原文链接:https://mp.weixin.qq.com/s/ym9gvhImdOzDvR2LpC5Tig
原创 ScienceAI
编辑 | 白菜叶
在评估选择时,人们经常遭受两个悲剧性的相对论。首先,当我们的生活变得更好时,我们会迅速适应更高的生活水平。其次,我们不能逃避将自己与各种相关标准进行比较。「习惯」和「比较」可能会对决策和幸福造成非常大的破坏,迄今为止,为什么它们首先成为认知的一部分仍然是一个谜。在这里,普林斯顿大学的研究人员提出的计算证据表明这些特征可能在促进适应性行为中发挥重要作用。使用强化学习的框架,他们探索了使用奖励函数的好处,除了基础任务提供的奖励之外,还取决于先前的期望和相对比较。该团队发现,虽然配备了这种奖励功能的智能体不太开心,但它们学习速度更快,并且在各种环境中显着优于标准基于奖励的智能体。具体来说,相对比较通过为代理提供探索激励来加速学习,并且先前的期望对比较有帮助,尤其是在奖励稀疏和非平稳的环境中。他们的模拟还揭示了这种奖励函数的潜在缺点,并表明当不检查比较以及有太多类似选项时,代理的表现并不理想。总之,该研究的结果有助于解释为什么人们容易陷入永无止境的欲望和欲望的循环中,并可能揭示抑郁、物质主义和过度消费等精神病理学。该研究以「The pursuit of happiness: A reinforcement learning perspective on habituation and comparisons」为题,于 2022 年 8 月 4 日发布在《Plos Computational Biology》。

从古代宗教文本到现代文学,人类历史上充斥着描述为实现永恒幸福而奋斗的故事。矛盾的是,幸福是最受追捧的人类情感之一,但从长远来看,对许多人来说,实现它仍然是一个难以实现的目标。这种追求变得困难,特别是因为幸福不仅仅是一个人当前状态的函数,而是受到两个相对论的困扰。