原文链接:https://mbd.baidu.com/newspage/data/landingsuper?rs=3196365689&ruk=8MVN0ObRzpLf_xb_Ge1TDQ&urlext=%7B%22cuid%22%3A%22laSIulitSi0uuHiA0uvOalimSuloaHiFYu2w8YOgS8KQ0qqSB%22%7D&isBdboxFrom=1&pageType=1&sid_for_share=&sid_for_share=214160_1&context=%7B%22nid%22%3A%22news_9040588081225623458%22,%22sourceFrom%22%3A%22bjh%22%7D
AI导读
Token终于有了中文名——“词元”!国家数据局一锤定音,日均140万亿次的调用量揭示AI已从聊天工具进化成决策引擎。这是智能时代的通货,更是中国争夺科技话语权的关键落子。
内容由AI智能生成
说实话,看到"词元"这俩字的时候,我愣了一下。
Token?这玩意儿终于有中文名了???
还是国家数据局亲自给定的?
事情是这样的。2026年3月24日,国新办新闻发布会上,国家数据局局长刘烈宏说了一句话:"我国日均词元调用量已超过140万亿。"

就这么一句,安安静静地,把一场吵了好几个月的命名大战给盖棺定论了。
Token,中文名,词元。写入国家叙事。没有商量。
你跟AI聊天,不管是问它今天吃啥,还是让它写一篇论文,AI在后台处理你说的每一句话的时候,都要先把你的文字切成一小块一小块的"碎片"。这些碎片,就是Token。它是AI理解人类语言的最小单位,切分的粒度大概介于一个字和一个词之间。
你可以把它想象成AI世界的"原子"。所有的对话、创作、分析、决策......本质上都是在一个Token一个Token地运算。
所以,谁来给这个"原子"起中文名,其实是件挺大的事儿。

这场命名之争,最早是腾讯研究院的学者杨斌挑起来的。他写了一篇文章,提出Token应该翻译成"模元"。理由是,Token是模型计算的基本单元嘛,"模"字正好能概括这层意思。
结果呢。。。一石激起千层浪,但浪花的方向不太对。"模元"这个名字没怎么获得认同,反倒是把整个AI圈的翻译焦虑给点燃了。
大家突然意识到一个问题。都2026年了,中国AI产业搞得风生水起,结果连最基本的计量单位都还在用英文???这说不过去吧。
很快,"智元"这个名字杀了出来,而且来势汹汹。
背书的人一个比一个猛。新加坡国立大学校长青年教授、潞晨科技创始人尤洋半开玩笑地说,Token中文叫"智元",不知道"新智元"创始人是不是时空穿梭回来的。
原清华大学科学史系副教授胡翌霖从学术角度论证,Token是"通用智能"的概念,不是通用计算的概念,"智"比"通"更切中要害。百川智能创始人王小川更直接,四个字回应,"叫智元挺好。"
你看,学界喜欢,产业界也喜欢,按理说这事儿应该板上钉钉了吧?
嘿,国家数据局偏偏没选它。

最终的官方答案是"词元"。中国政府网转发、人民日报刊发,官方机构和官方媒体双重盖章。这个译名从此不再是学术圈的闲聊,而是正式进入了国家技术标准的话语体系。
为啥选"词元"?
说白了,技术实用主义。"词"指向语言,"元"指向基本单元,合在一起就是"语言的最小单元"。这恰恰就是Token在大模型里干的活儿。你回忆一下,计算机时代,处理信息的最小单位叫"字节"。到了AI时代,处理人类语言的最小单位叫"词元"。一脉相承,清清楚楚。
"智元"好不好听?好听。有没有哲学深度?有。但在政策传播和技术普及的层面上,"词元"的直白和准确,反而降低了普通人理解AI的门槛。当政府工作报告里提到"词元调用量"的时候,一个普通人能直觉地感受到这跟语言处理有关,而不需要先琢磨半天"智能"的哲学含义。

名字定了,咱们再来看看那个让人头皮发麻的数字。
140万亿。日均。词元调用量。
什么概念?拉一条时间线你就知道了。2024年初,中国日均Token调用量还只有1000亿。2025年底,100万亿。2026年3月,140万亿。两年时间,增长超过一千倍。
一千倍啊朋友们。。。
如果把每个词元看作AI的一次"心跳",那中国AI的心脏,现在每秒跳动超过1600万次。这个频率比人类大脑神经元放电还要高出好几个量级。曾经待在实验室里的静态展示品,已经进化成了社会基础设施级别的动态运行系统。
刘烈宏局长对这个数字的解读很有意思,他说的一句话是关键转折点:"从能对话到能决策执行的智能体。"

