原文链接:https://mp.weixin.qq.com/s/ik59zP8ViMOvJmaPPXVlKw
这篇文章主要是Probabilistic Rule Learning Systems: A Survey这一文章的翻译以及Reasoning with Transformer-based Models:Deep Learning, but Shallow Reasoning一文中的部分内容。以及自己的一些理解。首先会对规则学习简单的进行介绍,对现有方法进行分类。然后从例子出发具体介绍规则学习的基础概念以及各类方法。最后第二篇文章中有一些其他reasoning的例子,以及使用transformer做reasoning的工作目前的进展。
目 录
Probabilistic Rule Learning Systems: A Survey
Introduction
Example Scenario
Generic Rule Learning Process
Probabilistic rule learning systems
AlepH:A Learning Engine for Proposing Hypotheses
Neural LP
LIME-Aleph:
System Architectures
Symbolic Systems
Sub-symbolic Systems
Hybrid Systems
Discussion
Reasoning with Transformer-based Models: Deep Learning, but Shallow Reasoning
Types of Reasoning with Transformer-based Models
Discussion and Conclusion
Introduction
符号学习与神经网络一直以来都有着密切的联系。近年来,符号学习方法因其可理解性和可解释性引起了人们的广泛关注。这些方法也被称为归纳逻辑规划(Inductive Logic Programming ILP),可以用来从观察到的例子和背景知识中学习规则。学习到的规则可以用来预测未知的例子。观察到的例子代表了手头问题的相关事实,并为学习过程提供了证据。然而,在ILP中,所有这些信息都是确定的; 这意味着我们不能表示不确定信息。概率逻辑规划(Probabilistic Logic Programming (PLP))被提出来表示逻辑规划过程中的不确定性信息。二者结合又产生了概率归纳逻辑规划这一研究领域(Probabilistic Inductive Logic Programming (PILP)),也被称为统计关系学习(Statistical Relational Learning)。它可以以概率信息(例子和背景知识)为输入,以概率为输出归纳出规则。在PILP中可以执行两种类型的学习任务:参数学习和结构学习。参数学习是学习已有规则的概率,而结构学习是学习规则的整个结构及其概率。这个综述关注结构学习,因为它包含了参数学习。
Example Scenario
这一节使用一个天气领域的简单场景来说明不同规则学习系统的特性。这个场景中,基于天气状况,我们会对某天是否完比赛进行预测(二元分类); 预测结果将是那天的比赛或不比赛(Y/N)。天气预报是根据以下天气资料(属性)作出的:
Outlook:此属性提供有关当天的outlook的信息。此属性的值可以是晴天、阴天或雨天。
windy:这个属性表示某一天是否有风。该属性的值可以为true或false。
Temp:此属性表示一天的温度。该属性的值为整数。
Humidity:该属性表示一天的湿度。此属性的值为正整数。
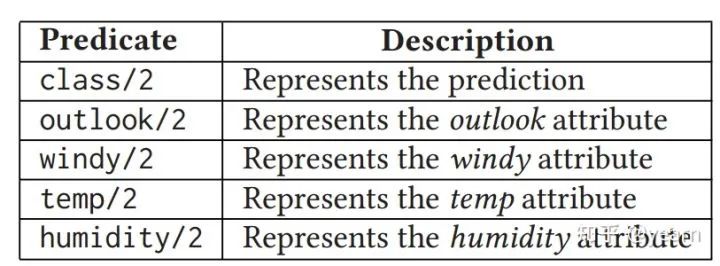
下面是一个特定日期的数据示例:天数:d1,Outlook:晴天,Temp:75,Humidity:70,windy:True,预测: Y。这个例子告诉我们,在第1天,对于给定的属性值,预测是可行的。我们使用一个谓词来表示实例,使用四个谓词来指定属性及其值,如下表所示。所有这些谓词都有两个参数:第一个参数指定日期,第二个参数指定属性值或预测值。如果我们考虑前面的例子实例,那么我们得到以下谓词:outlook(d1, sunny), temp(d1, 75),湿度(d1, 70), windy(d1, true),和class(d1, play)。那么接下来,我们要将这些谓词转化为规则。
这些规则也将是后续算法的核心,通常情况下,规则具有如下形式其中 logical literal 组成了规则的头部,一组logical literals 组成了规则的body。这里引入一个新的概念,原子(atom),一个谓词加上他的参数合起来被称为原子,比如 class(d1,play),每个参数被称为一个term,比如 d1, play。如果规则体为空(n=0),则该规则被视为一个事实。下面的规则代表了前面的示例:

