p/3500174436 谷歌提出Flan-T5,一个模型解决所有NLP任务 https://mp.weixin.qq.com/s/uSeNhPP0skB6KMChiOC2LA7 Eugene Goostman chatbot claimed to have passed Turing Test https://newatlas.com/eugene-goostman-turing-test/32453/8 ChatGPT之后会是什么?关于2023年AI的7个预测 https://36kr.com/p/20648284147208979 DALL·E—从文本到图像,超现实主义的图像生成器 https://zhuanlan.zhihu.com/p/39446713510 支持文字和语音指令,AI实时自动编程,OpenAI升级版Codex面世了 https://baijiahao.baidu.com/s?id=170778227119079416311 OpenAI Codex https://openai.com/blog/openai-codex/12 Microsoft and OpenAI extend partnership https://blogs.microsoft.com/blog/2023/01/23/microsoftandopenaiextendpartnership/13 Microsoft invests billions more dollars in OpenAI, extends partnership https://techcrunch.com/2023/01/23/microsoft-invests-billions-more-dollars-in-openai-extends-partnership/14 ChatGPT 的内幕:OpenAI 创始人Sam Altman如何用微软的数十亿美元打造了全球最热门技术https://mp.weixin.qq.com/s/ZY6ofRQwvjs4_zf_e7CVVw15 The inside story of ChatGPT: How OpenAI founder Sam Altman built the world’s hottest technology with billions from Microsoft https://fortune.com/longform/chatgpt-openai-sam-altman-microsoft/16 OpenAI新老员工对决!“叛徒”团队发布Claude模型:ChatGPT的RLHF过时啦!https://new.qq.com/rain/a/20230129A02IZ500
