原文链接:https://mp.weixin.qq.com/s/A45YqMcQeULULGFL05qBCA
原创 微软亚洲研究院
编者按:作为目前全球最负盛名的人工智能盛会之一,NeurIPS (Conference on Neural Information Processing Systems) 在每年年末都是计算机科学领域瞩目的焦点。被 NeurIPS 接收的论文,代表着当今神经科学和人工智能研究的最高水平。今年的 NeurIPS 大会将于11月28日至12月9日举行,本届大会共收到10411篇有效投稿,其中2672篇获接收,最终接收率为25.6%。相比去年,投稿数量继续增加。
在本届大会中,微软亚洲研究院也有诸多论文入选,内容主要涵盖人工智能五大热点话题:人工智能走向大一统、计算机理论、赋能产业界的人工智能、负责任的人工智能、人工智能赋能内容与设计生成。在接下来的几周里,我们将按话题与大家分享相关领域的学术最前沿!今天,让我们先从“人工智能走向大一统”和“计算机理论”话题下的8篇论文精华开始。
欢迎参与文末投票,选出你最想看的论文直播!

人工智能走向大一统
The Big Convergence of AI
01
针对强化学习的掩码隐空间重建

论文链接:
https://www.microsoft.com/en-us/research/publication/mask-based-latent-reconstruction-for-reinforcement-learning/
视觉状态表征的质量对基于视觉的强化学习(vision-based reinforcement learning)至关重要。为了学习高效的状态表征,微软亚洲研究院的研究员们创新性地将基于掩码的建模技术(mask-based modeling)应用到强化学习中,以促进其状态表征学习。此前基于掩码的建模技术已经在 CV 和 NLP 领域中大放异彩,而这项工作是将其应用到强化学习领域帮助策略学习的首次探索。
具体地,研究员们提出了一种简单而有效的自监督方法,即基于掩码的隐空间重建 (mask-based latent reconstruction,简称为 MLR)。MLR 通过从具有时空掩码的视觉状态中预测其在隐空间中的完整表征,从而使神经网络在学习状态表征时能够更好地利用上下文信息,编码更多策略学习所需要的语义信息。大量基准实验表明,MLR 显著提高了强化学习算法的样本效率(sample efficiency),在多个连续和离散的强化学习环境中取得了 SOTA 的性能。

图1:基于掩码的隐空间重建(MLR)的框架示意图
02
基于滑动语言模型的句子评分转换器

论文链接:
https://www.microsoft.com/en-us/research/publication/transcormer-transformer-for-sentence-scoring-with-sliding-language-modeling/
句子评分旨在评估一个句子的最大似然估计,被广泛应用于许多自然语言任务的场景中,包括重排序、语言可接受性等。过去用于解决句子评分的工作主要以两种经典语言模型为主:因果语言模型(causal language modeling, CLM)和掩码语言模型(masked language modeling, MLM)。然而,这些工作都存在一定的瓶颈:CLM 虽然只需要计算一次但却只利用了单向信息;MLM 能够利用双向语义,但每次只能预测部分单词而不得不需要多次推理。
因此,微软亚洲研究院的研究员们提出了一种基于滑动语言模型的 Transformer 模型 Transcormer,并在其中设计了一种三流自注意力机制用于维护滑动语言模型。利用这样的设计,Transcormer 可以确保模型能够利用双向信息进行预测的同时,只需一次计算即可得到所有单词的概率。滑动语言模型在计算句子评分时,Transcormer 还可以避免 CLM 只能利用单向信息的缺点以及 MLM 需要多次计算的不足。实验结果表明,Transcormer 在句子评分任务上能够取得比其他方法更好的结果。
图2:Transcormer 结构示意图:左侧为前向流,右侧为后向流,中间为询问流。其中,前向流用于收集前向语义,后向流用于收集后向语义,而询问流用于捕获当前位置在其之前的前向流语义和其之后的后向流语义
03
周边视觉注意力网络
论文链接:
https://www.microsoft.com/en-us/research/publication/peripheral-vision-transformer/
人类拥有周边视觉这种特殊的视觉处理系统。具体来说,我们的整个视野可以根据到凝视中心的距离被划分为多个轮廓区域,而周边视觉使我们能够感知不同区域的各种视觉特征。受该生物学启发,微软亚洲研究院的研究员们开始探索在深度神经网络中模拟周边视觉进行视觉识别的方法。
研究员们所设计的 PerViT 网络,可以将轮廓区域通过位置编码结合到多头自注意力机制中,使网络掌握如何将视野划分为不同轮廓区域的方法,并能够从不同区域中提取相应的特征。研究员们系统地研究了机器感知模型的内部工作原理,发现网络学习感知视觉数据的方式与人类视觉相似。在 ImageNet-1K 上对 PerViT 网络评估的结果显示,PerViT 在不同模型大小上的图像分类性能均优于基线,证明了该方法的有效性。

