原文链接:https://mp.weixin.qq.com/s/BJTqXZbg0y9H3WsZz1qs2g

来源:集智俱乐部
作者:丁善一
编辑:邓一雪
导语
目前在互联网的交互框架内,用户和消费者只被允许做“有限的表达”,比如被设计好的制式问题、按钮、案件、关键词命中等等,从而臆测主观诉求,然后希望可以用“猜你喜欢”的方式留住用户。如何在业务中允许用户或消费者做开放式的表达,并能够有能力结合服务者和商品进行因果表征,对因果图进行扩充,进而规模化地去应对这种开放式的表达,是当前智能服务领域面临的挑战之一。
7月2日,由零犀科技与集智俱乐部共同打造,旨在加速人工智能学界和产业界在因果科学领域融合探索的“因果派”论坛成功召开。重庆大学教授、博士生导师刘礼教授围绕栩栩如生的例子介绍了人工智能的进展、与大数据的关系以及目前存在的问题,对如何更好的从因果的角度理解和解决实践应用中出现的问题尝试进行解答。
1. “浅入深出”介绍因果
辛普森悖论有一个典型的例子,实验者观察肾病患者的服药情况,发现分男女组别考察,服药男性和女性的治愈率都分别高于不服药的患者,从而能够得出”服药有助于恢复”的结论。但从整体样本考察,会发现不服药的治愈率83%高于服药的治愈率78%。
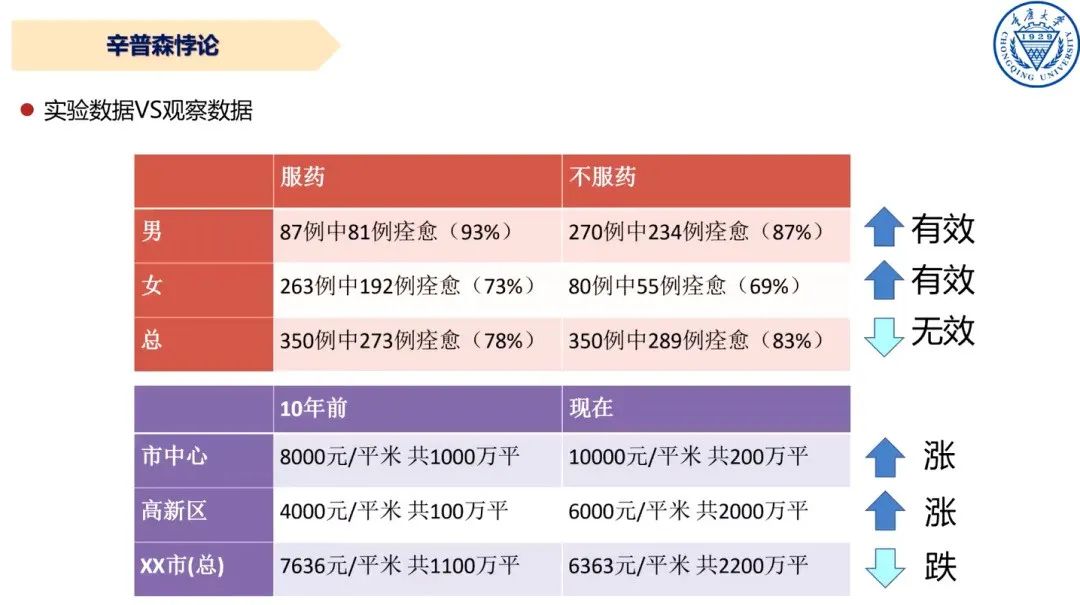
图1 辛普森悖论
另外一个辛普森悖论的例子关于房价。对比某城市10年前和现在的房价,市中心和高新区的房价分别都涨了。但从整体上看,现在的房价反而跌了。
辛普森悖论虽然不是新提出的,但却是各领域不可忽视“顽疾”。在上个世纪90年代,人工智能方法大多是专家系统,它是基于逻辑、符号或人类知识规则的一套推理方法。在2017年Alpha Go打败人类之后,人工智能的方法则几乎完全倒向了基于数据驱动的机器学习方法,并且迎来了更广泛的应用,比如语音识别、翻译和人脸识别等。在很多场景下会有比较明显的效果,但同时面临着产品实现的效果严重依赖于数据的数量和质量的问题。
