原文链接:https://mp.weixin.qq.com/s/ulA4df2wQvZ2y2l7tiazBA
金潇阳 人机与认知实验室
【编者按:人机交互中信息化、自动化与智能化常常并存,信息化强调的是载体流动的通畅有序性,自动化关注的是程序过程的确定性,智能化侧重的是无限关系的有限合理性。】
在刚开始看到GPT3的相关文章时,给我带来了巨大的冲击。因为在之前学习c语言时有老师是这么介绍c语言的,因为机器听不懂人说话,所以需要有一个机器听得懂得语言作为人给机器的命令输入;如果你说的话机器听得懂,你就可以用中文编程。而现在有人告诉我,机器听得懂人说话了!
文中是这样介绍GPT3的:
在设计网页的过程中,可以输入我要一个“长得像西瓜得按钮”机器就会自动生成以下的按钮:
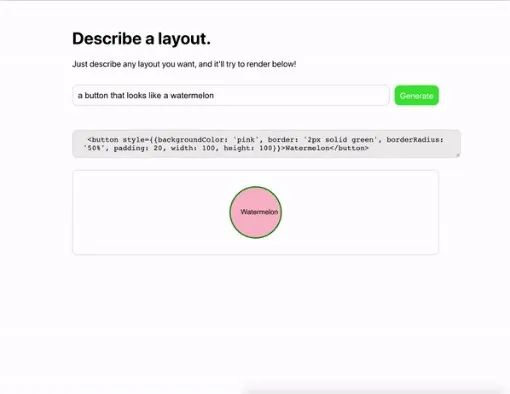
可以看到,在对话框内是输入的自然语言,在对话框下是机器生成的html代码以及按钮的预览图片。
不可否认在自然语言理解这一领域,这是个跨越式的创新,但是,我认为在短期内,这项技术并不能成为真正改变生产力和生产关系的工具。也许可以在网站建立初期使用GPT3建立一个大概的框架,或者是使用GPT3找找网站设计的灵感,但是GPT3不可能替代html、js等网络编程语言成为开发人员的首选。
本文将主要针对语言的歧义、人机交互的方式结合最近看的《自然语言处理问答》和《交互设计:超越人机交互》(第五版)这两本书展开论述。
自然语言和现有的Html代码之间的关系,类似与python、java等脚本语言相对于c、汇编语言的关系。为什么会有计算机语言的产生,是因为计算机读不懂自然语言,所以有经验的计算机工程师建立了一套计算机可以理解的体系,然而这套体系是需要从底层一层一层建立的,从机器码到汇编语言,再到高级语言。从高级的面向对象语言改进到现在是不断适应人们的自然语言习惯的,在c语言中输出还需要定义输出的变量的类型printf("num=%d",num):在c++的输入输出流中就去除了这一步要求,std::cout<<"num="<<num;这样的改进是为了增加这个语言系统的容错性能,例如在不知道这个变量是什么类型的时候仍然可以正常输出。但是每一步的改进都是有利有弊的,python 作为一个易于上手的语言可以说对新手较为友好了,又有丰富的类库可以使用,可能使用opencv实现一个边缘检测或者是使用keras建立一个小的回归模型只需要几行代码就够了。然而Python也并不是一个容易精通的语言,因为python的解释器会在背后做着我们所不能一眼看出来的转换,可能我们以为我们重新定义了一个变量并用已有变量对其进行了赋值,实际上编译器认为我们创建了一个指向现有变量的引用,这就是语言的歧义,连python这类专门设计的计算机语言都经常会出现这种歧义,自然语言更是如此。
那么如何减少歧义,就是重中之重。刘伟老师在《追问人工智能》一书中写道:人机融合智能需要发挥人机各自的长处,只有人机很好地配合在一起才能实现1+1>2的效果(例如辅助决策的过程),在这样的要求下,机器需要学习人,人也需要适应机。在《交互设计:超越人机交互》(第五版)这本书中提到了交互中很重要的一点,即心智模型,人在使用机器时需要运用正确合适的心智模型,那么什么是正确的心智模型?例如在使用空调制热时,空调加热的速度并不会因为温度设定的高低而变快变慢,那么在设定温度时,就只需要设定一个需要达到的温度,而不是先将温度调高于期望温度,希望升温迅速,达到期望温度后再调回期望温度。合理正确的心智模型可以使得人机间的交互更加和谐,为了达到这样的效果,在机器设计的过程中就需要考虑到用户在使用时的因素,需要设计一个更为透明的产品给用户一个清楚的认知过程从而帮助建立合理的心智模型,而用户使用时同样需要阅读说明书来获取建立正确的心智模型,心智模型在人机交互的过程中就是人机之间的一座桥梁,正确映射人类想法和机器实操。放在人机交互的过程中,机是有一定灵活性的,可以通过现有机器学习的方法学习用户的习惯,性格等特征,更好地辅助用户。当机器读不懂用户给的指令,或是用户的指令含糊不清时,就会产生歧义。