图3:人类周边视觉(上)与基于注意力的神经网络(下)相结合以进行视觉识别的示意图
04
VRL3:由数据驱动的视觉深度强化学习框架
论文链接:
https://www.microsoft.com/en-us/research/publication/vrl3-a-data-driven-framework-for-visual-deep-reinforcement-learning/
在强化学习,尤其是机器人系统的训练中,新数据样本的采集往往十分昂贵。为了实现经济,高效,服务于大众的泛用性强化学习和机器人技术,研究员们尝试结合利用多种数据来源,大幅提高训练效率。研究员们设计了一个全新的数据驱动的学习框架 VRL3。VRL3 使用了三阶段的训练方式,整合了非强化学习的大规模图像数据集,有限的人类专家示范以及在线强化学习数据,并加以充分利用,其可在基于视觉输入的深度强化学习任务尤其是模拟机器人任务上,以惊人的样本效率进行学习。
相比之前的最先进方法,在极富挑战性的 Adroit 机械手基准测试中最难的任务上,VRL3 可极其显著地将样本效率提高24倍,并以10倍更快计算速度和3倍更少参数需求完成训练。在达到极高性能的同时,VRL3 追求大道至简的设计理念,用简单易懂的设计思路和代码实现。这项研究向实现高效、便携、低成本可广泛服务于大众的强化学习和机器人系统迈出了关键一步。
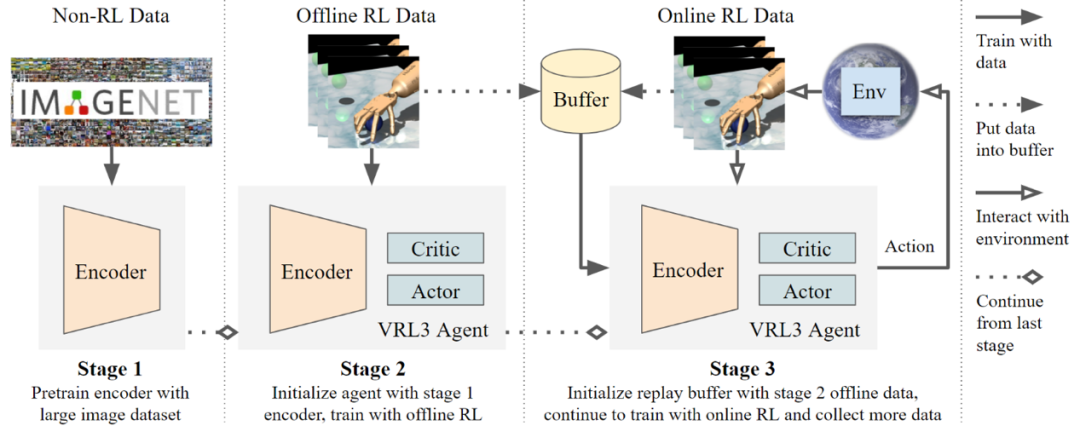
图4:VRL3 模型设计图
人工智能理论
Theory
05
组合多臂***在随机触发臂或独立臂场景下与最大触发臂数量无关的损失分析

论文链接:
https://www.microsoft.com/en-us/research/publication/batch-size-independent-regret-bounds-for-combinatorial-semi-bandits-with-probabilistically-triggered-arms-or-independent-arms/
组合多臂***(combinatorial multi-armed bandit)将传统的组合优化和在线学习相结合,通过在线反馈机制不断改进模型的优化效果。其应用涵盖推荐系统、在线广告、社交网络、无线网络等多个领域。在本文中,研究员们通过方差分析的方法降低了每个时刻可能被激活的臂数 K 对算法所承受损失的影响。
值得注意的是,研究员们找到了一种全新的光滑条件,称为概率激活方差调节(TPVM)条件。首先,TPVM 被证明和既有的光滑条件在多数实际应用场景下(如在线广告、社交网络等)同样成立。其次,通过 TPVM 条件,研究员们得以对带概率和无概率激活臂的模型分别设计基于方差分析的新型算法,即 BCUCB-T 和 SESCB。在带概率激活臂的模型下,BCUCB-T 算法可以将 K 对损失的影响从此前的 O(K) 降低为 O(log^2 K)或 O(log K)。而在无概率激活臂的模型下,SESCB 则将损失上界由此前的 O(log K)降低至 O(1)。最后,仿真实验结果表明,研究员们所提出的算法在很多实际应用场景中都能超越现有算法的效果。