这种分组和整体结论不同的情况,也是机器学习模型的困境。例如训练数据和测试数据不满足独立同分布假设(Independent and Identically Distributed, I.I.D),那么机器学习在分布偏移情况下很难鲁棒地学习,在新的场景中很难使用现有的模型。
为了进一步理解,I.I.D.带来的问题,让我们考虑下面的例子。Alice想在网上买一个笔记本电脑包,网上商店的推荐系统于是向Alice推荐了笔记本电脑。这个推荐看起来很不合理,因为很可能Alice是已经买了电脑才去买包。假设该网站推荐系统使用统计模型仅仅基于统计相关性来推荐,那么我们已知事件“Alice买了包”对于事件“Alice是否会买电脑”的不确定性减少,和已知事件“Alice买了电脑”对于事件“Alice是否会买包”的不确定性减少是相等的,都为两个随机事件的互信息。这就导致我们丢失了重要的方向信息,即买电脑往往导致买包。
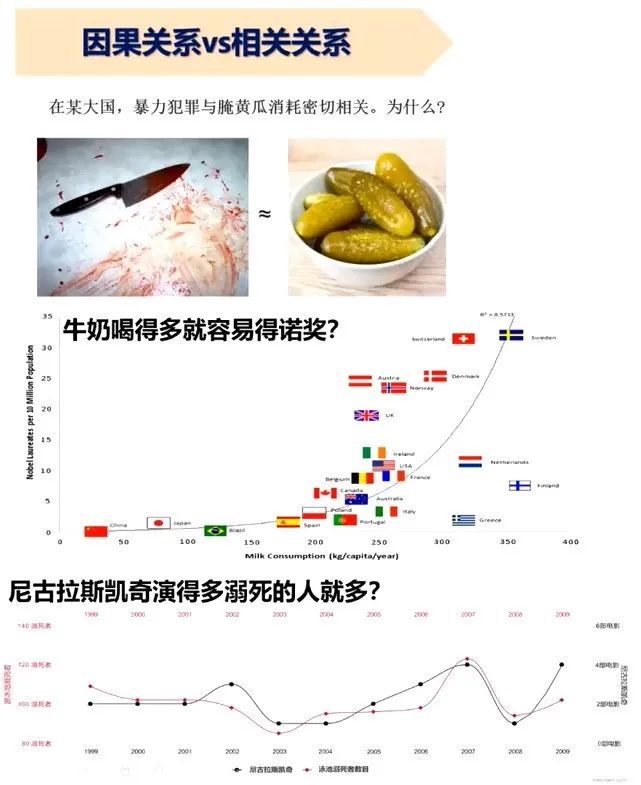
图2 因果关系vs相关关系
实际上,目前基于数据驱动的机器学习方法训练出的模型所得出的结论,大多是变量和变量之间的相关关系而不是因果关系。例如,之前有项研究发现在某大国暴力犯罪与腌黄瓜消耗密切相关。也有人发现,牛奶喝得越多的国家,其获诺贝尔奖的数量就越多。甚至还有人发现,尼古拉斯·凯奇每年演的电影数量和每年美国溺亡人数的曲线吻合。但以上的种种相关性并不代表因果性。
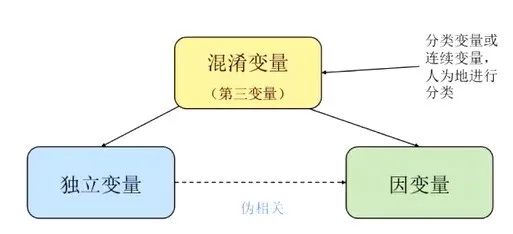
图3 混淆变量
从因果的角度,辨析以上所述的几个问题需要考虑混淆变量。混淆变量会同时影响独立变量和因果变量,从而造成两者之间的伪相关。如果将传统统计和因果推断进行对比,有以下几个特点:

图4 传统统计和因果推断
深入思考,其实西方科学的发展史就是因果问题,这套真理体系、推理体系我们从小就在学习:已知1+1=2,1+2=3,可以推导得出1+1+1=3。当然,这套体系也有可能出错,例如牛顿定律在地球上适用,但在宇宙中就失效,从而爱因斯坦提出了相对论。所以存在因果性,则一定存在相关性,但反之不一定成立。