首先,幸福取决于一个人先前的期望,而这些期望会适应当前的情况。生活方式的积极改变会产生幸福感的「提升」,但这种提升通常不会持续很长时间,人们会很快适应更高的生活水平(恰如其分地创造了「享乐跑步机」)。其次,幸福感受相对比较的影响。除了他们所拥有的绝对水平之外,人们经常关心他们所拥有的与他们希望达到的理想水平(所谓的「渴望水平」)之间的差异。适应性期望和相对比较的动态对心理健康和幸福有重大影响——它们可能导致永无止境的欲望和欲望的恶性循环,即使在有利的情况下也让人们感到痛苦。这些特征对社会的显着和动荡的影响提出了一个重要问题:为什么行为首先会受到习惯和比较的影响?该领域长期以来的一个假设是,这些相对特征可能提供了进化优势,但是,仍然缺乏对这些相对方面如何以及为什么可能是智能代理的理想特征的精确描述。在本文中,普林斯顿大学的心理专家与计算机专家合作,通过采用强化学习 (RL) 的计算框架来提供习惯和比较的成本和收益的观点;在该框架中,可以正式区分所谓的客观和主观奖励函数。RL 历来提供了一个丰富而全面的框架来理解以价值为导向的行为。在标准 RL 理论中,奖励函数用于定义最佳行为,即代理「应该」完成什么。这在实验确定的环境中很容易,但在更开放的自然环境中更难。然而,在任何一种情况下,这种奖励函数都是客观的,因为它们直接由当前任务决定,并且它们确定了环境设计者(或者,在更复杂的意义上,进化)希望智能体实现什么。
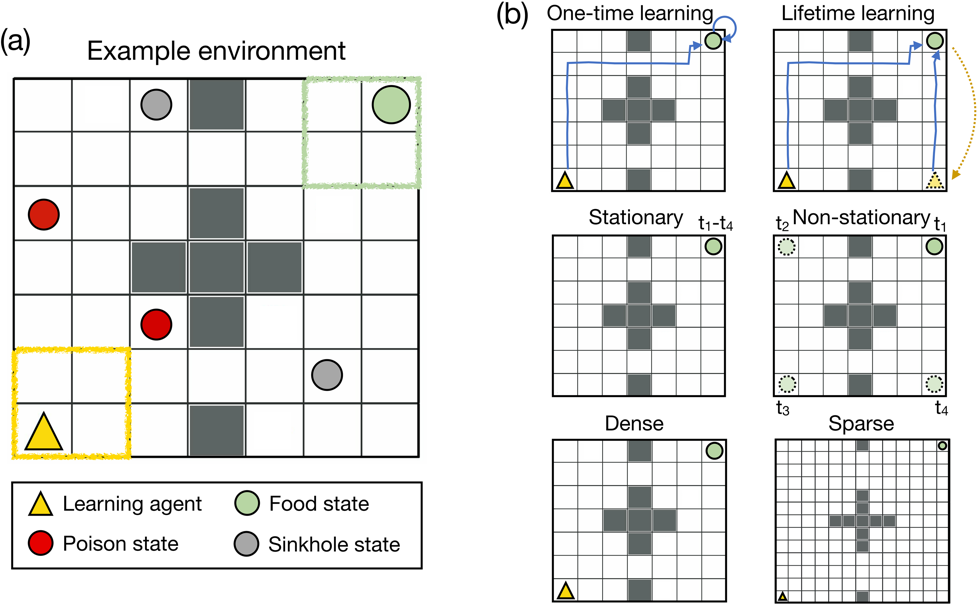
图示:环境设计。(来源:论文)
然而,最近的机器学习文献已经接受了这样的观察,即奖励函数在 RL 中扮演第二个关键角色,将代理从无能转向精通,因此研究了奖励设计的策略。这些指导奖励功能通常由设计者提供给代理,具有与特定任务分离的主观特征,但仍然可以指导代理的学习。在这里,研究人员考虑基于习惯和比较的主观奖励功能是否可以引导智能体胜任客观成功。具体来说,他们赋予智能体一个主观奖励功能,除了特定于任务的客观奖励之外,还取决于先前的期望和相对比较。然后,研究人员将这些代理嵌入到各种参数化环境中,并将它们的性能与标准 RL 代理进行比较,后者的奖励函数仅取决于客观奖励值。