早期的ChatGPT类产品,本质上就是个聊天机器人,词元调用主要集中在问答交互这个表层。但现在140万亿这个数字告诉我们,AI已经深入到了决策层、执行层、生产层。
一个财务模型分析报表生成审计建议,调用数十亿词元。一个工业设计模型优化供应链生成生产方案,消耗数万亿词元。一个城市管理模型实时调度交通预测风险,处理海量词元。
词元它是智能时代生产活动的血液。
刘烈宏特别提到,今年1月底以来,有的模型企业创下了20天收入超越2025年全年总收入的纪录。
20天干了去年一整年的活儿。。。这种增速,就建立在词元计费这套新商业模式上。
互联网时代,价值的度量单位是"流量",点击量、访问量、用户数。但到了智能时代,流量太粗糙了,词元取而代之成了新的价值锚点。国家数据局给词元下的定义里有一句话说它"具有智能时代可计量、可定价、可交易的特征",是"连接技术供给与商业需求的结算单位"。

你用大模型API的时候,付的是精确到每一个词元的计算成本。你训练行业模型投入的数据,也可以被拆解成词元来评估信息密度。AI经济第一次有了类似传统制造业的成本核算体系。
词元,就是智能时代的通货。
撑起这140万亿次调用的底座,是一套正在疯狂扩张的数据基础设施。截至2025年底,全国已建成高质量数据集超过10万个,总体量超过890PB。890PB相当于中国国家图书馆数字资源总量的310倍。
高质量数据集是词元的"原材料",模型训练是词元的"生产线",API调用是词元的"消费端"。三者咬合在一起,构成了"数据供给到价值释放"的完整循环。
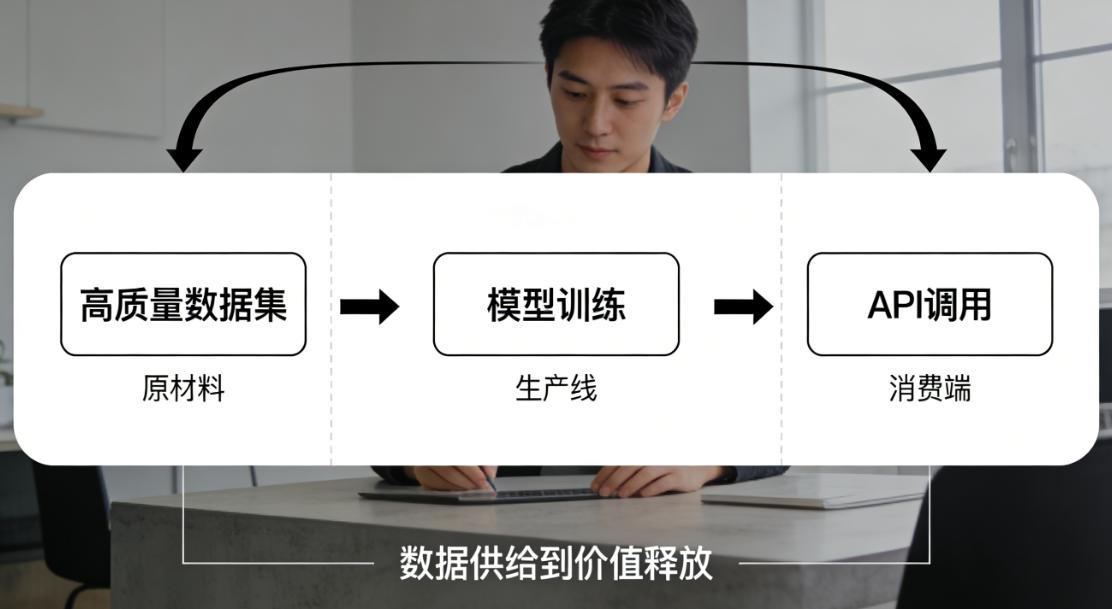
每一个词元在这个循环里流转一次,就伴随着一次价值的创造和分配。数据要素这个概念,终于不再是PPT上的抽象词汇,而是真的在转起来了。
刘烈宏在发布会上还提了一个概念。"Token出海。"
当中国的大模型API开始被海外开发者调用的时候,词元就成了中国智能产业参与全球竞争的基本计量单位。想想互联网早期,我们不得不借用Byte、Bit这些英文概念来描述数字世界。而今天,全球AI界都在讨论Token的时候,中国官方正式确立了"词元"这个中文表述。
用自己的语言定义智能时代的核心范畴。这种语言主权的确立,对于一个正在崛起的科技强国来说,其意义不亚于技术标准本身。

而且,AI治理是个全球难题,欧盟搞AI法案,美国搞算法问责制,各国都在摸索怎么监管这种全新的技术形态。一个统一、准确、官方认可的中文术语体系,恰恰是中国参与全球AI治理的前提。
以后讨论"词元安全",指的是数据在最小语义单元的加密和隐私保护。讨论"词元版权",触及的是训练数据中知识产权的细粒度界定。讨论"词元伦理",探究的是模型在每一次最小计算中的价值对齐。这些议题要展开,都得建立在"词元"这个共同认知基石上。
所以你看,一个名字的背后,藏着产业逻辑、商业模式、数据战略、国际话语权、治理框架......环环相扣。
参考信源:
[1]新华社.我国日均词元调用量超140万亿[EB/OL]. (2026-03-24).
[2]人民日报.我国日均词元调用量突破140万亿[N].人民日报, 2026-03-24(08).
[3]网易新闻.别吵了!Token中文名,官方定了![EB/OL]. (2026-03-24).