2. 数据驱动迈向可解释性
主流数据驱动的机器学习已经非常成功,无论是阿法狗,还是GPT都带来了惊艳的效果。但有两个缺点:没有可解释性、可控性差。
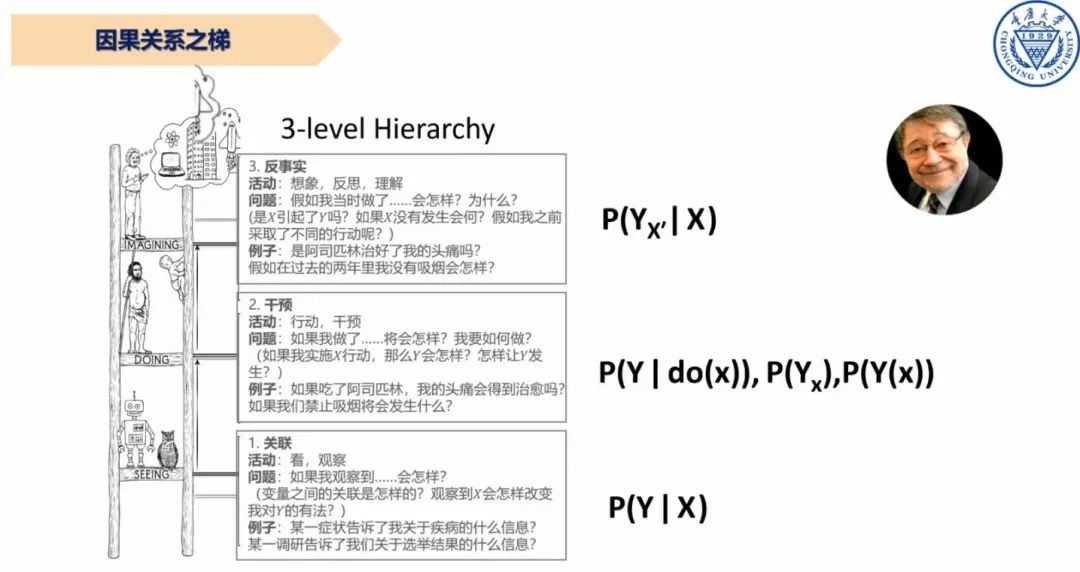
图5 因果关系之梯
为了解决上述问题,图灵奖获得者朱迪亚·珀尔提出因果关系之梯。如上图,第一层次是关联,通过概率表达描述出观察到的一堆数据。第二层次是干预,不仅是观察,而且是进行实验改变,例如如果吃了阿司匹林,我的头痛会得到治愈吗?如果我们禁止吸烟将会发生什么?其中,吃药和禁止吸烟都是干预手段。第三层次是反事实,在既定结果已经发生的情况,假设当初采取另一方案,则会发生什么。反事实不会得到观察数据,毕竟不存在两个平行世界,但确实经常遇到的情况,经典的就是人们常说的“如若当初........就不会......”。

图6 反事实问题
反事实问题目前非常难解决,也有很多例子。黑人被警察控制事件,反事实下,就对应:如若白人被警察控制了,会发生什么?在影视剧中,也常发出如若是另外某个明星参演,票房会有什么变化。这些反事实问题没办法验证,但需要回答。
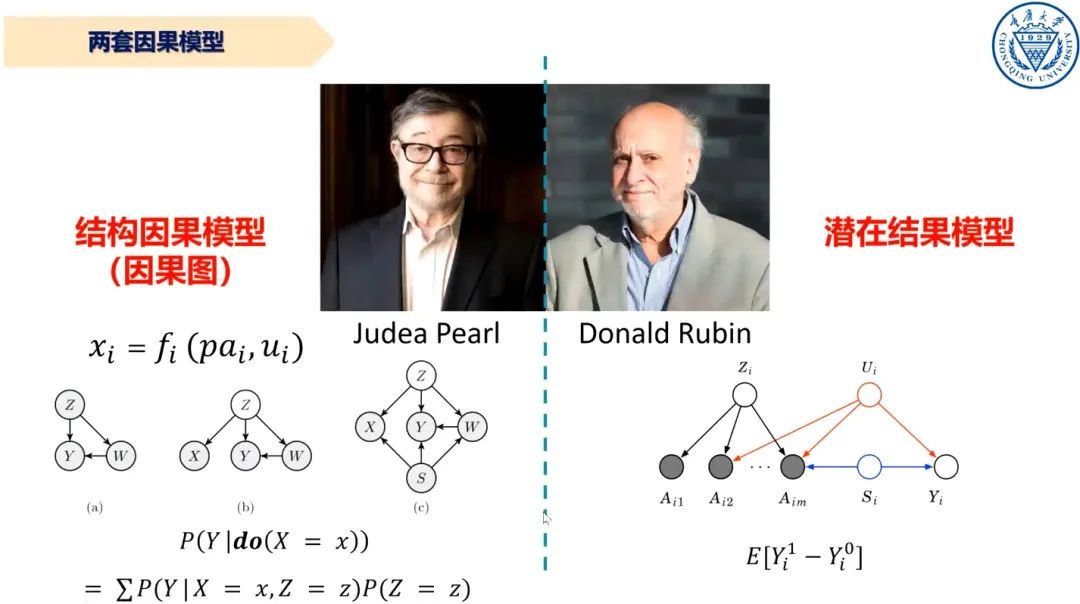
图7 两套因果模型
针对此问题,目前有两套主要的因果模型:珀尔的结构因果模型;罗宾的潜在结果模型。两者都可以预测、干预以及回答反事实问题,对于“发现定理知识”目前还不确定是否可行。潜在结果模型可以从数据中学习,但与现有知识相结合比较困难。而结构因果模型则相反,可以结合现有知识,但从数据中学习的能力还亟待进一步检验。在工业界当中哪一套体系更好,需要具体问题具体分析,和进一步的探讨。
目前,因果范式有几个问题正在解决:因果发现、因果推理。
因果发现需要基于已有的数据找出变量和变量之间的因果关系。除了基于约束和基于评分规则的方法之外,还有因果表征。