图5:带概率激活臂的 CMAB 模型下本文结果与此前结果对比图
06
动量会改变优化器在可分数据上的隐式正则吗?
论文链接:
https://www.microsoft.com/en-us/research/publication/does-momentum-change-the-implicit-regularization-on-separable-data/
为提升训练速度,深度学习中的优化器广泛采用动量加速技术。然而,目前学界仍未能厘清动量是如何影响深度学习模型的泛化能力的。本文从动量加速技术的隐式正则效应切入,探究了其对泛化能力的影响。尤其是,本文证明了在对线性可分数据上,带动量的梯度下降法收敛到的点是 L^2 最大间隔问题的解 (L^2 max-margin solution),与不使用动量的梯度下降法相同。这意味着带动量的梯度下降法将收敛到一个低复杂度的模型,从而保证了模型的泛化性质。
本文更进一步分析了动量梯度下降法带随机性和带自适应学习率的变种(即随机动量梯度下降法和确定性 Adam 算法),证明了它们也会收敛到 L^2 最大间隔问题的解。这首次证明了随机动量梯度下降法在仿射噪声假设下,将收敛到驻点。这一假设相比现有研究中有界方差噪声的假设,适用范围更为广泛。与此同时,多个场景的数值实验验证了该理论结果,请查看论文原文了解更多细节。

图6:论文《动量会改变优化器在可分数据上的隐式正则吗?》的结果展示图
07
稳定的神经元响应会提升模型泛化性能
论文链接:
https://www.microsoft.com/en-us/research/publication/neuron-with-steady-response-leads-to-better-generalization/
如何提高模型的泛化性能,一直是机器学习和深度学习的核心问题之一。随着深度学习的不断发展,各种各样的网络结构被应用在多种不同的任务中。能否探寻到统摄不同任务和网格结构的本质共性来提高多种网络的泛化性能,是本文的研究切入点。
研究员们从神经元级别的细粒度出发,仔细分析了单个神经元在神经网络训练和测试中的响应特性,发现提升神经元对同类输入样本响应的稳定性能够有效地提高神经网络的泛化性能。据此,研究员们设计出了一种通用的正则项,用于控制神经元在激活状态下响应的类内方差,并进一步分析了将此正则项应用在不同层神经元所带来的效果差异。该正则项简单高效,能在不同领域的多个数据集(ImageNet, CIFAR10, PubMed, WikiCS)以及多种网络结构 (MLP, CNN, GNN)上普遍地提升模型的泛化性能。
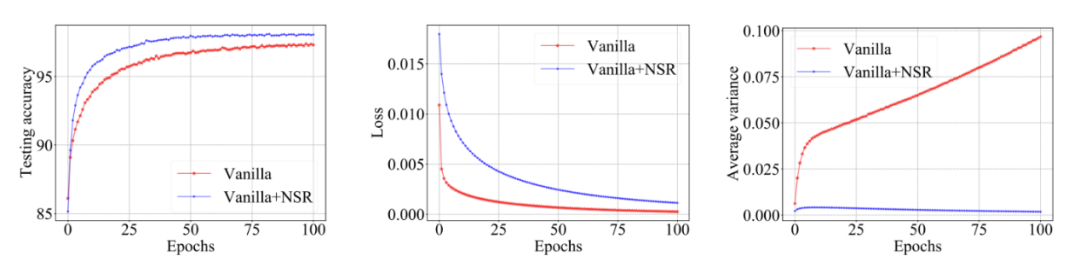
图7:MLP 模型在 MNIST 数据集上的训练过程图。其中,红线表示原始模型的训练曲线,蓝线是加入全新正则化技术后的新模型训练曲线。最右的图片显示,在原始模型中,神经元对同类样本响应的方差会随着训练不断增大,而研究员们所提出的正则化技术能够大幅降低神经元响应的类内方差。相应地,原始模型的训练损失虽然比新模型要低(见第二幅图),但新模型在测试集上的识别准确率却比原始模型有显著提高(见第一幅图),因此研究员们所提出的正则化技术有效地提高了模型的泛化性能。
08
等级强化学习:悲观面对不确定性与“常数regret”

论文链接:
https://www.microsoft.com/en-us/research/publication/tiered-reinforcement-learning-pessimism-in-the-face-of-uncertainty-and-constant-regret/
强化学习(RL)在许多用户交互型应用中都取得了成功,比如医疗领域、推荐系统等。其中,病人/客户扮演的是环境的角色,治疗方案/推荐算法则是强化学习中的决策,其具体做法就是部署决策、收集数据、并用强化学习算法提升直到接近最优。
由于训练过程中算法不可避免地会给用户提供错误的决策,但不同的用户对于承担或接收决策错误所造成的损失的能力也不同,故需具体情况具体分析。然而,现有框架忽略了决策错误对个体用户影响的特殊性。因此,研究员们提出了“等级强化学习(Tiered RL)”的新框架,其根据风险的承受能力对用户进行等级区分,承受能力越弱等级越高。
在对 gap 不做假设的情况下,研究员们证明了与 online setting 相同的 O(√(SAH^3 K)) 的极小化极大下界(minimax-lower bound),揭示了一般情形下这个问题的困难度。在引入最小 gap 假设的 gap-dependent setting 中,研究员们设计了新的算法,在保证低等级用户的“regret”仍然是最优的前提下,高等级用户承担的“regret 与交互次数 K 无关,打破了普通 online learning 的 O(log K) 下界,从而证明了新框架和算法的优越性。

图8:等级强化学习(Tiered RL)框架图