在这个规则中,所有字面值的所有参数都是常量。然而,通常在学习规则时,我们会尽量学习比较general的规则。如果我们想表达一个更普遍的规则,我们可以应用到一天的任何实例,那么我们可以使用变量而不是常量。PLP用概率来表示信息的不确定性。不同的PLP系统以不同的方式表示事实或规则相关的概率。
Generic Rule Learning Process
规则学习系统使用不同的方法来构建规则。然而,当我们仔细观察这些系统并比较它们的算法时,我们可以观察到学习规则的一个共同过程。

作为一个起点,所有的系统都需要背景知识和一组实例。背景知识表示确定性信息。一个例子是表示与实例相关的数据的观察结果。这个例子可以是正面的,也可以是负面的。如果对一个实例的预测在一个场景中成立,那么这个信息被表示为一个正例子;否则,如果预测不成立,则将其表示为一个反面例子。可以看出来反例是可以认为构造的,比如上述的rule我们将其结果改为N,就是一个反例。
接下来,系统利用这些输入信息来构造规则。规则构建的方式是,它们支持尽可能多的正面例子,而不支持与背景知识相关的负面例子。一旦构建了一个规则,则根据该规则支持的正例和负例的数量计算该规则的概率。
Probabilistic rule learning systems
首先我们对方法进行简单的分类,
symbolic PILP systems:传统方法,从输入数据中归纳出规则,对noisy data非常敏感,但是训练需要的数据量少,可解释性强。
sub-symbolic systems:使用神经网络从输入数据中学习规则,需要大量数据进行训练,对noisy data不敏感,可解释性很差。
hybrid systems:二者的结合,拥有一定的解释性,又有神经网络的良好性质。
这一节介绍了三个具有代表性的概率规则学习方法,其中Aleph是symbolic PILP system,Neural LP是sub-symbolic system,LIME-Aleph是一个混合模型。由于传统方法都比较老了,这里对他们做简要介绍,主要介绍后两种方法。
AlepH:A Learning Engine for Proposing Hypotheses
AlepH是一个用Prolog编写的ILP系统,能够从正反例中学习规则。在规则学习过程中,Aleph从给定的正例列表中选择一个正例,使用程序设置中定义的信息,构造出包含所选例子的最specific的规则。之后,Aleph尝试从具体的规则中使用输入子集来找到更普遍的规则。在搜索这个更普遍的规则时,Aleph试图找到一组候选规则。对于每个候选规则,他有一个分数,这个分数是根据支持该规则的正面和负面例子的数量计算的。接下来,选择得分最高的候选规则作为一般规则。用于生成一般规则的正例将从正例列表中删除,并重复此过程,直到列表为空。
Neural LP
Neural LP是一个基于梯度编程框架的可微分系统,它支持结构学习以学习概率规则。它被设计用来学习特定的基于知识的推理任务的规则。在这个背景下,知识库是一组关系的集合,其形式为:relation(entity1, entity2),表示二进制关系。在这里,实体是一个对象的实例。学习任务涉及相同格式的查询,其中第一个参数是变量,第二个参数是常数。Neural LP试图找到满足该查询的实体。对于我们的天气示例,我们使用表单 class(A, d1)的查询来查找第一天的预测值(以变量A表示)。为此,Neural LP首先学习查询的概率规则,然后搜索那些符合查询中的第一个参数的实体,而第二个参数中的实体是固定的。然后我们根据概率规则生成每个实体的分数的并对他们排序,其中分数越高表示实体与回答查询的相关性越大。我们可以将Neural LP中的知识库视为我们在通用规则学习过程中所描述的背景知识。从逻辑的角度来看,关系可以被视为谓词(relations as predicate)。Neural LP需要三个部分来定义背景知识(知识库)
所有在学习问题中使用的实体(entity)。
所有问题域的关系(relation)。
所有已知的事实。每个事实记作一个三元组(entity1 predicate entity)。
又回到天气的例子,属性值(例如,sunny和rain)和预测值(play和not_play)即entity。表1中的谓词名称即relation。
LIME-Aleph:
LIME-Aleph系统与到目前为止讨论的系统不同,它不直接学习规则。该系统用于解释一个实例的预测,因此它学习规则并使用它们来解释。这就是为什么我们把LIME-Aleph系统看作是一个规则学习系统。这个系统的实现目前还不公开。