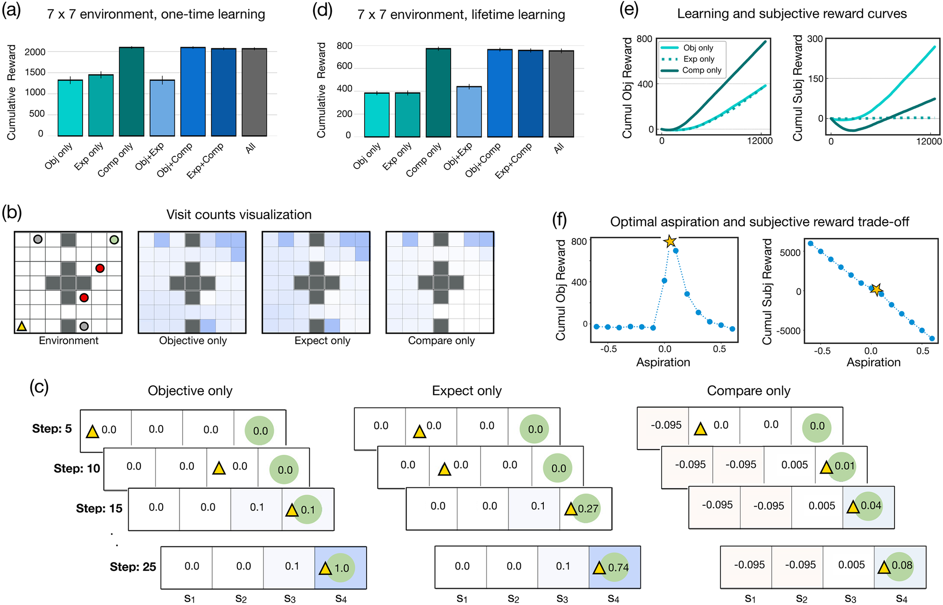
图示:比较改进了简单密集、静止环境中的学习。(来源:论文)
广泛的计算模拟表明,奖励函数依赖于这些附加特征的代理学习得更快,并且明显优于标准的基于奖励的代理。值得注意的是,这种奖励功能在稀疏奖励和非平稳环境中提供了巨大的好处,这些环境对于标准强化学习来说是相当具有挑战性的。
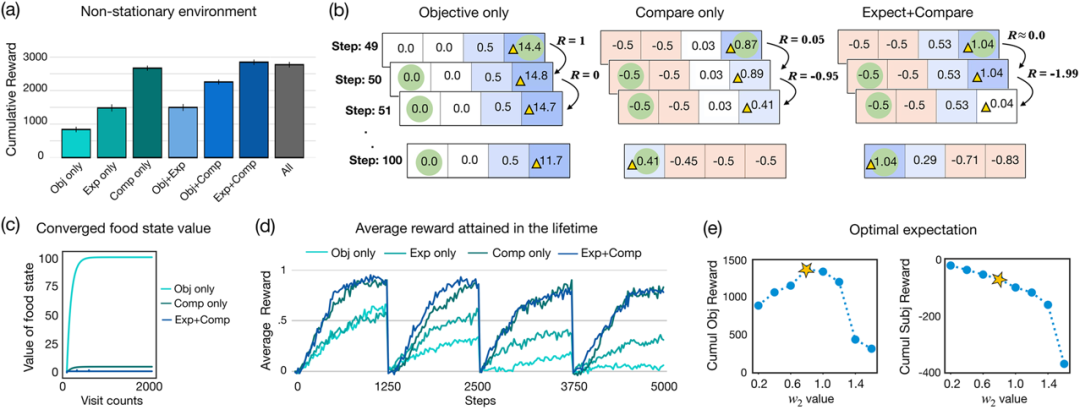
图示:先前的期望和比较使代理对环境的变化具有稳健性。(来源:论文)
该研究结果表明,基于先前期望和比较的主观奖励函数可能通过作为强大的学习信号在促进适应性行为方面发挥重要作用。这为该领域的长期假设提供了计算支持,并解释了为什么人类奖励函数可能基于这些特征。
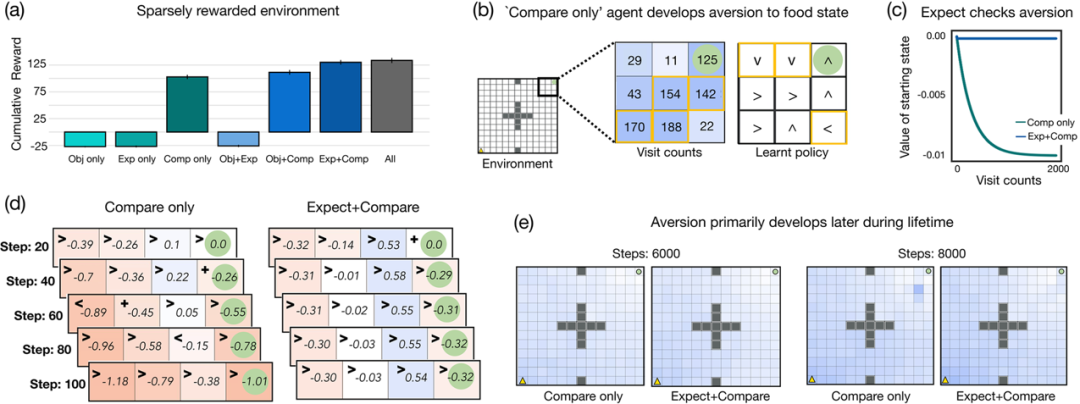
图示:在奖励稀少的环境中,相对比较可能会导致不良行为。(来源:论文)
同时,研究人员的模拟也揭示了该功能的潜在缺陷。他们发现,在愿望水平不受控制且变得过高的环境中,代理的表现并不理想。另外,这些智能体遭受「选择悖论」——当它们处于不同选项彼此非常相似的环境中时,它们并没有提高性能并且一直不满意。总而言之,这些结果为基于适应性期望和相对比较的奖励函数提供了计算基础,并可能阐明抑郁、物质主义和过度消费等精神病理学。
论文链接:https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1010316相关报道:https://phys.org/news/2022-08-learningbased-simulations-human-desire.html