表征学习是机器学习中的重要问题,联合好的表征是机器学习算法成功的重要条件,因为统计学习模型需要I.I.D.假设,若测试数据与训练数据来自不同的分布,统计学习模型往往会出错。然而在很多情况下,I.I.D.的假设是不成立的,而因果推断所研究的正是这样的情形:如何学习一个可以在不同分布下工作、蕴含因果机制的因果模型(Causal Model),并使用因果模型进行干预或反事实推断。
在因果推理层面,珀尔提出了Do算子,在因果图上给出了一系列定理和假设,用传统的概率表达形式进行操作,这就让“因果”变得可计算。除此之外,还有反事实计算框架、因果效应评估等等。
3. 因果框架符合现实假设
在将因果理论落地的工作中,在可控图像生成方面,目前的图像自动生成很多都是以条件为主的,例如给定标签的控制、图像的控制、文字的控制。与当前基于条件的生成方法不同,我们研究出三种类型的方法:基于已有观察数据、基于潜在变量数据、基于因果干预变量数据。其中,因果干预图像合成方法是对相应的变量进行解耦,观察变量变化如何导致结果变化,从而精准控制图像的某一部分合成。
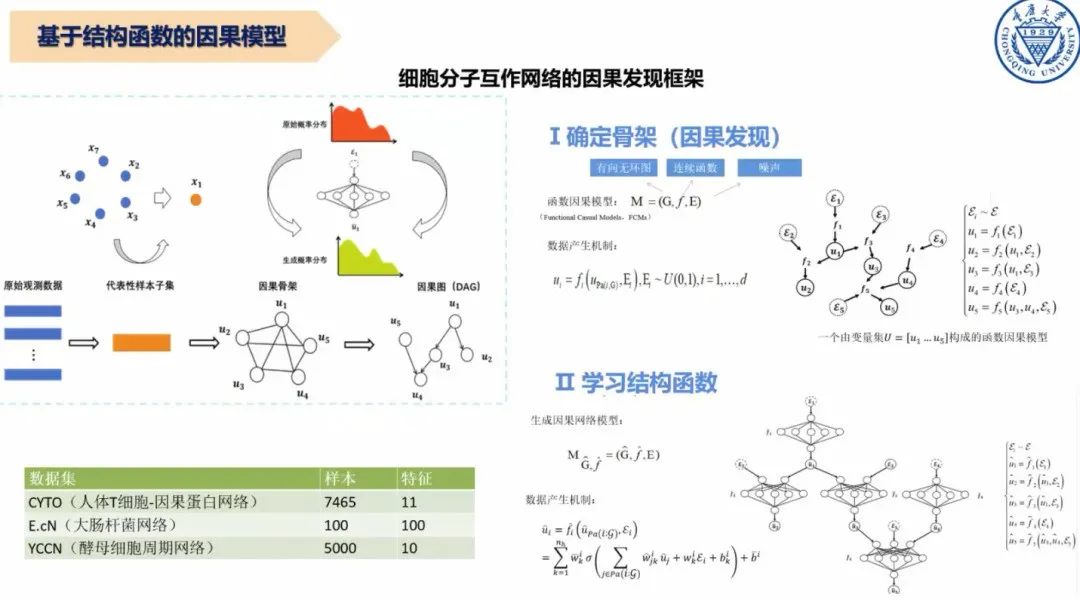
图8 基于结构函数的因果模型
此外,因果方法在医疗领域有很多应用。特别在疾病归因分析与预测方面,我们基于结构函数的因果模型设计了因果发现框架,通过超越分子与分子之间的关联性来发现其因果性。具体操作分成两步:第一步发现变量和变量之间,包括潜变量之间的因果图;第二步基于因果图,确定明确的结构函数关系。
在最具代表性的肿瘤特征选择课题上,我们还开发出基于贝叶斯图学习因果模型,超越了传统学习函数步骤,使用因果图进行描述关系。
在人体行为识别方面,我们还认为当前的识别手段多是采用传感器和视频流的方式进行,会有前后的因果关系。因此,可以用格兰杰因果方法解决时序因果中的问题。
因果学习作为人工智能领域研究热点之一,它更注重支持干预、规划、推理的模型,其研究进展与成果也引发了众多关注,将因果与深度学习结合很可能是通往多用途AI的必经之路。