LIME-Aleph假设我们有表格格式的示例数据,可以将这些数据提供给分类器(实际上是任何形式的分类器)。表中的每一列代表一个属性,每一行代表特定实例的数据。在训练了分类器之后,可以使用它对实例进行预测。接下来,分类模型、示例实例和许多k个属性被发送到LIME(Local Interpretable Model-Agnostic Explanations),这个模型可以通过选择一些被认为对进行预测很重要的属性来解释一个示例实例的预测。LIME返回那些被认为是进行预测时最重要的属性。对于返回的属性,LIME-Aleph提取所有可能的值,并使用这些值从包含属性之间的固定关系列表中查找关系。重要的属性及其值,以及关系及其值都表示为谓词。那些从表中的记录派生出来的谓词形成了一个实例。在此步骤中找到的示例实例将在一个正向示例列表中收集。对于重要属性之间的每个关系,通过改变属性值和翻转关系值,从实例生成受扰动的实例。一个受扰动的实例被发送到模型,模型返回一个评估值。若评价值高于某一预测值阈值,则将扰动示例加入正示例列表;否则,受扰动的示例将被添加到反示例列表中。在背景知识中加入扰动实例生成时产生的新关系。最后,将正例和负例列表发送给Aleph进行规则学习。然后使用学习到的规则来解释示例实例。
System Architectures
从架构的角度来看,我们可以区分三种类型的规则学习系统:符号系统、子符号系统和混合系统。下面,我们将概述这些不同类型系统的体系结构。
Symbolic Systems
大多数符号概率规则学习系统在问题空间中使用离散搜索来寻找期望规则。这些系统从一个规则或一组规则开始,这些规则支持与背景知识相关的示例。然后,他们使用不同的搜索技术(例如,在SLIPCOVER中的beam search)构建一个候选规则集。这些规则是在语言偏好的帮助下构建的,该语言偏好指定了要学习的规则模板。对于每个候选规则,计算一个评估值来评估该规则。例如,SLIPCOVER使用对数似然进行评估。对数似然是通过使用一种名为EMBLEM的期望最大化算法,从正例子和负例子中计算出来的。从候选规则集合中,只选择那些满足特定阈值的规则。这些被选择的规则形成了最终的一套规则,从而构建了一个理论。然后,对这最后一组规则进行参数学习,以了解它们的概率。现有的符号系统使用不同的参数学习算法。SLIPCOVER使用与EMBLEM相同的算法进行参数学习。
Sub-symbolic Systems
与符号系统一样,子符号概率规则学习系统以相同的信息作为输入,但以不同的方式执行结构学习的任务。子符号系统不依赖于符号系统用于推理的基础技术。相反,它们使用向量或矩阵(embedding)表示来指定谓词的信息。例如,Neural LP使用一个矩阵来表示二进制谓词,其中每一行和列索引都与一个实体相关联。如果与单元格的行和列对应的实体的谓词为真,则矩阵中的单元格的值为1。在向量矩阵空间中表示信息后,这些系统通常试图为每个目标谓词找到候选规则列表。候选规则的主体是通过组合不同的谓词来构造的。对于每个候选规则,这些系统使用不同的矩阵运算来执行逻辑推理。这些矩阵运算的结果矩阵形成目标谓词的表示。规则的概率是使用与目标谓词相对应的矩阵所支持的示例数来计算的。例如,如果我们有一个候选人规则包含原子h在头部和文字b1和b2组成的body,那么neural LP求b1和b2与h矩阵的矩阵乘法。如果矩阵乘法的结果支持该实例,那么选择该规则并将其添加到最终的规则列表中。
Hybrid Systems
没有标准的方法来结合符号和子符号表示法。因此,我们观察到研究人员一直在使用不同的技术来集成这些表示,而且这些系统大多数是领域特定的。只要系统共同使用符号和子符号两种表示,我们就认为一个系统是一个混合的系统。在下文中,我们将讨论三种混合系统:LIME-Aleph、DeepProbLog和NLProlog,它们基于不同的体系结构,用于表示组件中的信息和组件之间的通信。这些系统分别在符号分量和子符号分量中使用Horn clauses和向量表示LIME-Aleph结合了符号表示和子符号表示作为两个主要组件,并通过控制器进行通信。子符号组件执行预测任务。为了解释这一预测,符号组件的任务就是从正面和负面的例子中学习规则。控制器通过修改通过算法选择的有影响的属性,从原始示例实例生成这些示例。为了决定哪个修改的例子是正的还是负的,控制器依赖于子符号组件。DeepProbLog学习单个任务,并集成符号和子符号表示。它引入了神经谓词,应用子符号方法对预测任务的概率进行预测。在DeepProbLog中,一个学习任务由几个子任务组成。其中一些子任务可能需要进行预测,并在神经谓词的帮助下进行表示。