此时引入了歧义这个概念
机器在灵活地同时又会带来歧义,如果机器对用户的命令解析不正确,往往会背道而驰。在李维老师《自然语言处理问答》这本书中,大量的篇幅用来解释如何消除自然语言分析的歧义,同时也提到了可以保留一些歧义,在过早剪枝和维度爆炸两种情况之间找到平衡点。香农对信息的定义为“信息是用来消除随机不定性的东西”。同样的,在自然语言的处理中的消歧也是同样的道理,若是在分词阶段过早消歧,计算机在少量的信息前只能使用专家指定的规则和字典中的注释来选出当前最合适的内容,此时极容易产生误读,又由于分词处在分析的第一步,会产生错误的叠加。
适度的保留歧义,举《自然语言处理问答》一书中的例子:49年既可以理解为四十九年也可以理解为1949年,此时产生了歧义,但是这类歧义是面向内部的歧义,无论是四十九年还是1949年都是一个时间成分,不影响对下文或是句式结构的解读。若是遇到无法避免结构上的歧义,可以选择性得保留另外一枝,数中提出了休眠和激活这一方法,可以将可能性较小得那一枝结构休眠,如果解析得过程中发现激活那一枝的条件,则重新激活另一支结构。
谈到消除歧义的问题,在自然语言处理方面我不能班门弄斧,接下来会结合人机交互谈一点自己的看法。
因为当前的自然语言处理属于无人系统,所以会遇到如此多的麻烦困难,但是如上文介绍的GPT3系统,既然是面向使用自然语言编程的,自然包含了人机的互动,许多系统自生难以消除的歧义可以同过和人的交互消除,机器可以对难以消除的歧义提问,而用户可以根据自己的想法理解回答,在李维老师《自然语言处理问答》一书中同样提到了在系统的使用过程中可以在遇到新词时更新词典词,或者使用一些统计方法让系统自动更新建立词汇之间的隐含联系。上文的例子中,给我一个像西瓜一样的按钮,并没有输入按钮的大小,按钮的位置,按钮的点击方式(双击,单机,长按),这些可能都是机器根据自己系统中的信息储备来定义的,然而要真正实现用自然语言编程,用户需要对细节可控,因为这些细节在真正应用到实际的生产生活中是非常重要的。正如现在的IDE变得越来越方便,当前的IDE在辅助用户编程时采取的措施是搜索首字母或是关键字自动出现下拉框,框中有用户可能会选择的函数题和变量名,这类辅助的方式我将其姑且称为提醒方式,也就是机器用相比人类近乎于无限的记忆力(储存空间)帮用户省去了记住繁琐的变量名的过程,可以将注意力集中在程序逻辑上。在GPT3这个系统中,应该设置询问用户细节的环节,用户想要一个按钮,那么系统告知用户建立一个按钮需要设置多少参数,引导用户一个个填充输入,然而这样又失去了使用自然语言编程简单,开放性强的初衷。所以我觉得GPT3作为一个自然语言分析系统的展品是十分出色的,代表了前沿的自然语言处理技术,同时它也展现了这项技术在工业界的应用;但是在自然语言编程这一条路上,它走的还不够远,所以目前为止,我依旧认为使用自然语言编程还停留在一个基本的构想阶段,要真正实现应用还有很长的路要走。
最后的结论有些令人失望,但是我依旧对未来人工智能的发展满怀期待,期待机器真正听得懂人说话的一天早一些到来!
是交互产生了“我”或者“谁”及“哪来”、“哪去”