系统的符号组成部分代表学习任务的程序,因此它可以使用所需的背景知识。当系统评估程序时,一般谓词的概率是由给定的数据计算出来的,而神经谓词的概率来自于系统的子符号组件,并被合并到符号组件中。NLProlog是一个混合系统,专门为需要多跳推理的自然语言处理任务而设计。该系统将自然语言语句转换为由两个实体(例如,Socrates和Athens)和一个文本模式(例如,ENT1 was born in ENT2)组成的三元组,该文本模式将这些实体连接到一个语句中。这样的三元组在系统中被视为一个事实。系统的编码器组件将事实、查询和许多规则模板作为输入,并使用子符号方法来查找实体或文本表面模式之间的相似性得分。系统的目标是学习回答查询的规则。系统为此使用了一个验证器组件,该组件将编码器计算的相似性分数作为输入,包括事实、查询和规则模板。证明者利用具有弱统一的逆向链的符号推理找出查询的证明,并根据相似度分数计算统一分数。证明者找到的每个证明都将从统一分数的集合中分配一个证明分数。分数最高的证明被选择作为构造已学习规则的查询的答案。
Discussion
这一节提出了一些目前还稍微解决的问题和有前景的方向
sub-symbolic systems在处理大型和嘈杂的数据集方面效率很高,但是目前只能需要chain-rule,如何学习复杂的规则是一个问题。
学习概率规则的速度往往很慢,提速是一个发展方向。
为结构学习构建混合系统。尽管混合系统结合了符号和子符号表示法,但它们并不是协作学习单一的表示法。到目前为止,DeepProbLog是唯一一个真正为单个任务集成符号和子符号表示的系统。在DeepProbLog中,学习问题的子任务是通过子符号表示来完成的,然后使用子任务的结果在符号层面上完成任务。
Data efficient learning。一般来说,符号系统从少量的数据中学习规则,而子符号系统则需要大量的数据。然而,与符号系统相比,子符号系统可以有效地处理大的和有噪声的数据。在符号系统中可以引入有效的数据处理技术,在子符号系统中可以使用从少量数据中学习的技术
Reasoning with Transformer-based Models: Deep Learning, but Shallow Reasoning一文中对使用transformer进行reasoning进行了综述,这部分内容比较新,也很有意思。
Reasoning with Transformer-based Models: Deep Learning, but Shallow Reasoning
Types of Reasoning with Transformer-based Models
Horn Rule Reasoning:从下面这个例子中可以比较容易地看出这个任务需要做什么,给定一堆fact和一个question,从中推测结果。在本任务中,最佳模型T5-11B在校对和回答问题方面的准确率达到95%以上。因此,基于transformer的模型可以近乎完美地解决这个问题
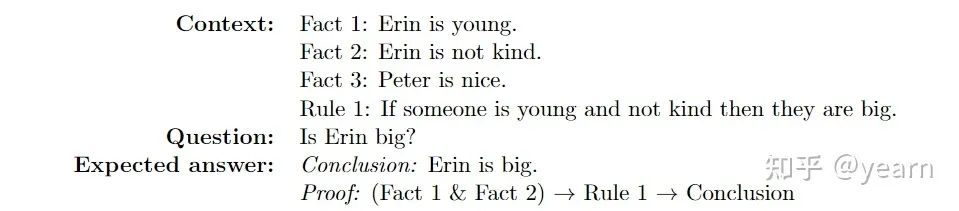
Commonsense Reasoning:常识推理是任何需要人类通常拥有的背景知识的推理任务。例如,指令“an you do a Napoleon for the camera?”需要常识推理才能意识到拿破仑这个词表示的是一种特定的姿势。一些研究表明,BERT在训练前学习了一定数量的常识知识。考虑下面这个例子,模型(预先训练的BERT-large)能够回忆这些常识知识。
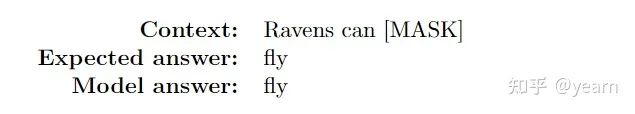
但是部分研究发现预训练的模型并不是真正的在做reasoning,因为对输入做微小的改变,模型的输出可能就发生了巨大的变化。比如在判断句子是否连贯的任务中

但是仅仅修改几个字之后,他的结果就会改变[1]

Implicit Reasoning:隐式推理任务,上述的任务不同,其中规则和事实没有明确给出。这些任务中的许多都可以通过基于transformer的模型来解决。下面是一个来自SNLI[2]数据集的例子

在本任务中,使用few-shot learnng的方法训练的RoBERTa-large模型[3]达到了93.1的精度。然而,这些数据集包含了模型可以利用的表面线索。为了充分评估模型的reasoning 能力,研究人员设计了几个更具挑战性的逻辑推理任务,这些任务大多以机器阅读理解的形式出现。例如,LogiQA [4]是从中国国家公****中翻译出来的多选题数据集

好的语言模型是经过训练的RoBERTa模型,在训练集上进行了调整,其准确性为35.31%(而人类的最佳表现为96%)。这表明,基于transformer的模型目前无法构建较长的文本的表示,并从中得出逻辑结论。这个弱点可以通过在RoBERTa之上添加符号表示[5](比如基于图形的模块)或者逻辑信息[6]来在一定程度上得到弥补。也有工作人员开发神经符号方法,通过基于梯度的优化来推理策略[7],或将概率逻辑编程与神经网络相结合[8]。将逻辑信息整合到RoBERTa中,使ReClor在简单问题上的表现提高到81.4%。然而,这些数据集更困难的问题会导致50%-60%的性能。
Discussion and Conclusion
在所有这些推理任务中,基于transformer的模型很少能达到人类的表现。这并不奇怪,因为它们是主要从训练数据中获取信息的通用工具,缺乏通常认为这类任务必不可少的任何符号机制。在不同的推理任务中,我们发现当基于transformer的模型被明确地给出进行演绎推理所需的所有信息时,例如事实和规则,模型可以很容易地学习逻辑推理。然而,当这些信息只是在文本中或在监督任务中隐含时,模型就会遇到困难。基于transformer的模型具有一定程度的预训练学习的常识性知识。然而,它们很容易被对抗性的常识性实例打断。它们在对事件的逻辑推理和物理常识方面也有局限性。
因此,我们看到基于transformer的模型的推理能力来自两个组成部分:训练数据中的简单模式,结合训练前的背景知识。这种组合使得模型能够很好地执行任务,比如Horn Rule Reasoning(模型从训练数据中学习到一种模式),简单的常识推理(从pretrain中学习到答案),以及简单的数学计算(模型在训练中学习到一种模式)。目前的transformer模型并不能取得很好的结果,但是结果表明,符号知识(如数据归一化、准逻辑推理和基于图的模块)的添加和补充技术(如数据扩充、多任务学习和知识库融合)的使用可以提高性能。因此,这些工具可能是解决更困难的推理问题的关键。
最后,欢迎大家关注github,聚合了OOD,causality,robustness,optimization以及一些前沿研究方向的一些阅读笔记https://github.com/yfzhang114/Generalization-Causality
参考
1.Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark,and Hannaneh Hajishirzi. Unifiedqa: Crossing format boundaries with a single qa system.InConference on Empirical Methods in Natural Language Processing, 2020.2.Samuel R Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A largeannotated corpus for learning natural language inference. InConference on EmpiricalMethods in Natural Language Processing, 2015.3.Sinong Wang, Han Fang, Madian Khabsa, Hanzi Mao, and Hao Ma. Entailment as few-shotlearner4.Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. Logiqa:A challenge dataset for machine reading comprehension with logical reasoning.arXivpreprint arXiv:2007.08124, 2020b.5.Yinya Huang, Meng Fang, Yu Cao, Liwei Wang, and Xiaodan Liang. Dagn: Discourse-aware graph network for logical reasoning. InConference of the North American Chapterof the Association for Computational Linguistics, 2026.Logic-driven context extension and data augmentation for logicalreasoning of text.7.Learning reasoning strategies in end-to-end differentiable proving8.Deepproblog: Neural probabilistic logic programming
